标签:mic mamicode htm url 技术 载器 str 运行 一个
时间不等人,我学爬虫的近期目的是爬取一个网站的资源,主要是在大量的伪html中访问url不断请求数据,关键问题在正则表达 和访问速度上。
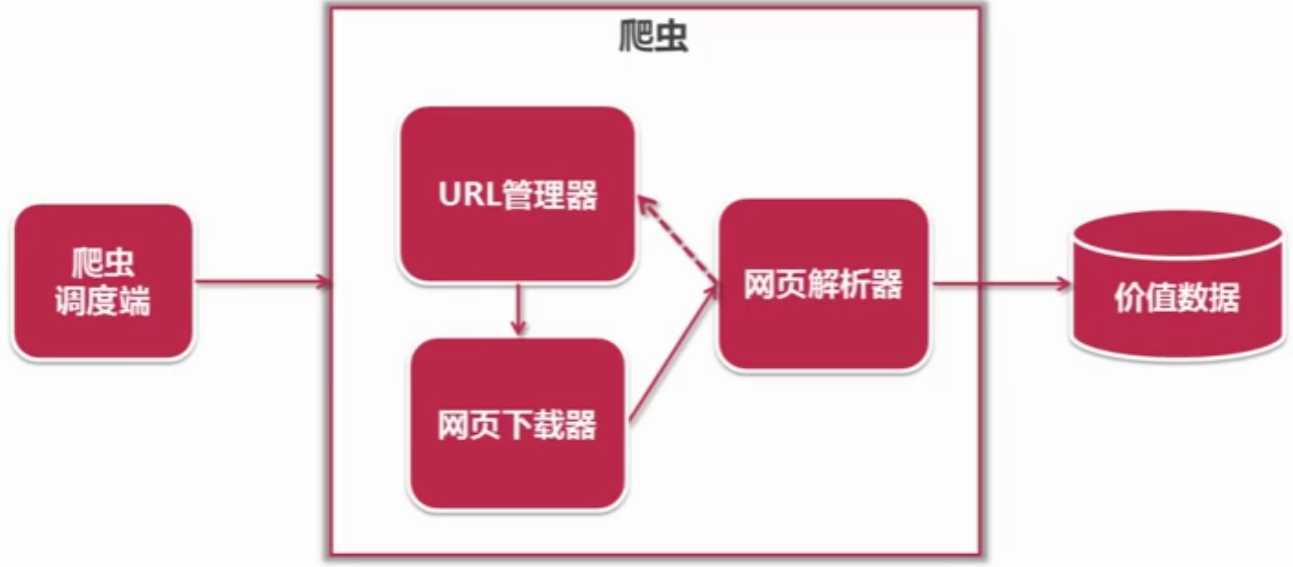
1/简单的爬虫架构示例
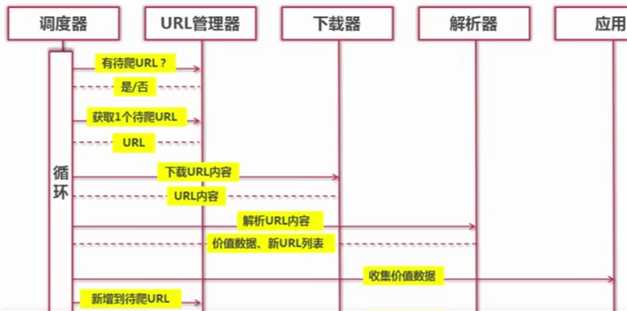
2/ 运行流程
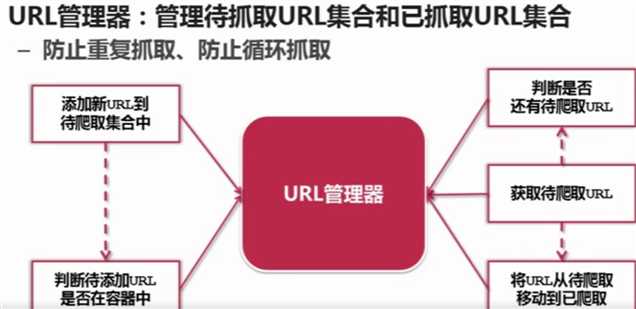
3/URL管理器
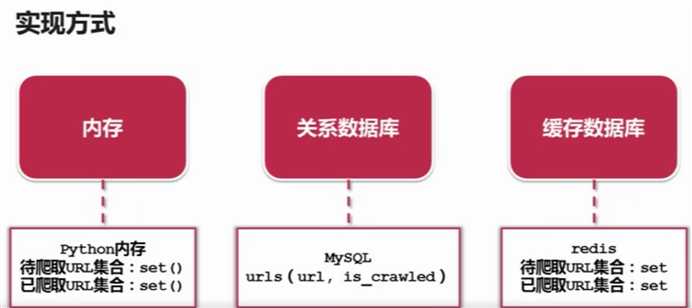
网页下载器-urllib2
网页解析器-正则表达式、html.paser、BeautifulSoup、Ixml
BeautifulSoup
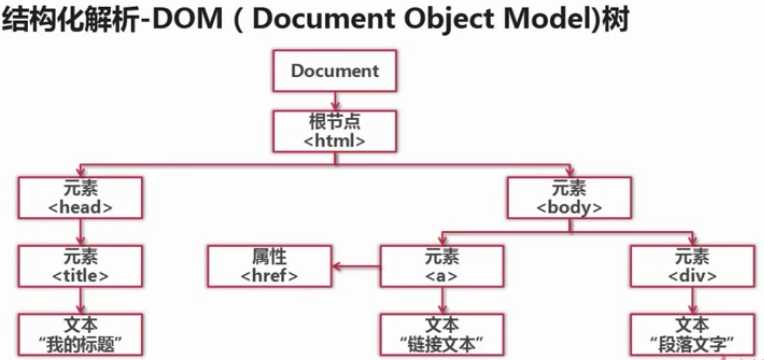
结构化解析-DOM解析
标签:mic mamicode htm url 技术 载器 str 运行 一个
原文地址:https://www.cnblogs.com/bogepm/p/11343229.html