标签:style blog http color io ar 使用 for sp
昨天学习了一下七大排序中的两个——冒泡排序和快速排序,遂用Lua简单的实现了一下。
冒泡排序:
--[[-- - orderByBubbling: 冒泡排序 - @param: t, - @return: list - table ]] function table.orderByBubbling(t) for i = 1, #t do for j = #t, i + 1, -1 do if t[j - 1] > t[j] then swap(t, j, j - 1) printT(t) end end end return t end
快速排序:
1 --[[-- 2 - partition: 获得快排中介值位置 3 - @param: list, low, high - 参数描述 4 - @return: pivotKeyIndex - 中介值索引 5 ]] 6 function partition(list, low, high) 7 local low = low 8 local high = high 9 local pivotKey = list[low] -- 定义一个中介值 10 11 -- 下面将中介值移动到列表的中间 12 -- 当左索引与右索引相邻时停止循环 13 while low < high do 14 -- 假如当前右值大于等于中介值则右索引左移 15 -- 否则交换中介值和右值位置 16 while low < high and list[high] >= pivotKey do 17 high = high - 1 18 end 19 swap(list, low, high) 20 21 -- 假如当前左值小于等于中介值则左索引右移 22 -- 否则交换中介值和左值位置 23 while low < high and list[low] <= pivotKey do 24 low = low + 1 25 end 26 swap(list, low, high) 27 end 28 return low 29 end 30 31 --[[-- 32 - orderByQuick: 快速排序 33 - @param: list, low, high - 参数描述 34 - @return: list - table 35 ]] 36 function orderByQuick(list, low, high) 37 if low < high then 38 -- 返回列表中中介值所在的位置,该位置左边的值都小于等于中介值,右边的值都大于等于中介值 39 local pivotKeyIndex = partition(list, low, high) 40 -- 分别将中介值左右两边的列表递归快排 41 orderByQuick(list, low, pivotKeyIndex - 1) 42 orderByQuick(list, pivotKeyIndex + 1, high) 43 end 44 end
效果测试:
1 local printT = function(t) 2 print("printT ---------------") 3 table.walk(t, function(v, k) 4 print(k, v) 5 end) 6 print("---------------") 7 end 8 9 local t = {5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46,5,2,5,4,-100,25,76,-10,-100,46} 10 -- local t = {5,2,5,4} 11 local num = table.nums(t) 12 orderByQuick(t, 1, num) -- 总结,快拍bushi 13 -- table.orderByBubbling(t) 14 print("after order--------") 15 printT(t)
结果当然是两种排序算法都正确的排出了table中的顺序,但是效率有了明显的差异,
这是冒泡排序所用时间: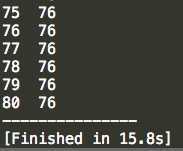 ,然后是快速排序所用时间:
,然后是快速排序所用时间: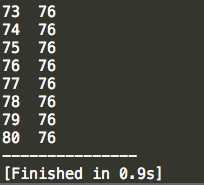 ,原来算法的好坏表现出来的可以差这么多啊。。。
,原来算法的好坏表现出来的可以差这么多啊。。。
下面是我学习这两个算法的帖子:
http://www.cnblogs.com/mcgrady/p/3226740.html,感谢原作者的分享。。。
排序是我们生活中经常会面对的问题。同学们做操时会按照从矮到高排列;老师查看上课出勤情况时,会按学生学号顺序点名;高考录取时,会按成绩总分降序依次录取等。排序是数据处理中经常使用的一种重要的运算,它在我们的程序开发中承担着非常重要的角色。
排序分为以下四类共七种排序方法:
交换排序:
1) 冒泡排序
2) 快速排序
选择排序:
3) 直接选择排序
4) 堆排序
插入排序:
5) 直接插入排序
6) 希尔排序
合并排序:
7) 合并排序
这一篇文章主要总结的是交换排序,即冒泡排序和C#提供的快速排序。交换排序的基本思想是:两两比较待排序记录的关键字,如果发现两个记录的次序相反时即进行交换,直到所有记录都没有反序时为目上。本篇文章主要从以下几个方面进行总结:
1,冒泡排序及算法实现
2,快速排序及算法实现
3,冒泡排序VS快速排序
什么时冒泡排序呢?冒泡排序是一种简单的排序方法,其基本思想是:通过相邻元素之间的比较和交换,使关键字较小的元素逐渐从底部移向顶部,就像水底下的气泡一样逐渐向上冒泡,所以使用该方法的排序称为“冒泡”排序。
下面以一张图来展示冒泡排序的全过程,其中方括号内为下一躺要排序的区间,方括号前面的一个关键字为本躺排序浮出来的最小关键字。

了解了冒泡排序的实现过程后,我们很容易写出冒泡排序的算法实现。
C#版:

namespace BubbleSort.CSharp
{
class Program
{
static void Main(string[] args)
{
List<int> list = new List<int>() { 50, 10, 90, 30, 70, 40, 80, 60, 20 };
Console.WriteLine("********************冒泡排序********************");
Console.WriteLine("排序前:");
Display(list);
Console.WriteLine("排序后:");
BubbleSort(list);
Display(list);
Console.ReadKey();
}
/// <summary>
/// 打印结果
/// </summary>
/// <param name="list"></param>
private static void Display(List<int> list)
{
Console.WriteLine("\n**********展示结果**********\n");
if (list!=null&&list.Count>0)
{
foreach (var item in list)
{
Console.Write("{0} ", item);
}
}
Console.WriteLine("\n**********展示完毕**********\n");
}
/// <summary>
/// 冒泡排序算法
/// </summary>
/// <param name="list"></param>
/// <returns></returns>
private static List<int> BubbleSort(List<int> list)
{
int temp;
//做多少躺排序(最多做n-1躺排序)
for (int i = 0; i < list.Count-1; i++)
{
//从后往前循环比较(注意j的范围)
for (int j = list.Count - 1; j > i; j--)
{
if (list[j - 1] > list[j])
{
//交换次序
temp=list[j-1];
list[j-1]=list[j];
list[j] = temp;
}
}
}
return list;
}
}
}
程序运行结果:

C语言版:
/*包含头文件*/
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
/* 用于快速排序时判断是否选用插入排序阙值 */
#define MAX_LENGTH_INSERT_SORT 7
/* 用于要排序数组个数最大值,可根据需要修改 */
#define MAXSIZE 100
typedef int Status;
typedef struct
{
int data[MAXSIZE];
int length;
}SeqList;
/*冒泡排序算法*/
void BubbleSort(SeqList *seqList)
{
int i,j;
//做多少躺排序(最多做n-1躺排序)
for (i=0;i<seqList->length-1;i++)
{
//从后往前循环比较(注意j的范围)
for (j=seqList->length-1;j>i;j--)
{
if (seqList->data[j-1]>seqList->data[j])
{
//交换次序
int temp=seqList->data[j-1];
seqList->data[j-1]=seqList->data[j];
seqList->data[j]=temp;
}
}
}
}
/*打印结果*/
void Display(SeqList *seqList)
{
int i;
printf("\n**********展示结果**********\n");
for (i=0;i<seqList->length;i++)
{
printf("%d ",seqList->data[i]);
}
printf("\n**********展示完毕**********\n");
}
#define N 9
void main()
{
int i,j;
SeqList seqList;
//定义数组
int d[N]={50,10,90,30,70,40,80,60,20};
for (i=0;i<N;i++)
{
seqList.data[i]=d[i];
}
seqList.length=N;
printf("***************冒泡排序***************\n");
printf("排序前:");
Display(&seqList);
BubbleSort(&seqList);
printf("\n排序后:");
Display(&seqList);
getchar();
}
程序运行结果同C#版
快速排序(Quick Sort)又称为划分交换排序。快速排序是对冒泡排序的一种改进方法,在冒泡排序中,进行记录关键字的比较和交换是在相邻记录之间进行的,记录每次交换只能上移或下移一个相邻位置,因而总的比较和移动次数较多,效率相对较低。而在快速排序中,记录关键字的比较和记录的交换是从两端向中间进行的,待排序关键字较大的记录一次就能够交换到后面单元中,而关键字较小的记录一次就能交换到前面单元中,记录每次移动的距离较远,因此总的比较和移动次数较少,速度较快,故称为“快速排序”。
快速排序的基本思想是:通过一躺排序将待排记录分割成独立的两部分, 其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
下面是实现代码:
C#版:
namespace QuickSort.CSharp
{
class Program
{
static void Main(string[] args)
{
List<int> list = new List<int> { 50, 10, 90, 30, 70, 40, 80, 60, 20 };
Console.WriteLine("********************快速排序********************");
Console.WriteLine("排序前:");
Display(list);
Console.WriteLine("排序后:");
QuickSort(list,0,list.Count-1);
Display(list);
Console.ReadKey();
}
/// <summary>
/// 打印列表元素
/// </summary>
/// <param name="list"></param>
private static void Display(List<int> list)
{
Console.WriteLine("\n**********展示结果**********\n");
if (list != null && list.Count > 0)
{
foreach (var item in list)
{
Console.Write("{0} ", item);
}
}
Console.WriteLine("\n**********展示完毕**********\n");
}
/// <summary>
/// 快速排序算法
/// </summary>
/// <param name="list"></param>
/// <param name="low"></param>
/// <param name="high"></param>
public static void QuickSort(List<int> list, int low, int high)
{
if (low < high)
{
//分割数组,找到枢轴
int pivot = Partition(list,low,high);
//递归调用,对低子表进行排序
QuickSort(list,low,pivot-1);
//对高子表进行排序
QuickSort(list,pivot+1,high);
}
}
/// <summary>
/// 分割列表,找到枢轴
/// </summary>
/// <param name="list"></param>
/// <param name="low"></param>
/// <param name="high"></param>
/// <returns></returns>
private static int Partition(List<int> list, int low, int high)
{
//用列表的第一个记录作枢轴记录
int pivotKey = list[low];
while (low < high)
{
while (low < high && list[high] >= pivotKey)
high--;
Swap(list,low,high);//交换
while (low < high && list[low] <= pivotKey)
low++;
Swap(list,low,high);
}
//返回枢轴所在位置
return low;
}
/// <summary>
/// 交换列表中两个位置的元素
/// </summary>
/// <param name="list"></param>
/// <param name="low"></param>
/// <param name="high"></param>
/// <returns></returns>
private static void Swap(List<int> list, int low, int high)
{
int temp = -1;
if (list != null && list.Count > 0)
{
temp = list[low];
list[low] = list[high];
list[high] = temp;
}
}
}
}
程序运行结果:

C语言版:
/*包含头文件*/
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <stdlib.h>
#include <io.h>
#include <math.h>
#include <time.h>
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
/* 用于快速排序时判断是否选用插入排序阙值 */
#define MAX_LENGTH_INSERT_SORT 7
/* 用于要排序数组个数最大值,可根据需要修改 */
#define MAXSIZE 100
typedef int Status;
typedef struct
{
int data[MAXSIZE];
int length;
}SeqList;
/*快速排序算法*/
void QuickSort(SeqList *seqList,int low,int high)
{
int pivot;
while(low<high)
{
//分割列表,找到枢轴
pivot=Partition(seqList,low,high);
//递归调用,对低子列表进行排序
QuickSort(seqList,low,pivot-1);
QuickSort(seqList,pivot+1,high);
}
}
/*交换顺序表L中子表的记录,使枢轴记录到位,并返回其所在位置*/
/* 此时在它之前(后)的记录均不大(小)于它。 */
int Partition(SeqList *seqList,int low,int high)
{
int pivotkey;
pivotkey=seqList->data[low];
/* 从表的两端交替地向中间扫描 */
while(low<high)
{
while(low<high&&seqList->data[high]>=pivotkey)
high--;
Swap(seqList,low,high);
while(low<high&&seqList->data[low]<=pivotkey)
low++;
Swap(seqList,low,high);
}
return low;
}
/* 交换L中数组SeqList下标为i和j的值 */
void Swap(SeqList *seqList,int i,int j)
{
int temp;
temp=seqList->data[i];
seqList->data[i]=seqList->data[j];
seqList->data[j]=temp;
}
/*打印结果*/
void Display(SeqList *seqList)
{
int i;
printf("\n**********展示结果**********\n");
for (i=0;i<seqList->length;i++)
{
printf("%d ",seqList->data[i]);
}
printf("\n**********展示完毕**********\n");
}
#define N 9
void main()
{
int i,j;
SeqList seqList;
//定义数组
int d[N]={50,10,90,30,70,40,80,60,20};
for (i=0;i<N;i++)
{
seqList.data[i]=d[i];
}
seqList.length=N;
printf("***************快速排序***************\n");
printf("排序前:");
Display(&seqList);
QuickSort(&seqList,0,seqList.length-1);
printf("\n排序后:");
Display(&seqList);
getchar();
}
程序运行结果同上。
关于冒泡排序和快速排序之间排序速度的比较我就选用C#语言版本的来进行,代码如下:
static void Main(string[] args)
{
//共进行三次比较
for (int i = 1; i <= 3; i++)
{
//初始化List
List<int> list = new List<int>();
for (int j = 0; j < 1000; j++)
{
Thread.Sleep(1);
list.Add(new Random((int)DateTime.Now.Ticks).Next(0,10000));
}
//快速排序(系统内置)耗费时间
Console.WriteLine("\n第"+i+"次比较:");
Stopwatch watch = new Stopwatch();
watch.Start();
var result = list.OrderBy(p => p).ToList();
watch.Stop();
Console.WriteLine("\n快速排序(系统)耗费时间:"+watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:"+String.Join(",",result.Take(10).ToList()));
//快速排序(自定义)耗费时间
watch.Start();
QuickSort.CSharp.Program.QuickSort(list,0,list.Count-1);
watch.Stop();
Console.WriteLine("\n快速排序(自定义)耗费时间:" + watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:" + String.Join(",", result.Take(10).ToList()));
//冒泡排序耗费时间
watch.Start();
result = BubbleSort(list);
watch.Stop();
Console.WriteLine("\n冒泡排序耗费时间:" + watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:" + String.Join(",", result.Take(10).ToList()));
}
Console.ReadKey();
}
比较结果如图:

可见,快速排序的速度比冒泡排序要快。
标签:style blog http color io ar 使用 for sp
原文地址:http://www.cnblogs.com/cg-Yun/p/4048941.html