标签:pat 元素 取值 text 节点 解决 抓取 赋值 路径
学习网站:https://www.cnblogs.com/Zfc-Cjk/p/9937269.html
学习的jmx文件:殆知阁优化.jmx 什么网站,都没听过
遇到问题:乱码问题,解决方法:https://www.cnblogs.com/shishibuwan/p/11307194.html
学习后总结思路:简而言之,对网页提交一个请求,然后把返回的所有值提取出来,利用ForEach控制器去实现遍历;
获取网址,确定网上哪些字段需要抓取;
利用foreach进行循环遍历;
最后输出到本地文件;
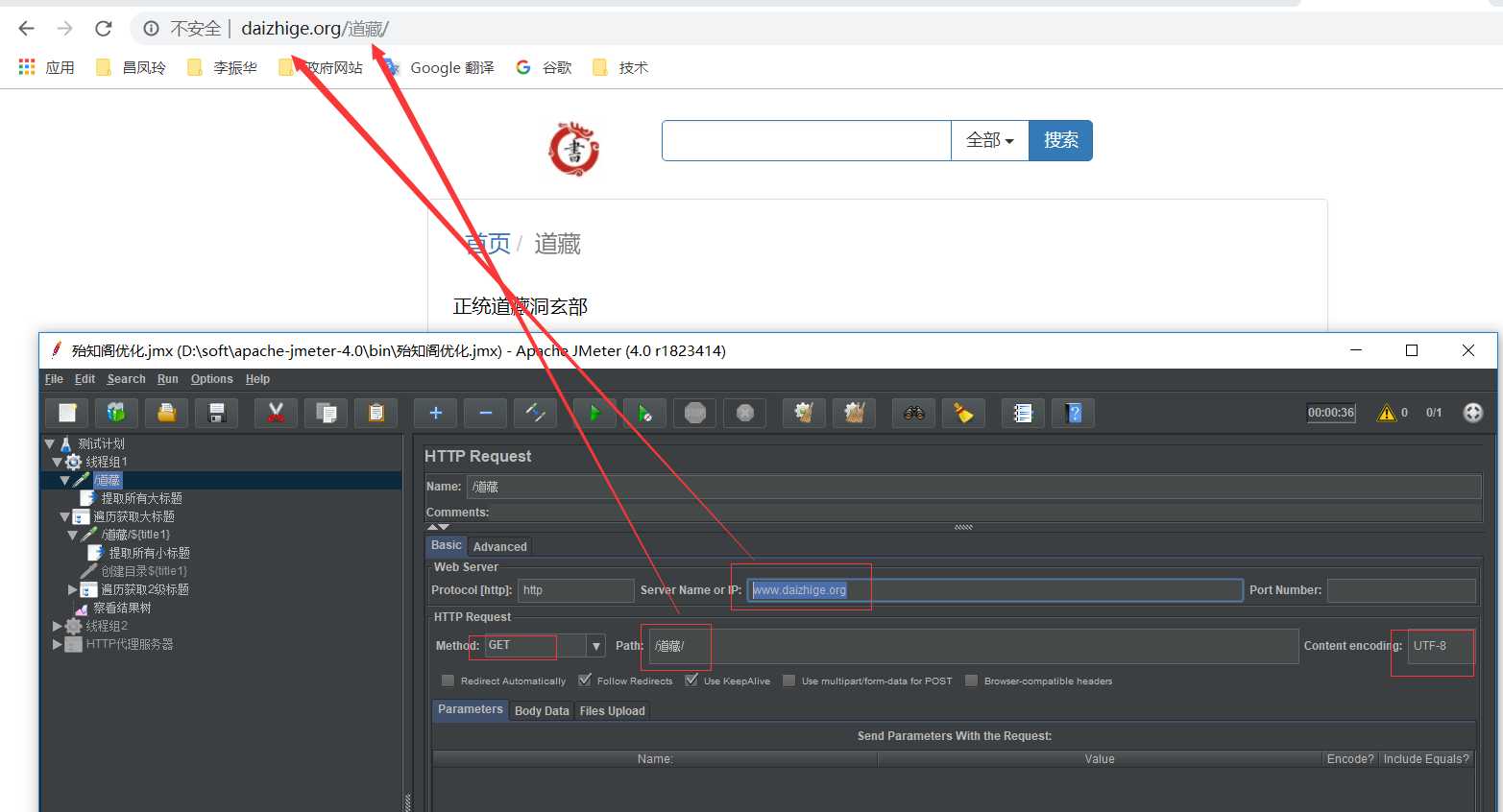
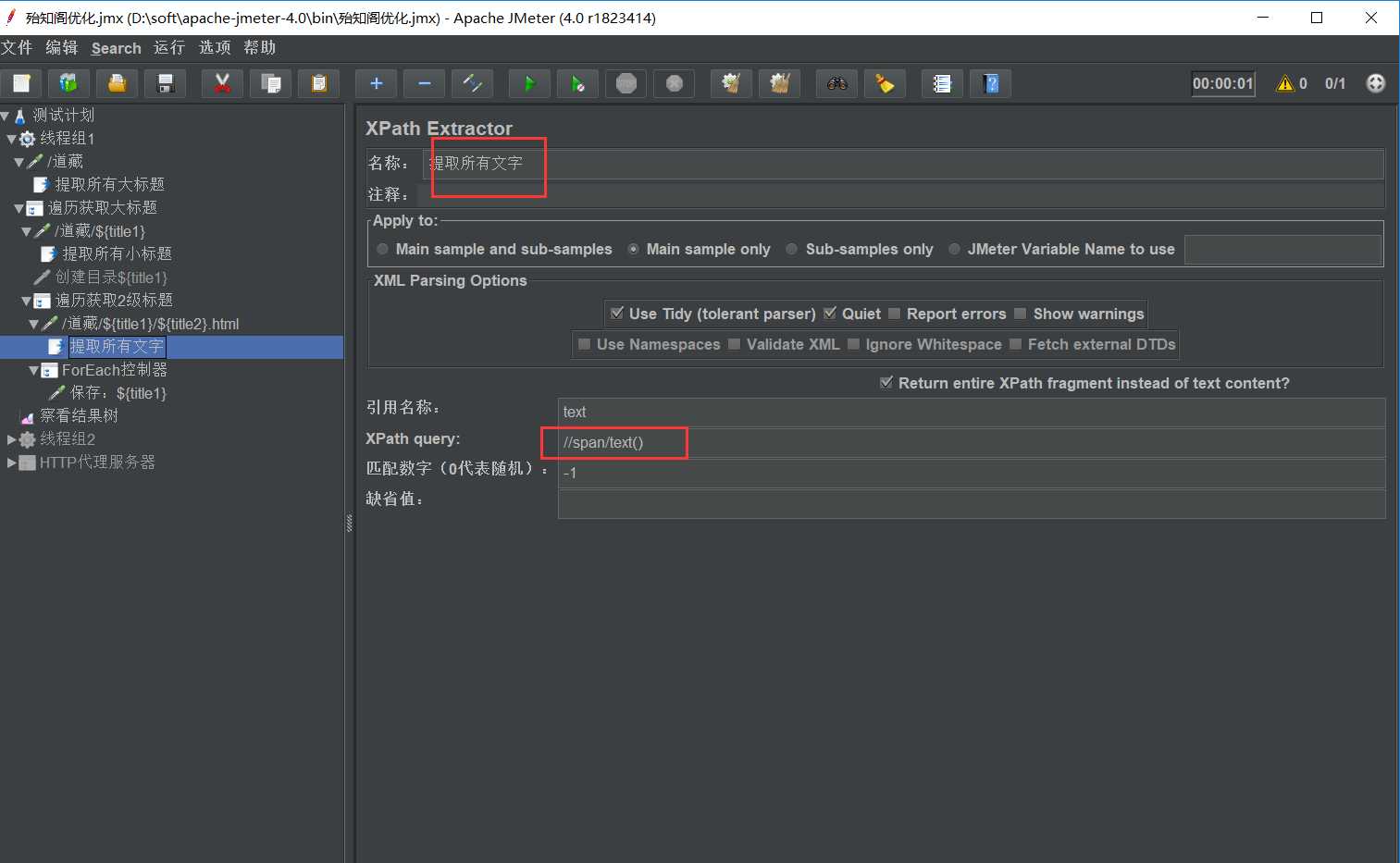
用xpath从前一个请求中取。这种形式比较适合于返回为xml片段的情况。在需要获得数据的请求上右击添加一个后置处理器-->xPath Extractor。
Xpath一般用于返回xml用得多。
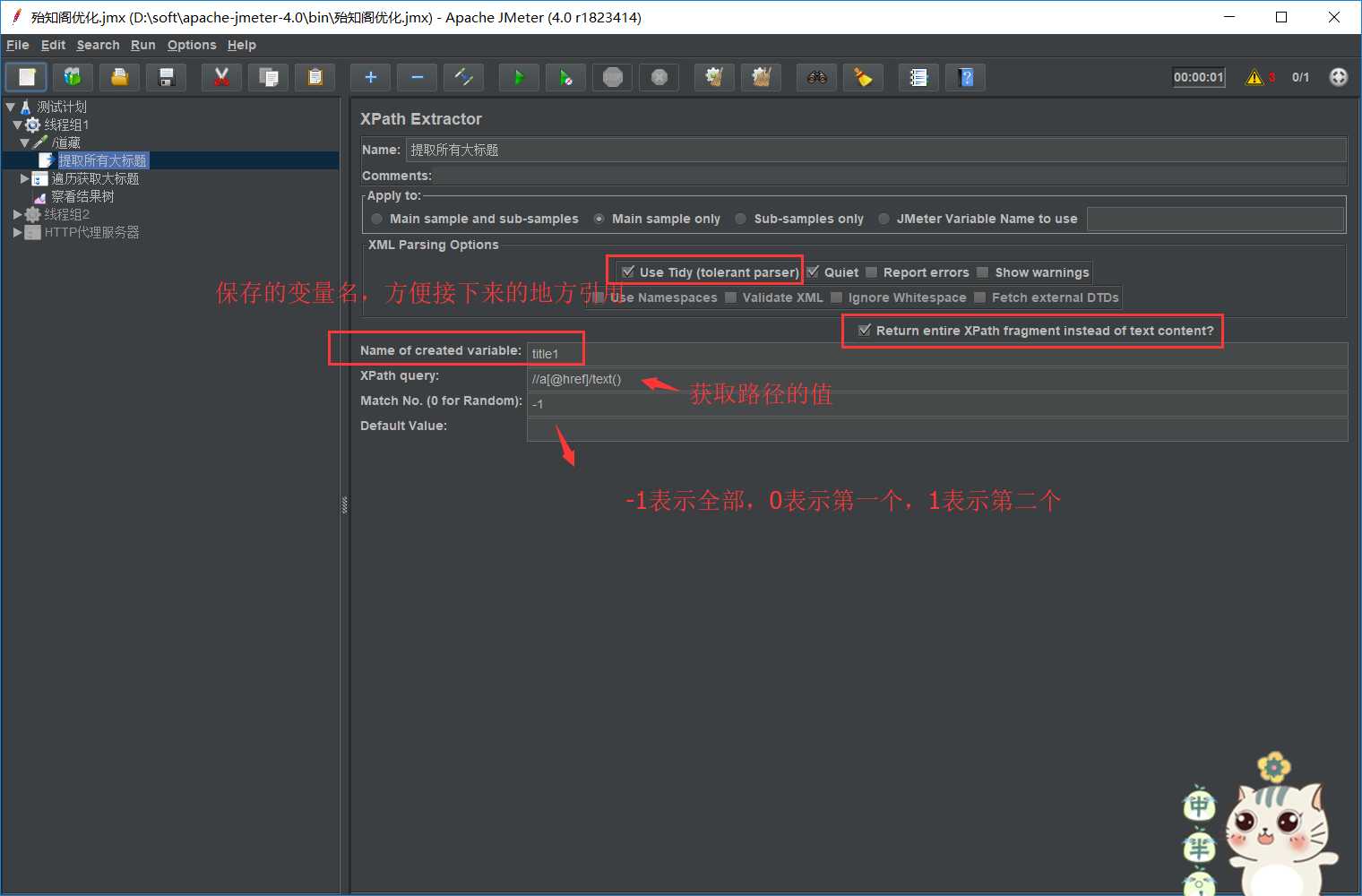
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项,当需要处理的页面是XML或XHTML格式(例如,RSS返回)时,取消选中该选项。
Reference Name:存放提取出的值的参数。
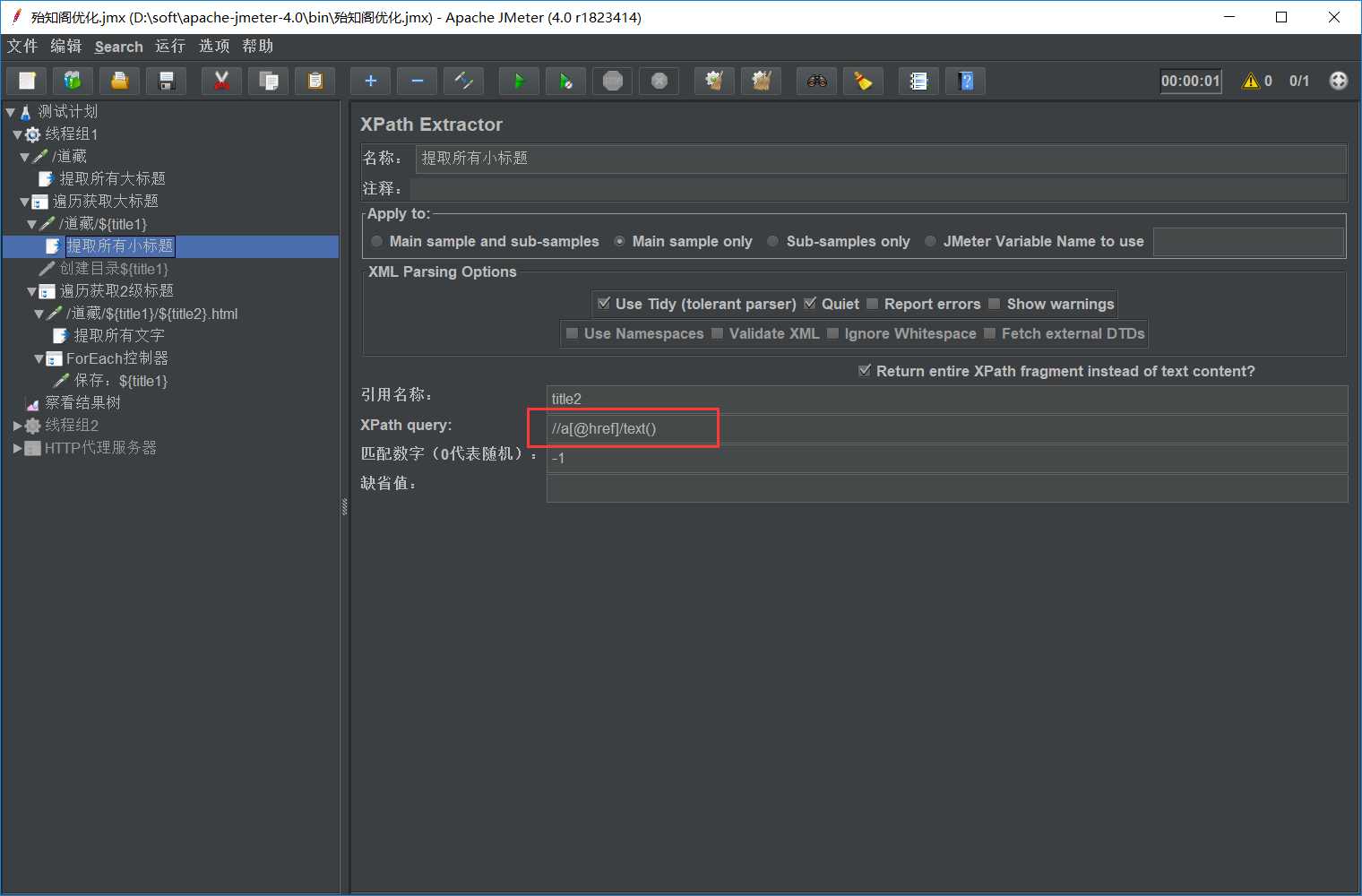
XPath Query:用于提取值的XPath表达式。
Default Value:参数的默认值。
匹配数字:0表示取第一个,1表示取第2个,-1表示取全部
XPath Extractor与正则表达式使用场景区别:
如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
而如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。
//*[@class,‘A ‘]/@href 从根目录下定位所有class=A的href
//*[@class,‘A ‘] 从根目录下定位所有class=A标签内的文本
//*[contains(@class,‘A ‘)] 从根目录下@class值中包含A的节点
substring-before(.//*[@class=‘A‘]/text(),‘0‘) 返回根目录下[@class=‘A‘]/text()中第一个‘0‘前面的部分,如果不存在‘0‘,则返回空值
substring-after(.//*[@class=‘A‘]/text(),‘0‘) 返回根目录下[@class=‘A‘]/text()中第一个‘0‘后面的部分,如果不存在‘0‘,则返回空值
详细点的请查看:
https://www.blazemeter.com/blog/using-xpath-extractor-jmeter-0/
https://www.blazemeter.com/blog/using-xpath-extractor-jmeter-0/
.//a[@class=‘linkto‘]/@href 意思就是通过a>class>href这三层标签进行逐级检索,找到class=linkto标签下的所有href,进行匹配
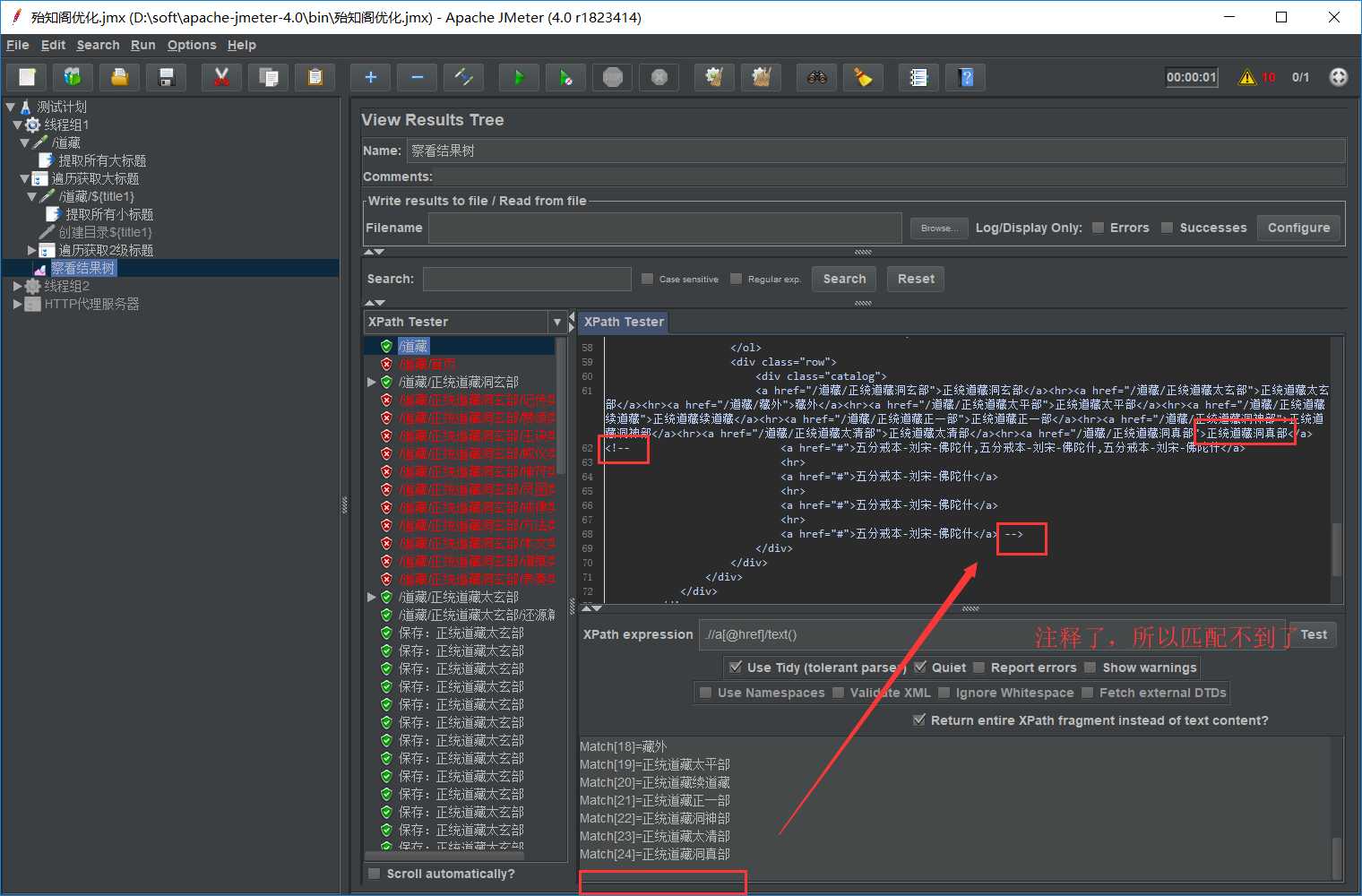
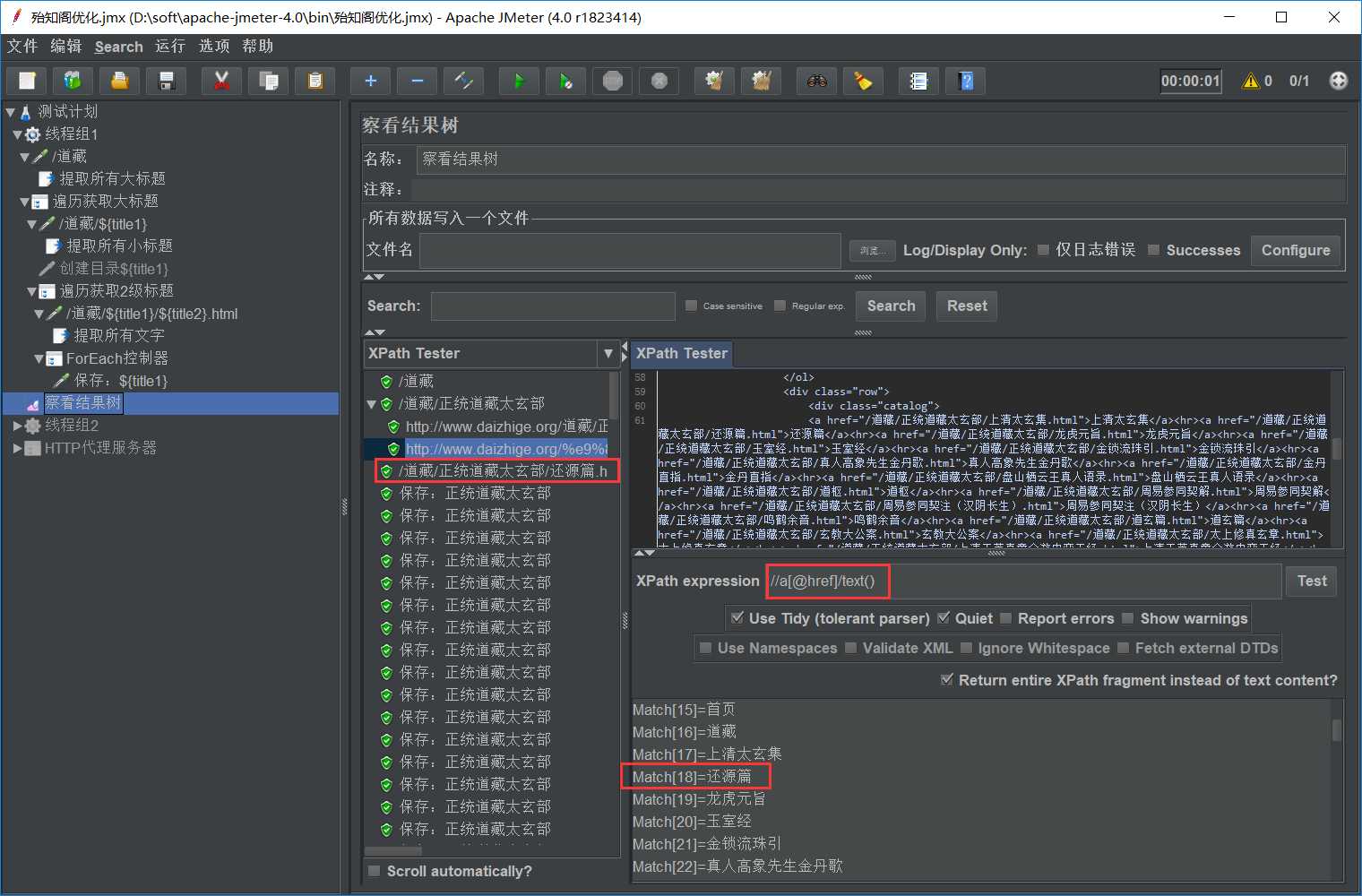
//a[@href]/text()提取的结果
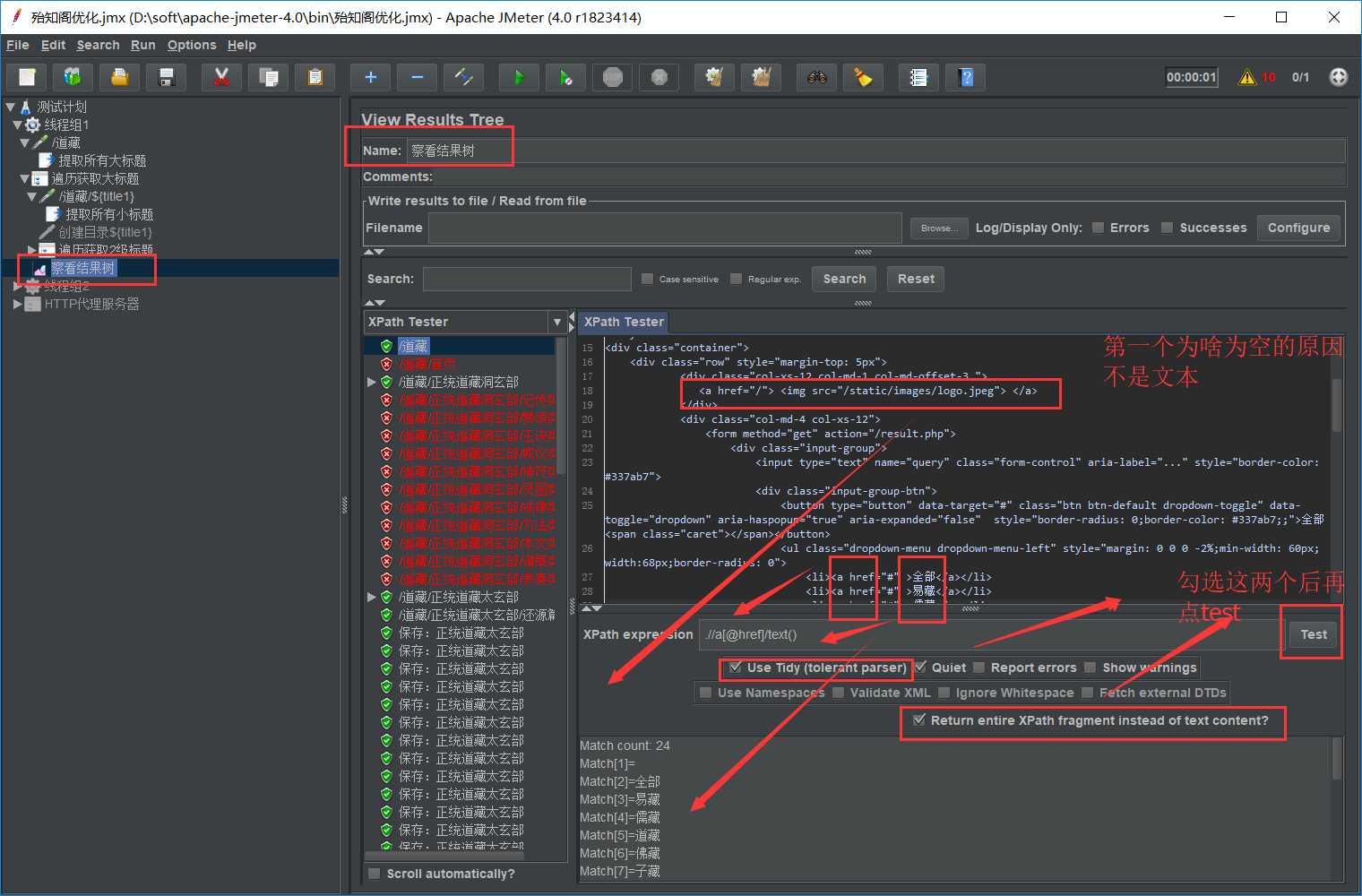
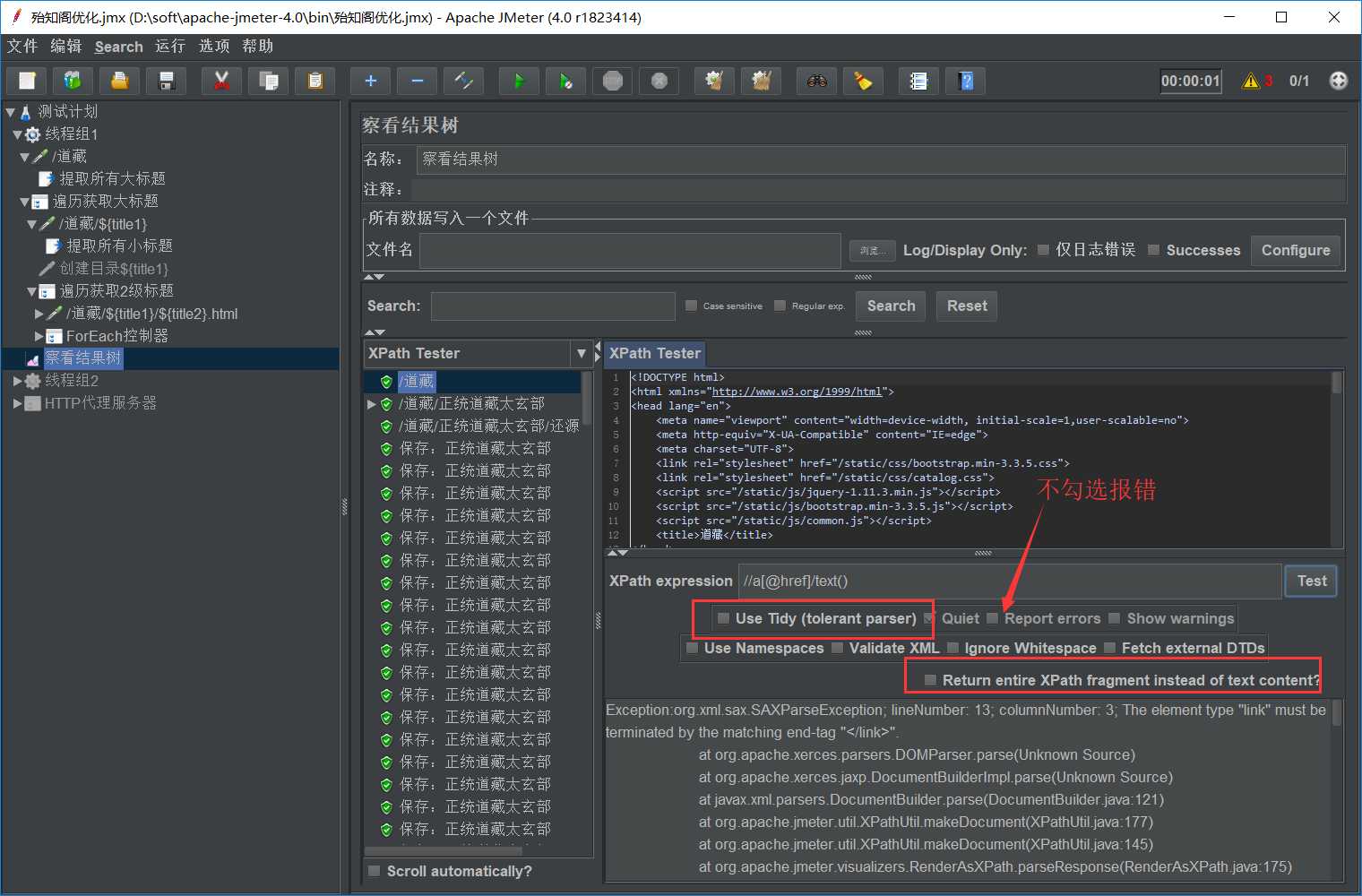
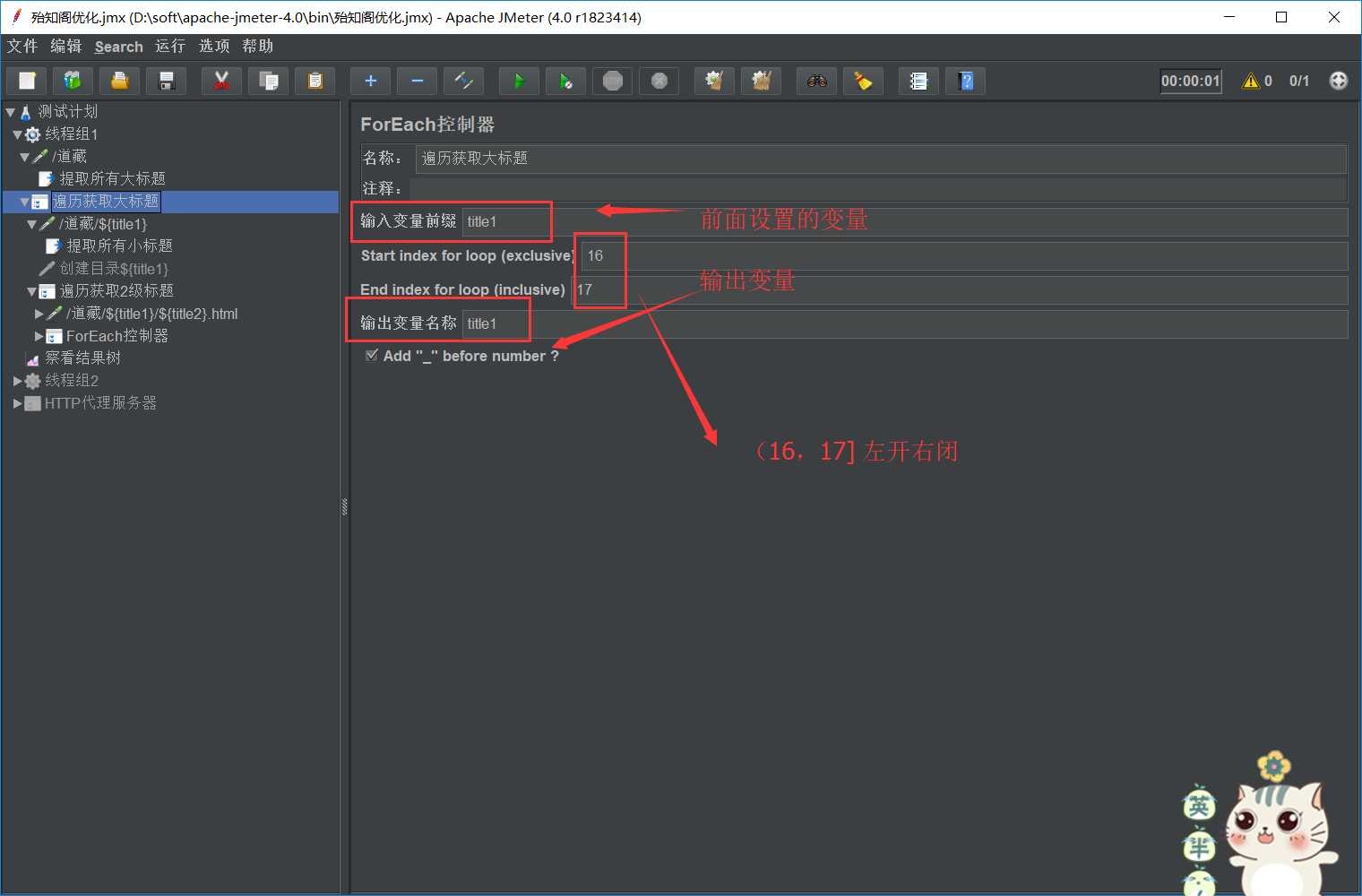
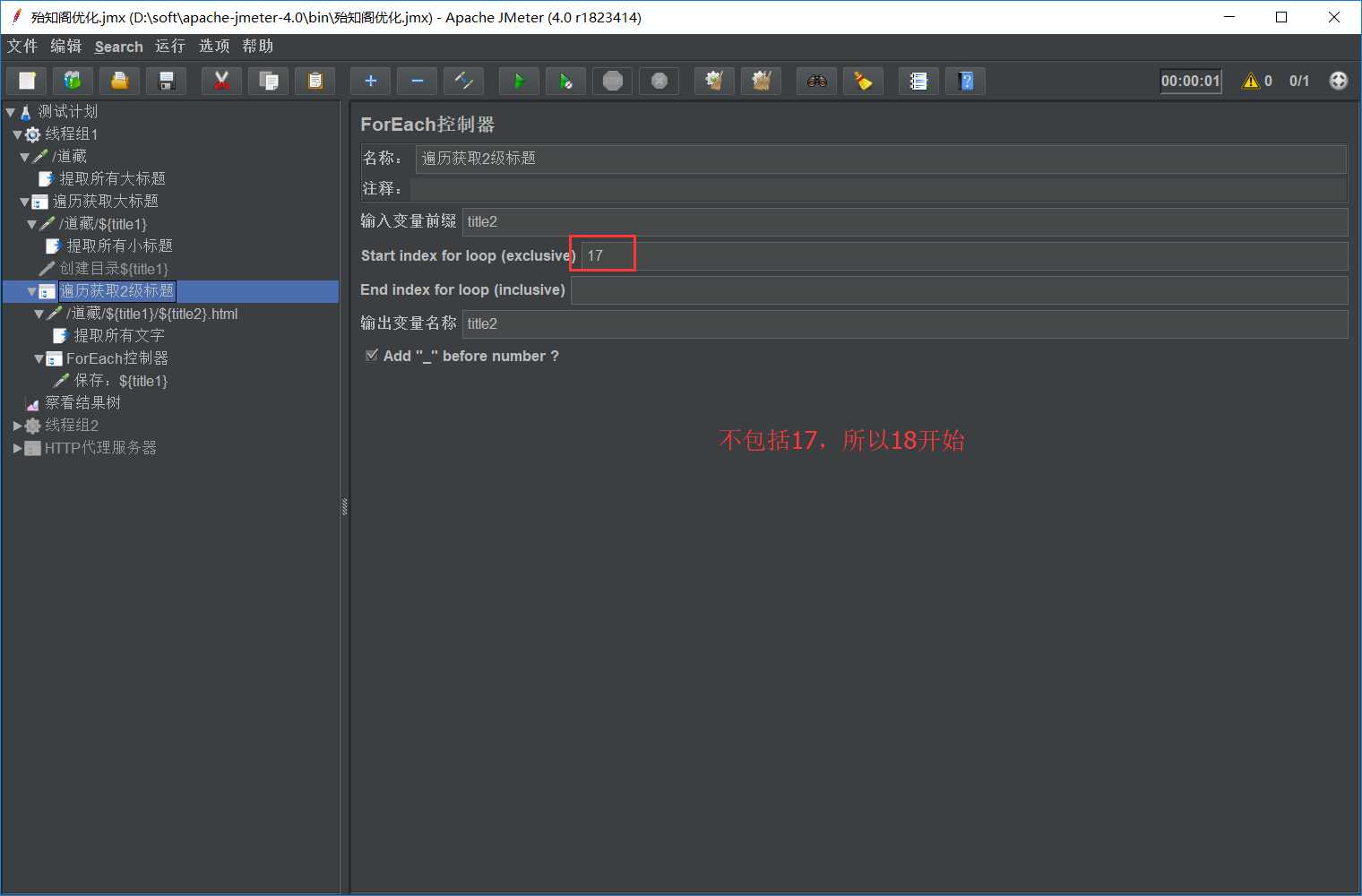
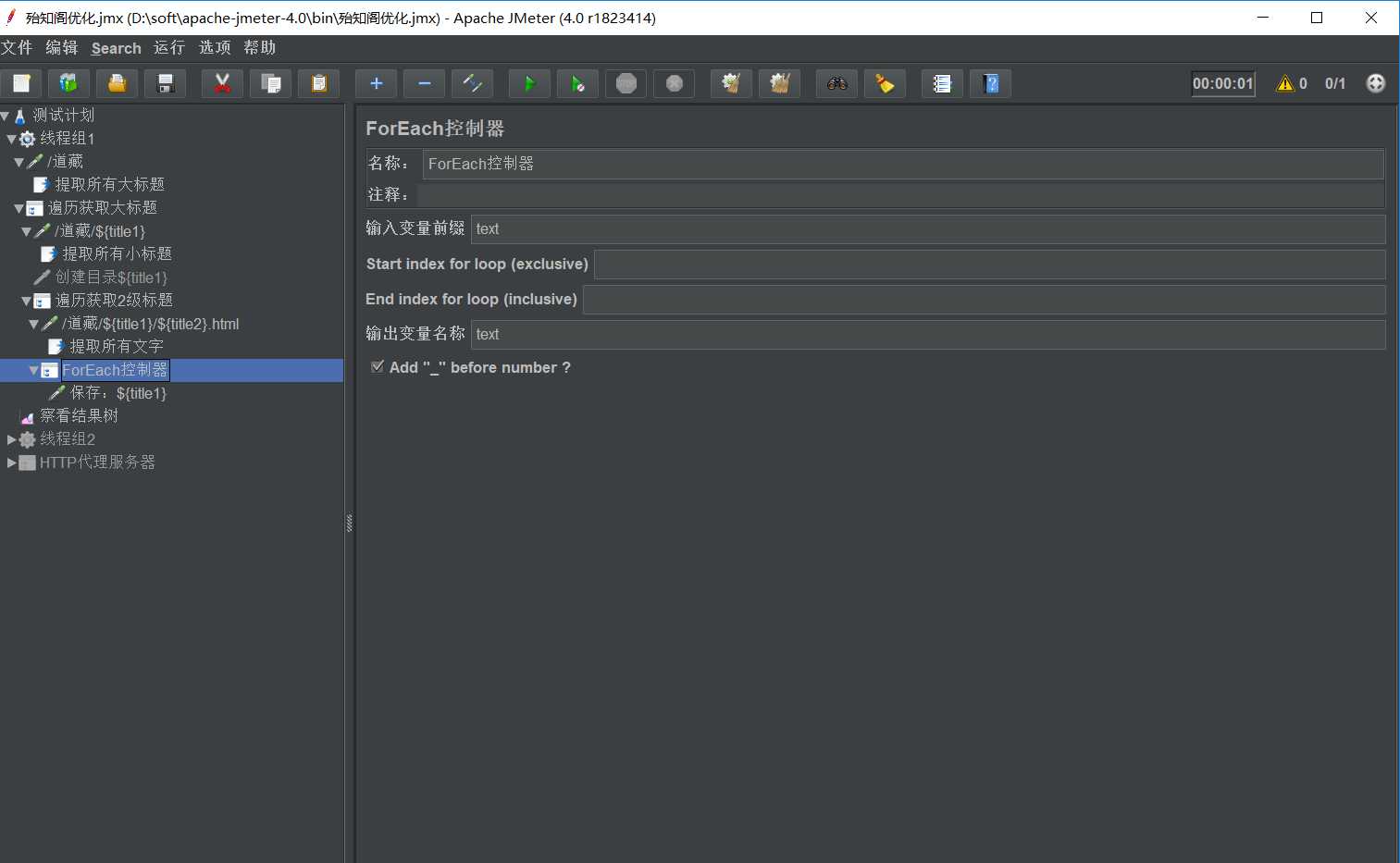
输入前缀是title1, 左下角勾选“Add _ before number”,与输入前缀拼接后为“title1_”。start index for loop为16,end index for loop为17,是“左开右闭”,即(16,17]。ForEach控制器会依次取title1_17,title1_18,并赋值给 financial_type,这里就取title1_17。
如下图从title1_17开始:
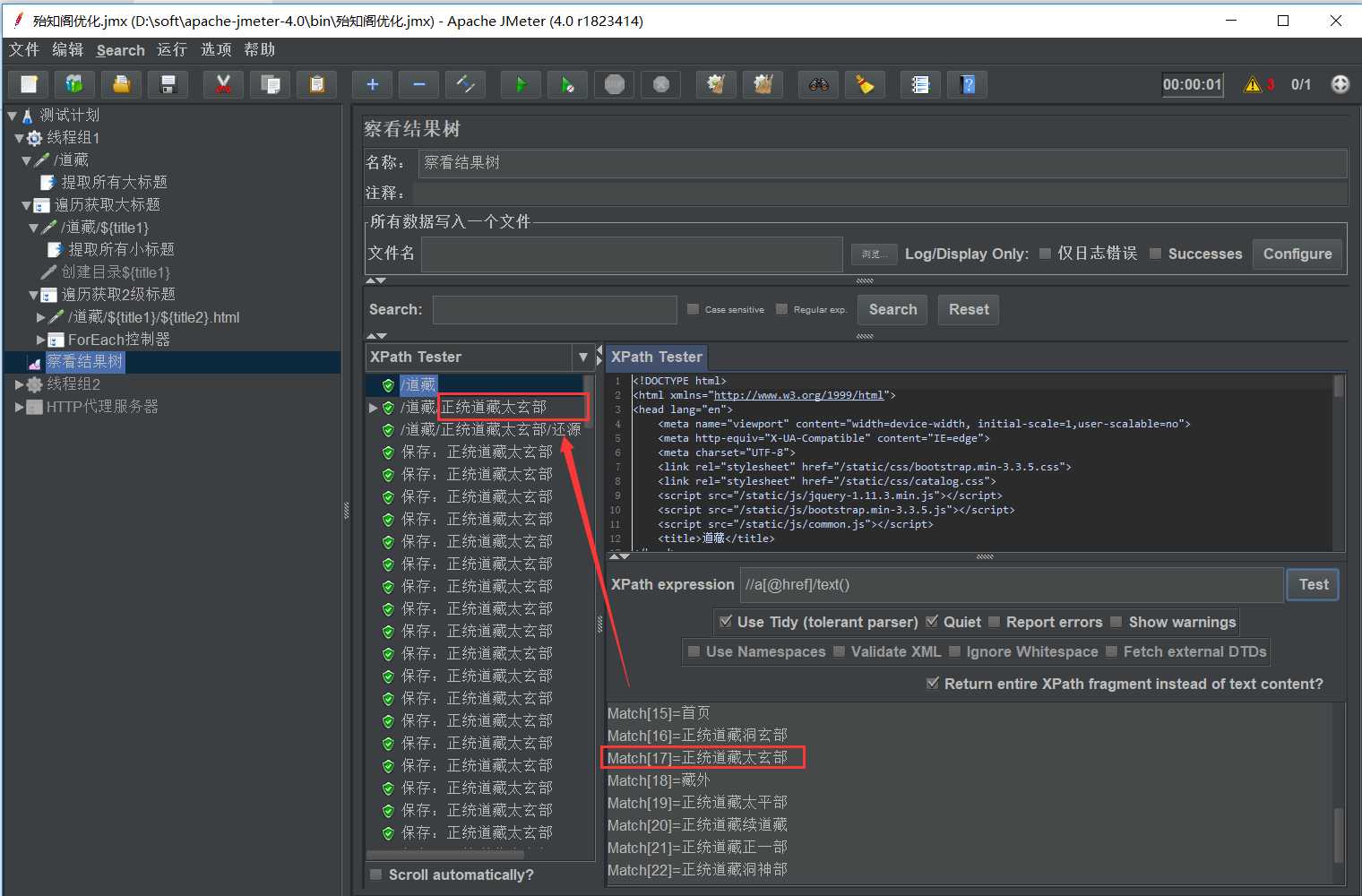
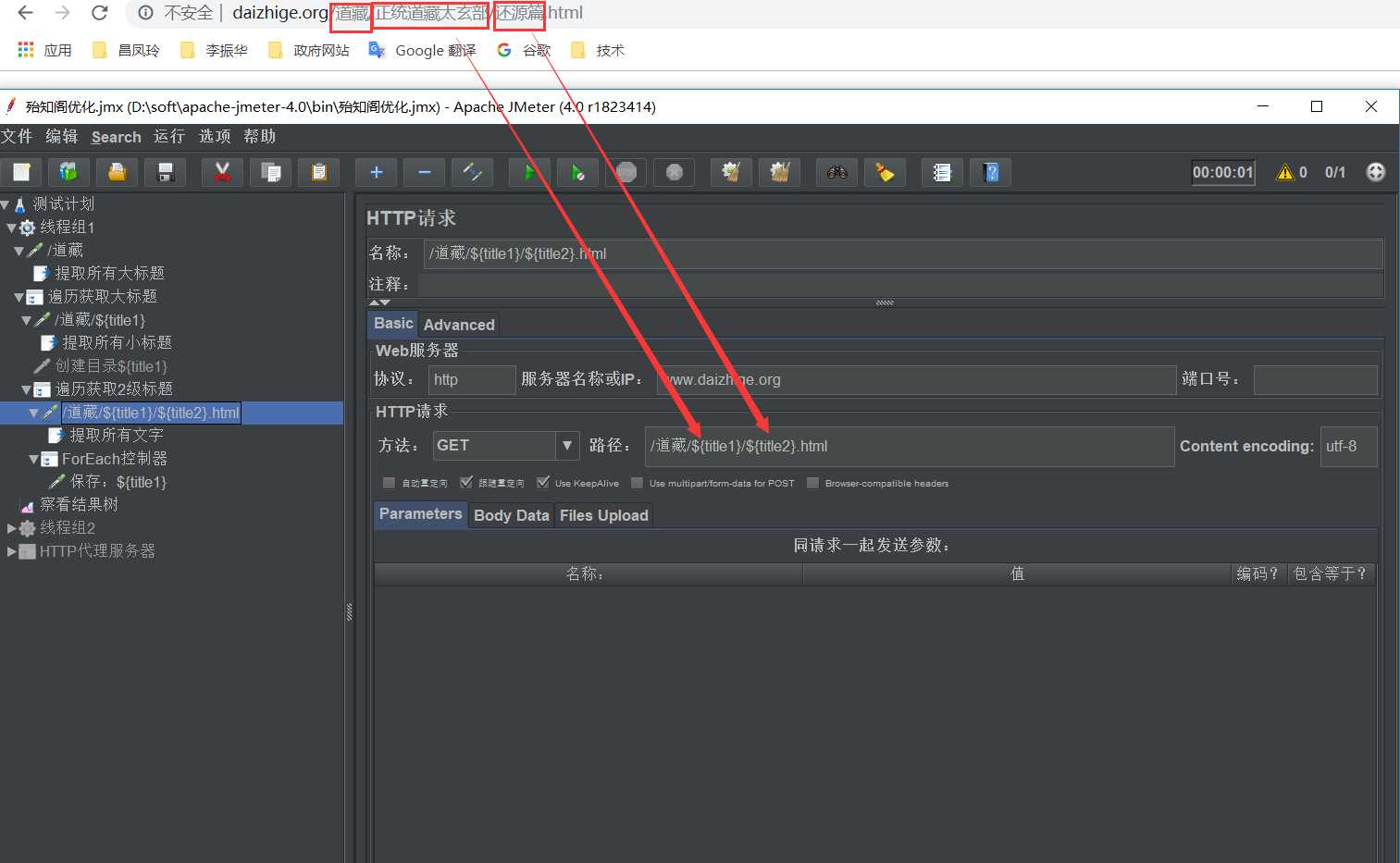
5、获取二级标题
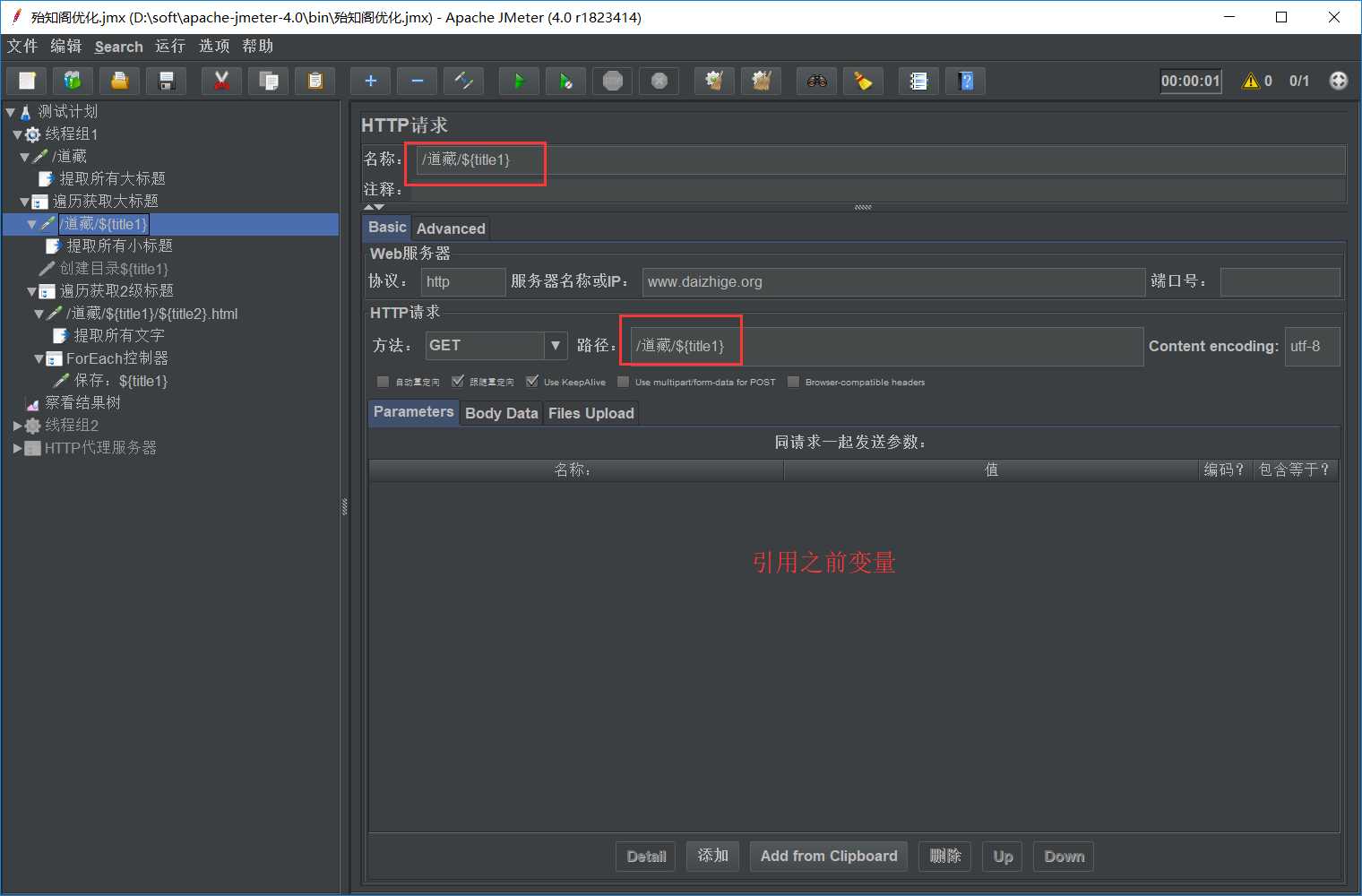
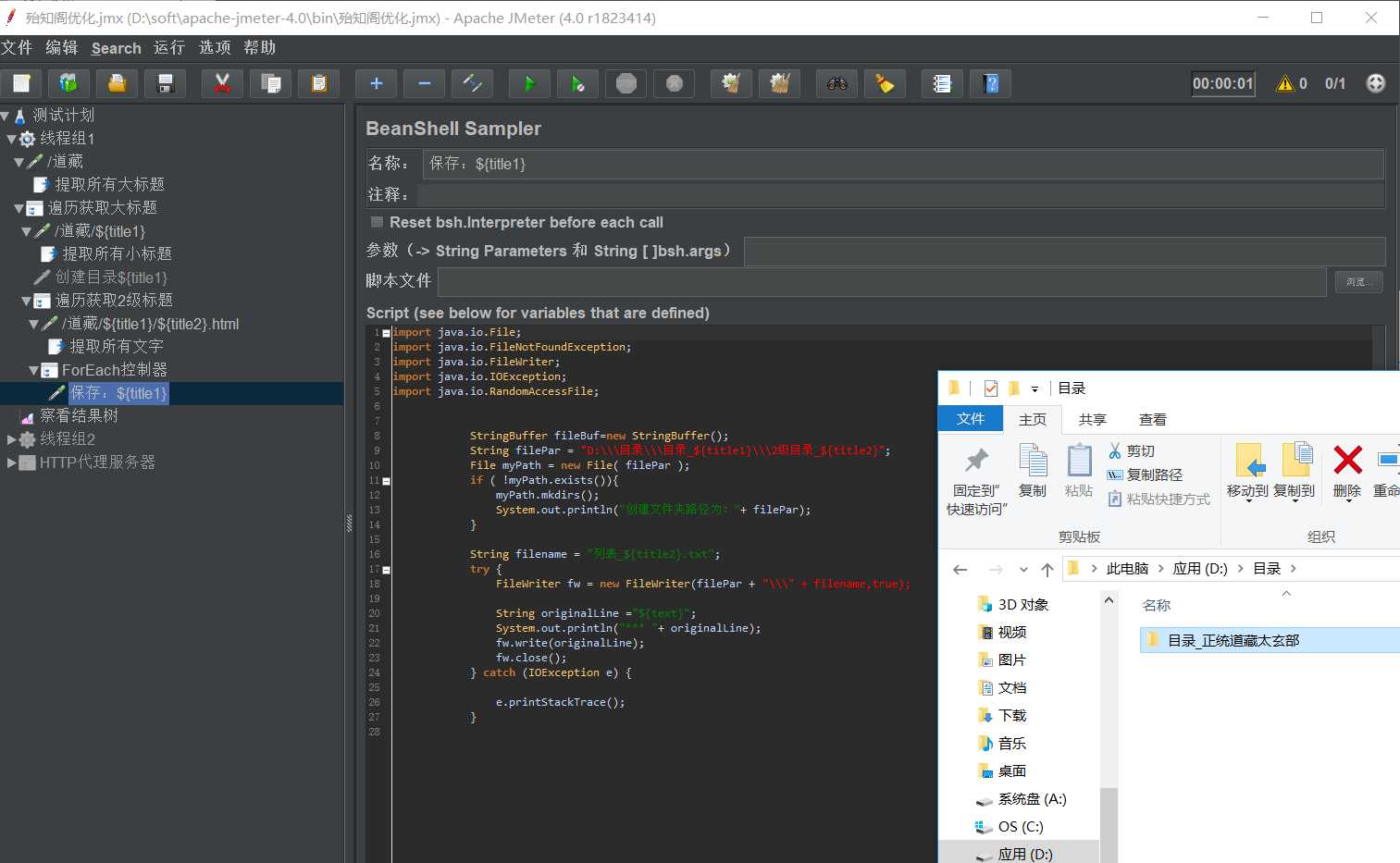
import java.io.File; import java.io.FileNotFoundException; import java.io.FileWriter; import java.io.IOException; import java.io.RandomAccessFile; StringBuffer fileBuf=new StringBuffer(); String filePar = "D:\\\目录\\\目录_${title1}\\\2级目录_${title2}"; File myPath = new File( filePar ); if ( !myPath.exists()){ myPath.mkdirs(); System.out.println("创建文件夹路径为:"+ filePar); } String filename = "列表_${title2}.txt"; try { FileWriter fw = new FileWriter(filePar + "\\\" + filename,true); String originalLine ="${text}"; System.out.println("*** "+ originalLine); fw.write(originalLine); fw.close(); } catch (IOException e) { e.printStackTrace(); }
标签:pat 元素 取值 text 节点 解决 抓取 赋值 路径
原文地址:https://www.cnblogs.com/shishibuwan/p/11330301.html