标签:自动 request方法 prot 对象 注释 传参 pre mic 应该
最近学web自动化时用到selenium库,感觉很神奇,遂琢磨了一下,写了点心得。
当我们输入以下三行代码并执行时,会发现新打开了一个浏览器窗口并访问了百度首页,然而这是怎么做到的呢?
1 from selenium import webdriver 2 driver = webdriver.Chrome() 3 driver.get(‘http://www.baidu.com‘)
首先我们来看一下selenium库的结构:
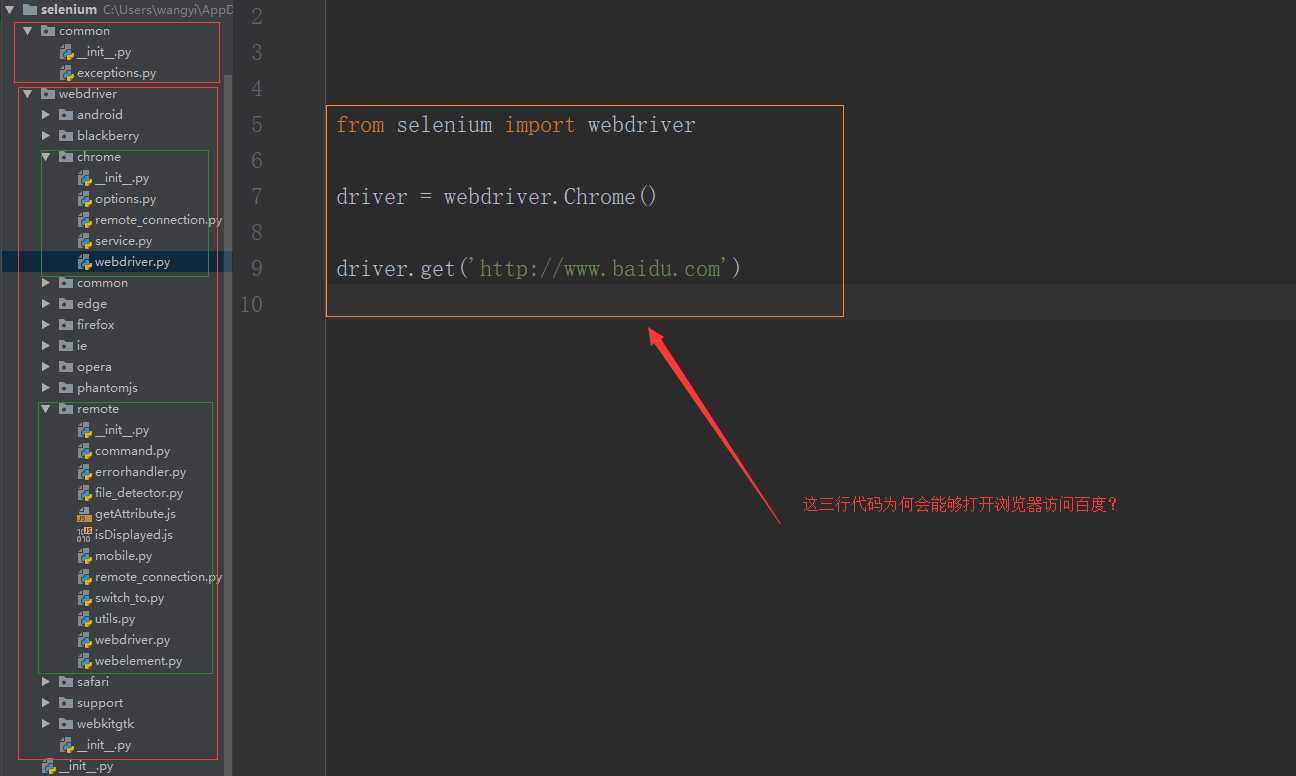
很显然,selenium就是一个软件包,里面有两个一级子包,common和webdriver。导入webdriver后,webdriver.Chrome()中的Chrome又是什么呢?
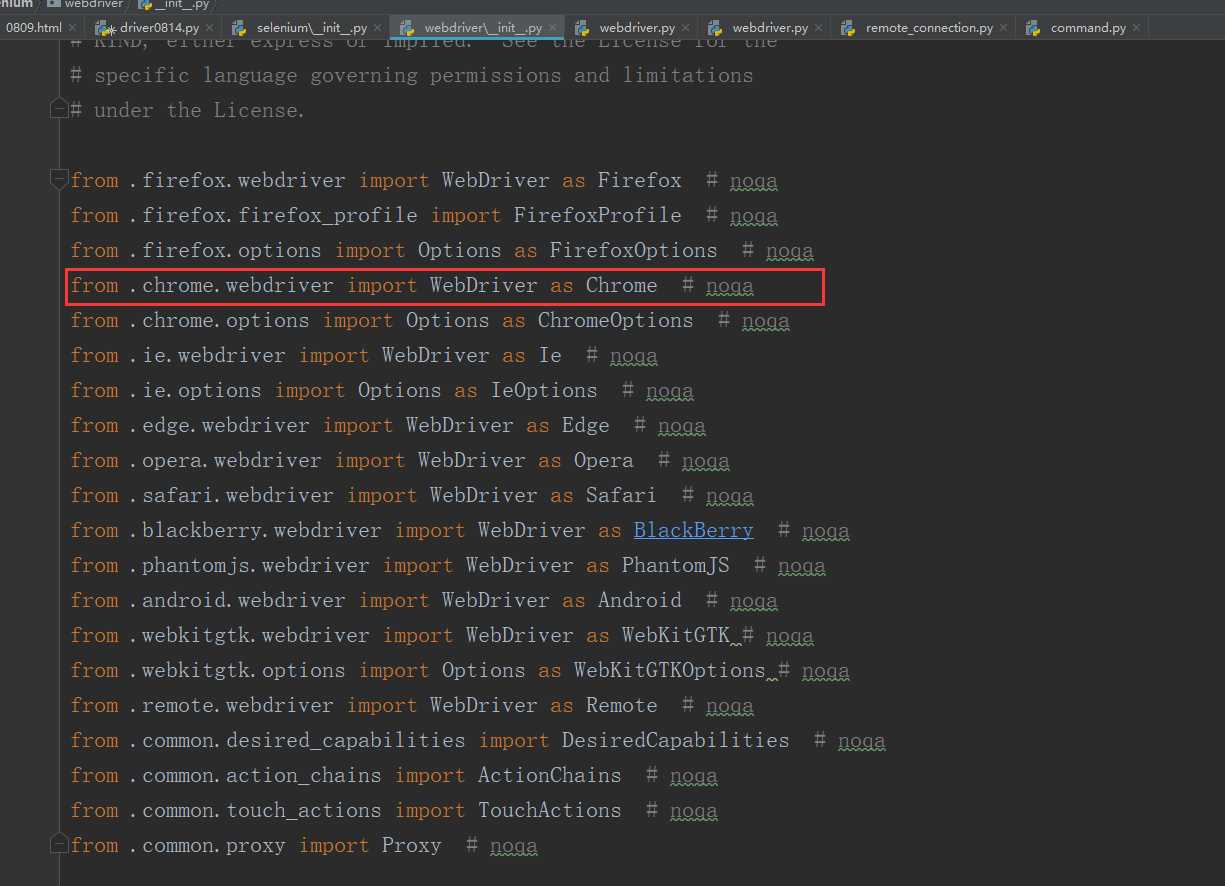
原来是来自二级子包chrome下的webdriver模块里的WebDriver类,所以driver=webdriver.Chrome()中的driver是一个WebDriver类的实例化对象。我们来看看这个类:
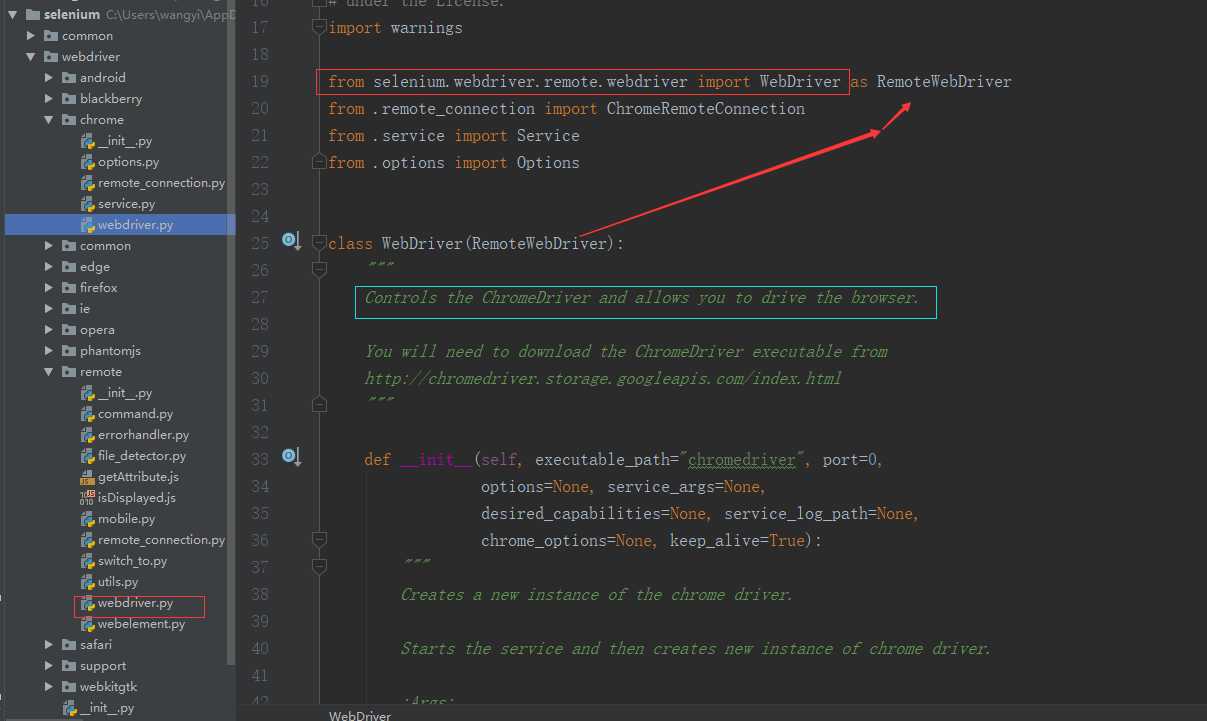
这个类是干嘛的呢?原来它是控制谷歌浏览器驱动去驱动浏览器的,但是仔细一找,也没看到它里面有get方法呀,哦,它继承自RemoteWebDriver类,也就是二级子包remote下的webdriver模块里的WebDriver类,呵呵,这还真是个高频词汇啊!get方法应该就在这里面,去找一下:
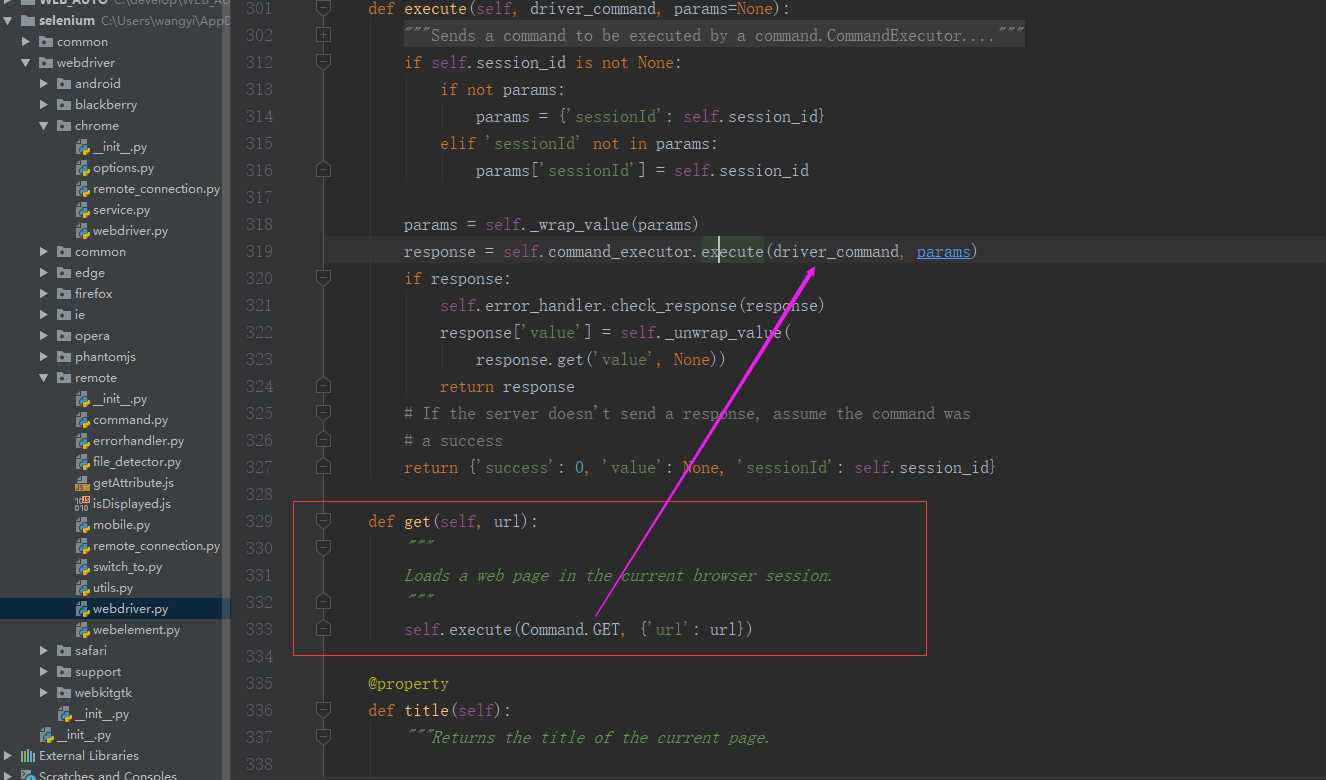
果然,get调用上面的execute方法,传参,发现execute又调用了command_executor.execute方法:
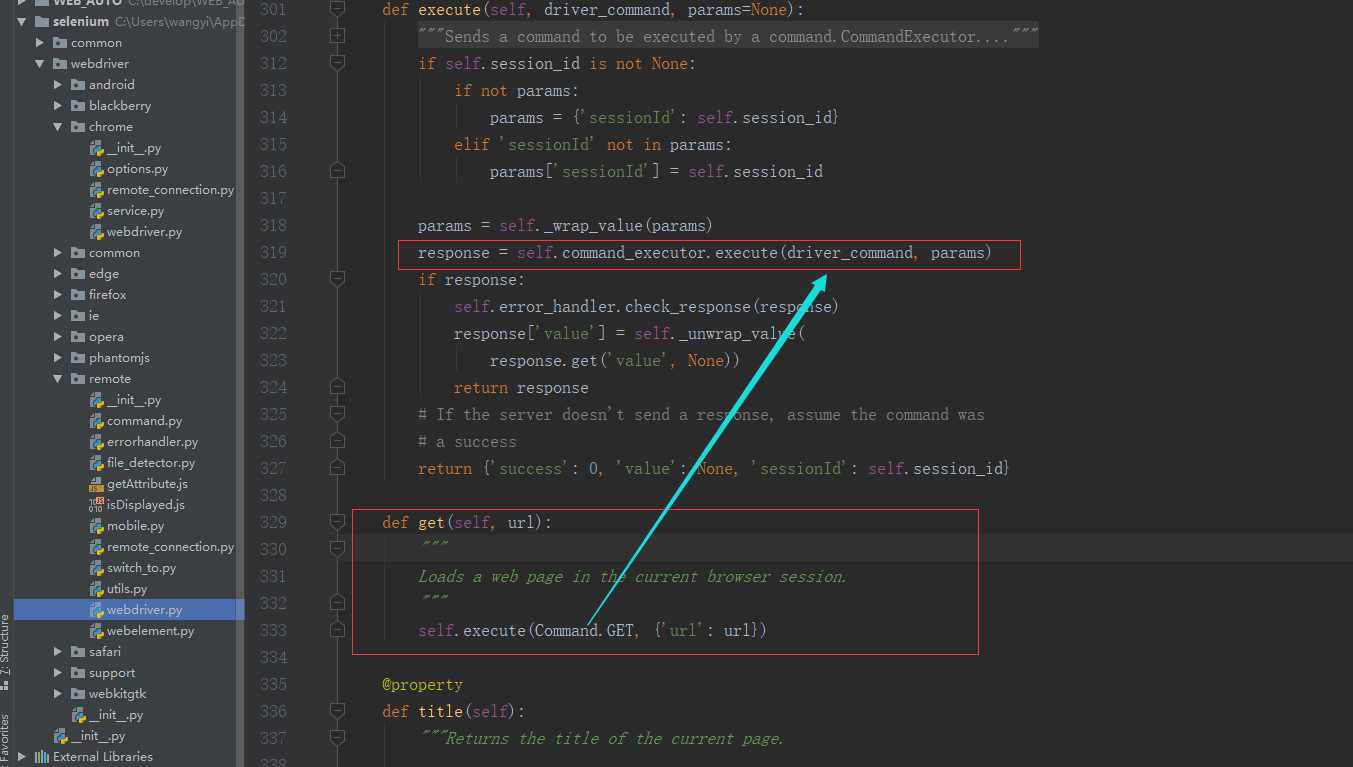
继续查看,发现command_executor.execute方法是remote_connection.py这个模块里面的RemoteConnection类下面的,
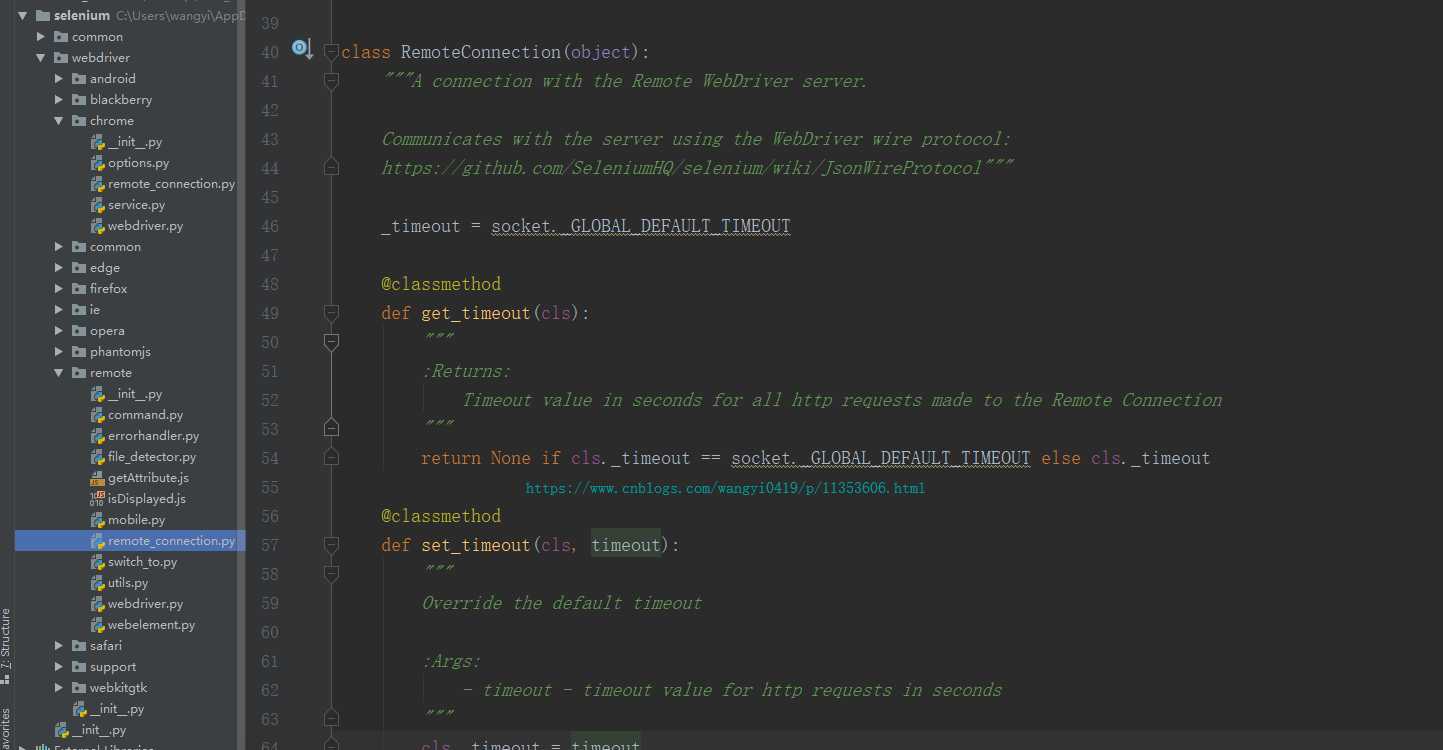
看这个类注释,连接到远程浏览器驱动服务,很显然,浏览器驱动是服务端,selenium是客户端。在下面找到execute方法:
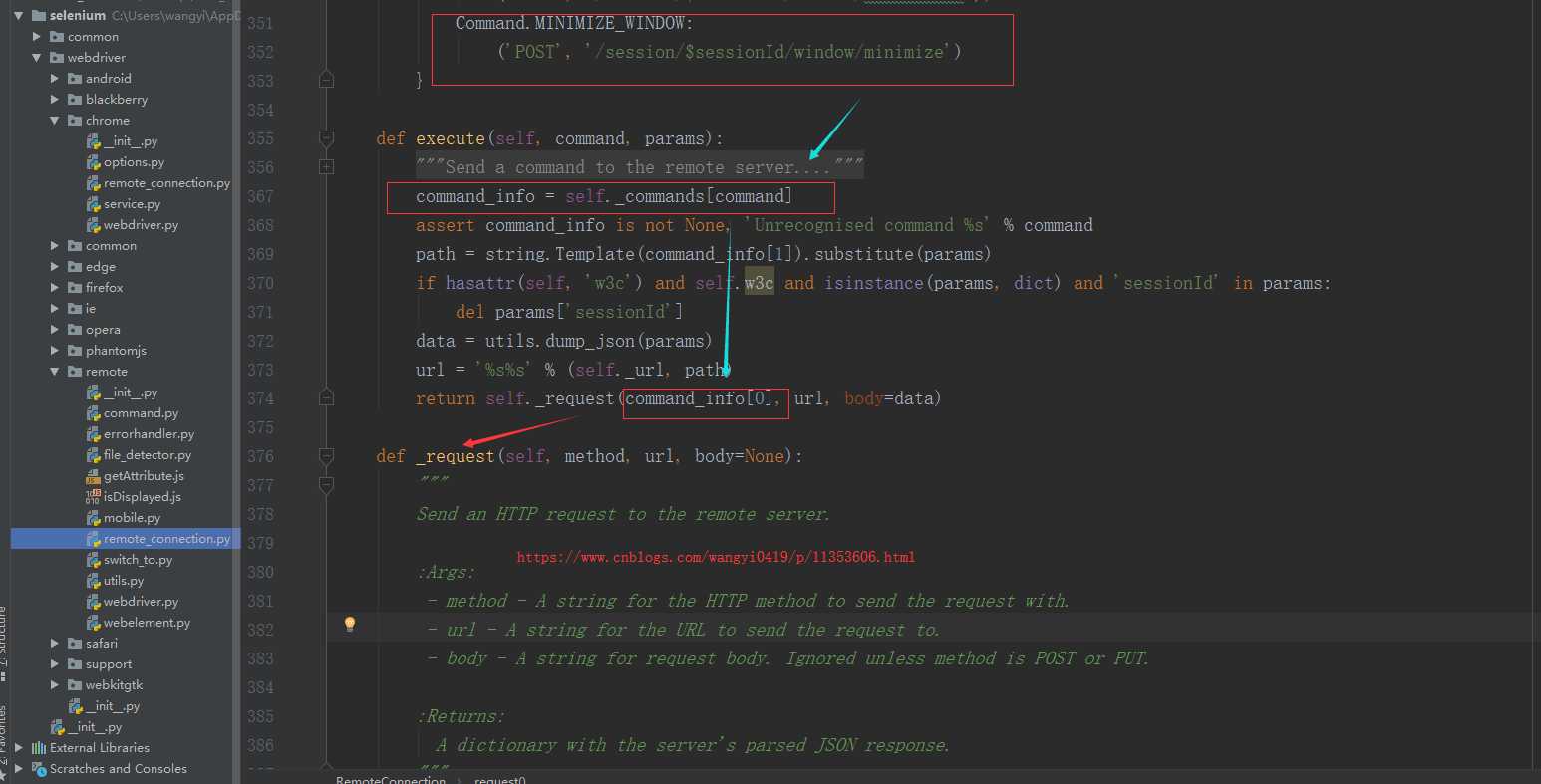
给远程服务端发命令command,又将命令传给下面的_request方法,发送HTTP请求给远程服务端,即浏览器驱动,这里出现了大家熟悉的请求方法get或者post,请求url,请求体,再往上看command:
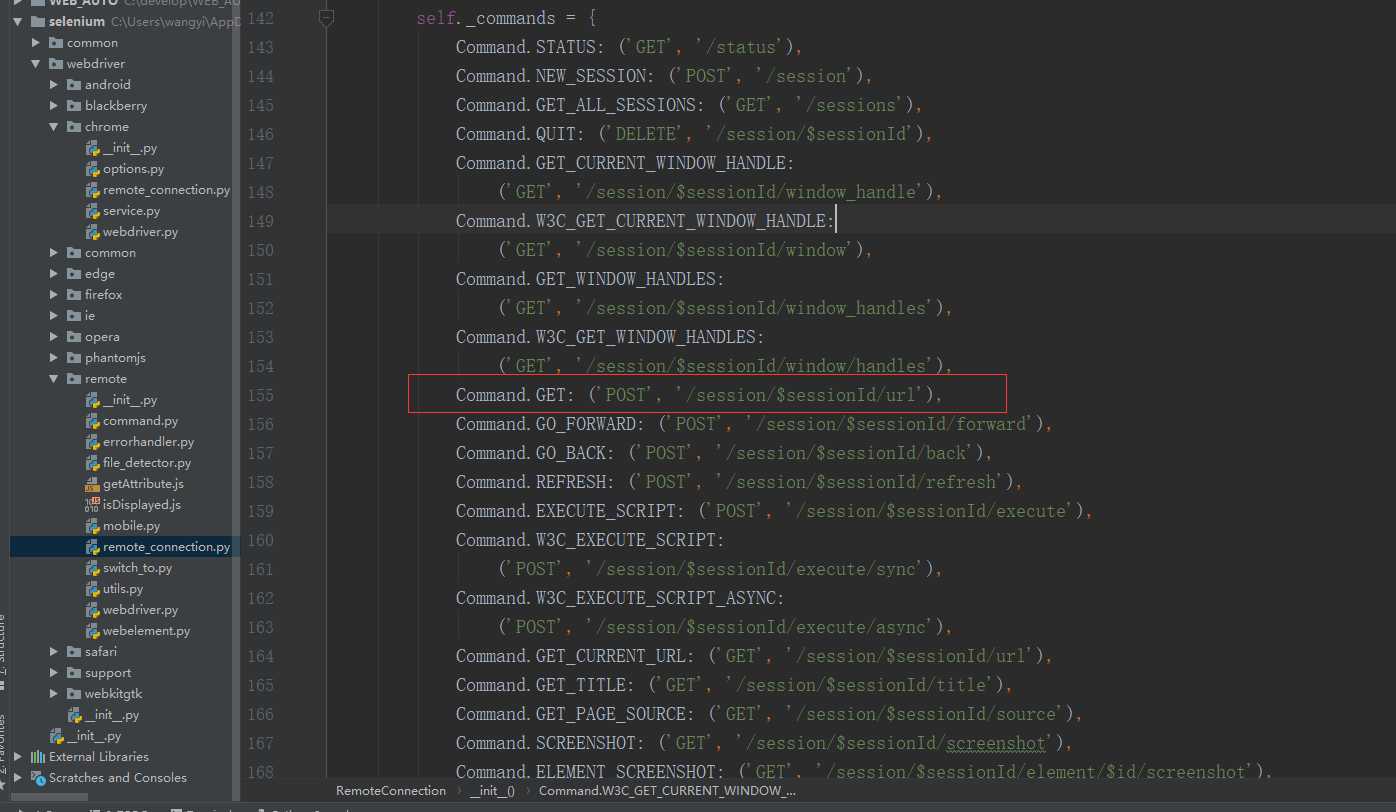
原来发的是post请求,这里使用的是WebDriver wire protocol协议,即JsonWireProtocol,body部分是这个协议规定的JSON格式的字符串。
总的来说,过程还是很复杂的,至少对于我来说。
补充:对于每一条Selenium脚本,一个http请求会被创建并且发送给浏览器的驱动,浏览器驱动中包含了一个HTTP Server,用来接收这些http请求,HTTP Server接收到请求后根据请求来具体操控对应的浏览器,浏览器执行具体的测试步骤,浏览器将步骤执行结果返回给HTTP Server,HTTP Server又将结果返回给Selenium的脚本,如果是错误的http代码我们就会在控制台看到对应的报错信息。
浅谈python中selenium库调动webdriver驱动浏览器的实现原理
标签:自动 request方法 prot 对象 注释 传参 pre mic 应该
原文地址:https://www.cnblogs.com/wangyi0419/p/11353606.html