标签:学院 cache 不同 数据 数值 服务器 哈希算法 art png
图片摘自:
每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)
一:背景
- 一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的。
- 设计目标是为了解决因特网中的热点(Hot spot)问题。
- 一致性哈希修正了使用的简单哈希算法带来的问题。
二:简单哈希算法带来的问题?
- 在简单哈希算法中
- 我们会根据hash算法得出的数值和机器数取模计算,计算发到哪台机器上。
- Hash(资源)% 机器数 = 落到哪台机器上
- 这样的话就不会遍历所有的服务器,大大提升了性能!
- 但是,在服务器数量变动的时候,所有缓存的位置都要发生改变!
- 假设4台缓存中突然有一台缓存服务器出现了故障,无法进行缓存。
- 那么我们则需要将故障机器移除,但是如果移除了一台缓存服务器,那么缓存服务器数量从4台变为3。
- 如果想要访问资源,资源的缓存位置必定会发生改变,以前资源缓存也会失去缓存的作用与意义。
- 同时由于大量缓存在同一时间失效,造成了缓存的雪崩,服务端也会承受巨大压力。
三:一致性哈希(hash)解决的问题
- 解决增减服务器导致的大量数据震荡问题。
四:一致性哈希(hash)
- 原理
- 创造环形哈希(hash)空间,不同节点映射到环上的不同位置,通过和机器节点的匹配,完成hash一致。
- 做法
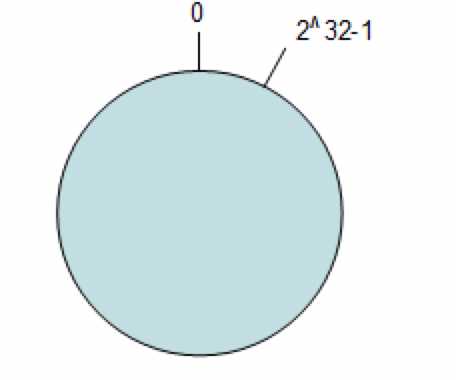
- 按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。 可以将这些数字头尾相连,想象成一个闭合的环形。
- 
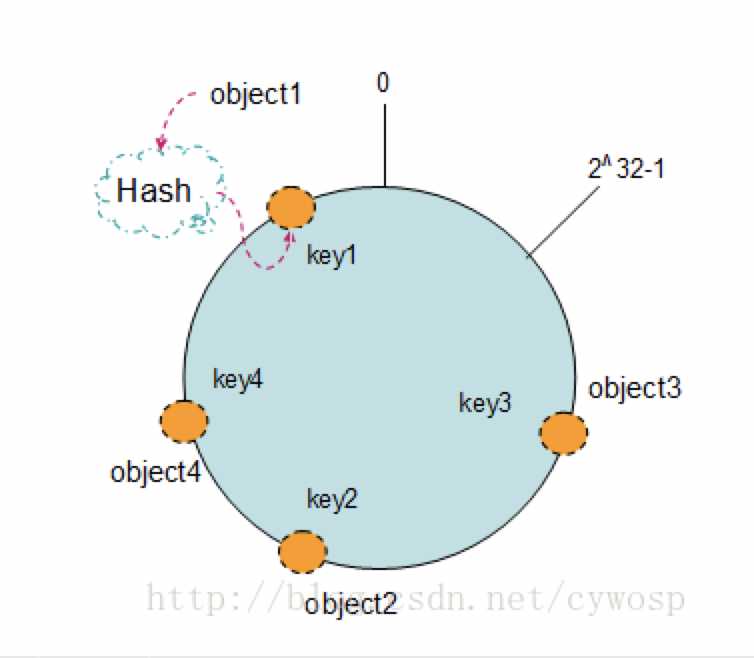
- 现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。
- 
- 在采用一致性哈希算法的分布式集群中将新的机器加入。
- 其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中,然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
- 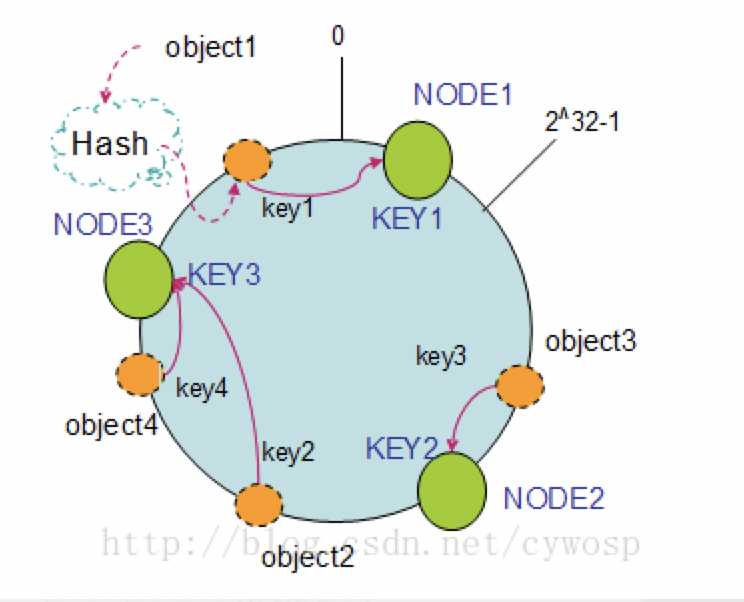
- 通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了节点1中
- object3存储到了节点2中
- object2、object4存储到了节点3中。
- 在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
标签:学院 cache 不同 数据 数值 服务器 哈希算法 art png
原文地址:https://www.cnblogs.com/25-lH/p/11345066.html