标签:端口 容器 use targe 目标 bfd external 查看 cluster
项目地址:https://github.com/wise2c-devops/breeze
本次使用开源 Breeze工具部署 Kubernetes 高可用集群。
Breeze项目旨在提供一个可信的、安全的、稳定的Kubernetes集群部署工具,它可以帮助您通过图形化操作界面快捷地在生产环境部署一个或多个Kubernetes集群,而不需要连入互联网环境。
功能简介
Breeze 软件架构简图: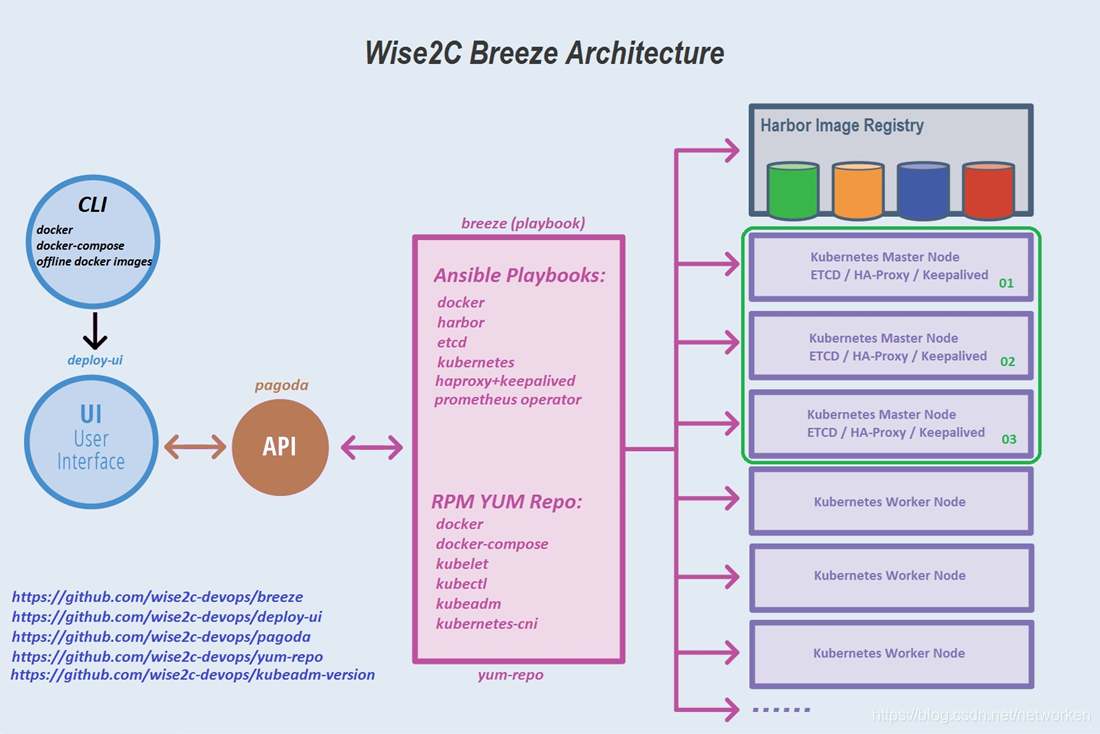
组件
部署要求
在本次实验环境中准备了6台服务器,使用Vmware Workstation进行部署,配置与角色如下(如果需要增加 Minion/Worker 节点请自行准备即可):
| 主机名 | IP 地址 | 角色 | OS | 组件 |
|---|---|---|---|---|
| deploy | 192.168.92.10 | Breeze Deploy | CentOS 7.6 x64 | docker / docker-compose / Breeze |
| master01 | 192.168.92.11 | K8S Master Node | CentOS 7.6 x64 | K8S Master / etcd / HAProxy / Keepalived |
| master02 | 192.168.92.12 | K8S Master Node | CentOS 7.6 x64 | K8S Master / etcd / HAProxy / Keepalived |
| master03 | 192.168.92.13 | K8S Master Node | CentOS 7.6 x64 | K8S Master / etcd / HAProxy / Keepalived |
| worker01 | 192.168.92.21 | K8S Worker Node | CentOS 7.6 x64 | K8S Worker / Prometheus |
| harbor | 192.168.92.20 | Harbor | CentOS 7.6 x64 | Harbor 1.7.0 |
| 192.168.92.30 | VIP | HA 虚 IP 地址在 3 台 K8S Master 浮动 |
硬件资源规划:
| 主机名 | CPU | 内存 | 磁盘 | 网卡 |
|---|---|---|---|---|
| deploy | 1C | 2G | 系统盘50G x1,(可选数据盘300G x1) | x1 |
| master01 | 2C | 4G | 系统盘50G x1,(可选数据盘300G x1) | x1 |
| master02 | 2C | 4G | 系统盘50G x1,(可选数据盘300G x1) | x1 |
| master03 | 2C | 4G | 系统盘50G x1,(可选数据盘300G x1) | x1 |
| worker01 | 2C | 4G | 系统盘50G x1,(可选数据盘300G x1) | x1 |
| harbor | 1C | 2G | 系统盘50G x1,(可选数据盘300G x1) | x1 |
注意master和worker节点至少配置2颗CPU、4G内存,否则可能导致资源不足部署失败。部署前可对所有虚拟机建立快照,方便回滚。
这里仅做测试不配置数据盘(对于集群master和worker节点,磁盘规划建议系统盘/dev/sda和数据盘/dev/sdb组成vg卷组,从卷组划分两个lv逻辑卷分别挂载至/var/lib/docker/目录下和/data目录下。)
deploy节点设置防火墙
关闭selinux并放开firewalld,请勿禁用firewalld服务,保证firewalld服务正常运行状态即可。
setenforce 0 sed --follow-symlinks -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config firewall-cmd --set-default-zone=trusted firewall-cmd --complete-reload
部署节点环境准备(deploy/192.168.92.10)
以下所有操作在部署节点执行
安装 docker-compose
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose
安装 docker
$ curl -sSL https://raw.githubusercontent.com/willzhang/shell/master/install_docker.sh | sh
在部署机上做好对集群内其它所有服务器的ssh免密登录:
#生成密钥 $ ssh-keygen #针对目标服务器做 ssh 免密登录,依次执行:
$ ssh-copy-id 192.168.92.11 $ ssh-copy-id 192.168.92.12 $ ssh-copy-id 192.168.92.13 $ ssh-copy-id 192.168.92.20 $ ssh-copy-id 192.168.92.21
下载用于部署某个Kubernetes版本的docker-compose文件并使部署程序运行起来,例如此次实验针对刚刚发布的 K8S v1.13.2。
$ curl -L https://raw.githubusercontent.com/wise2c-devops/breeze/v1.13.2/docker-compose.yml -o docker-compose.yml $ docker-compose up -d
查看拉取的镜像
[root@deploy ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE wise2c/playbook v1.13.2 6c57dc3440b1 3 days ago 1.17GB wise2c/yum-repo v1.13.2 d08304a41136 5 days ago 745MB wise2c/pagoda v1.1 d4f2b4cabdec 13 days ago 483MB wise2c/deploy-ui v1.3 2f159b37bf13 2 weeks ago 40.1MB
查看运行的容器
如果一切正常(注意deploy-playbook这个容器是个卷容器,它是退出状态这是正常现象),部署机的88端口将能够被正常访问。
[root@deploy ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0221f2177505 wise2c/deploy-ui:v1.3 "/root/entrypoint.sh" 8 minutes ago Up 8 minutes deploy-ui cd24a52cd499 wise2c/pagoda:v1.1 "sh -c ‘/root/pagoda…" 8 minutes ago Up 8 minutes 0.0.0.0:88->80/tcp, 0.0.0.0:8088->8080/tcp deploy-main a0dcf2bc42e6 wise2c/playbook:v1.13.2 "sh" 8 minutes ago Exited (0) 8 minutes ago deploy-playbook b1f92f68fffa wise2c/yum-repo:v1.13.2 "nginx -g ‘daemon of…" 8 minutes ago Up 8 minutes 80/tcp, 0.0.0.0:2009->2009/tcp deploy-yumrepo [root@deploy ~]#
打开浏览器,访问部署程序的图形界面(部署机 IP 及端口 88),添加主机列表、添加服务角色并将加入的主机进行角色分配,然后开始部署:http://192.168.92.10:88
点击 + 号添加一个集群:
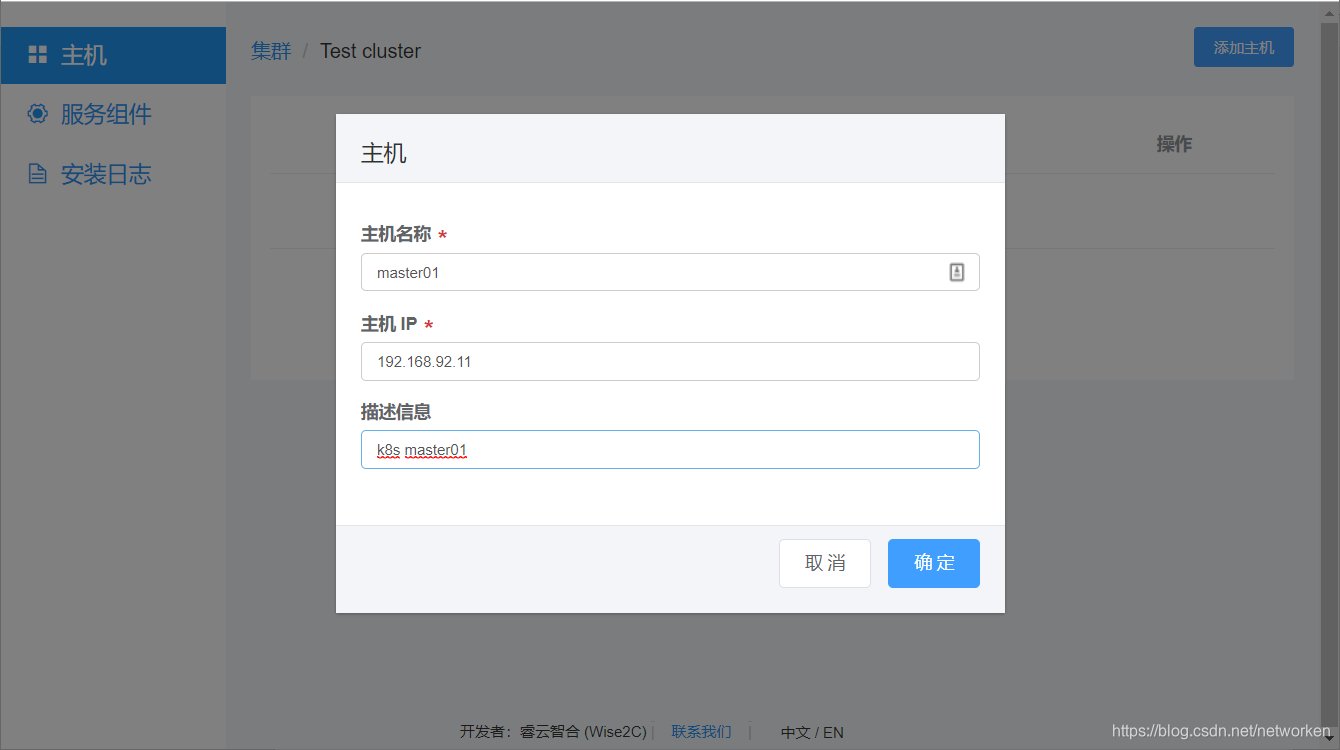
点击“添加主机”,输入主机名、主机IP、描述信息(主机用途),点击确定。重复该步骤直至将集群所需的全部节点服务器加入(k8s master服务器、k8s worker node服务器、harbor服务器等等):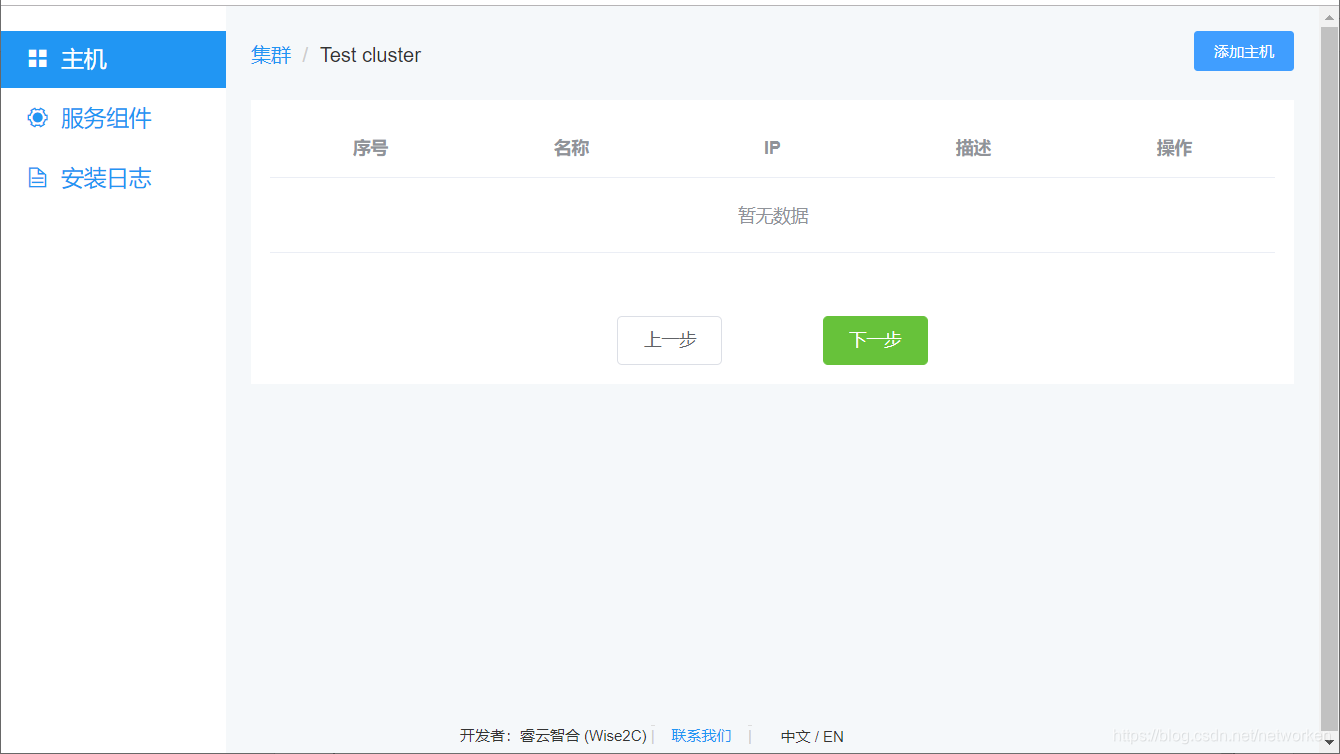
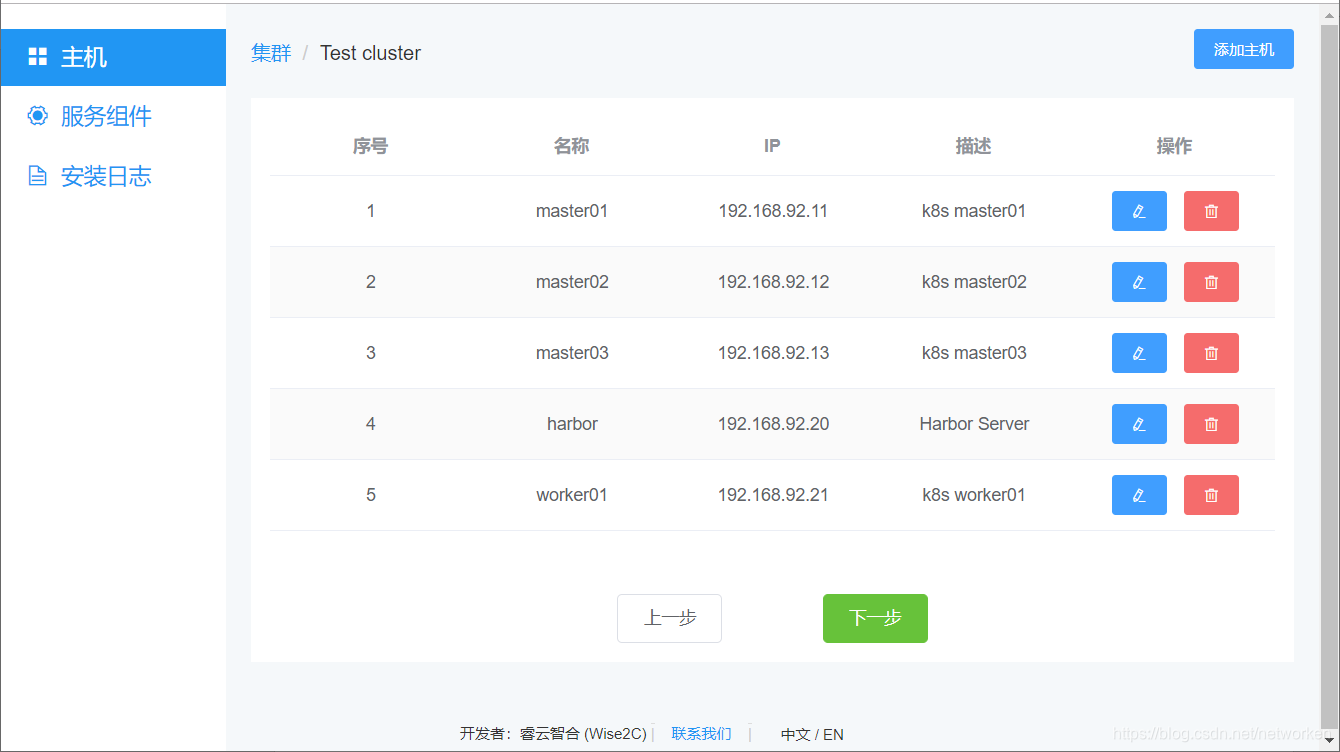
点击“下一步”再点击“添加组件”按钮,对每个组件进行设置和分配服务器(docker角色、harbor角色、loadbalance角色、etcd角色、kubernetes角色、prometheus角色):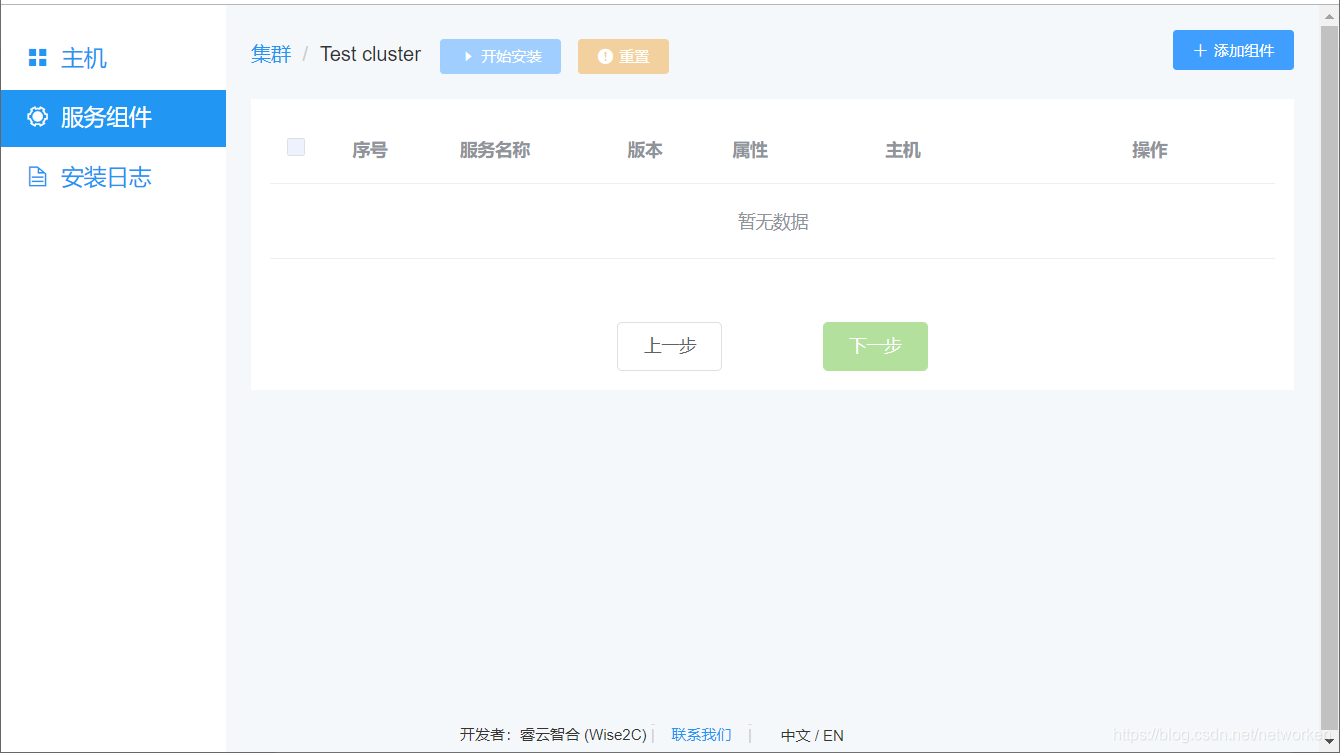
如果希望Breeze部署程序使用界面里输入的主机名代替当前服务器的主机名,则勾选format host name选项框: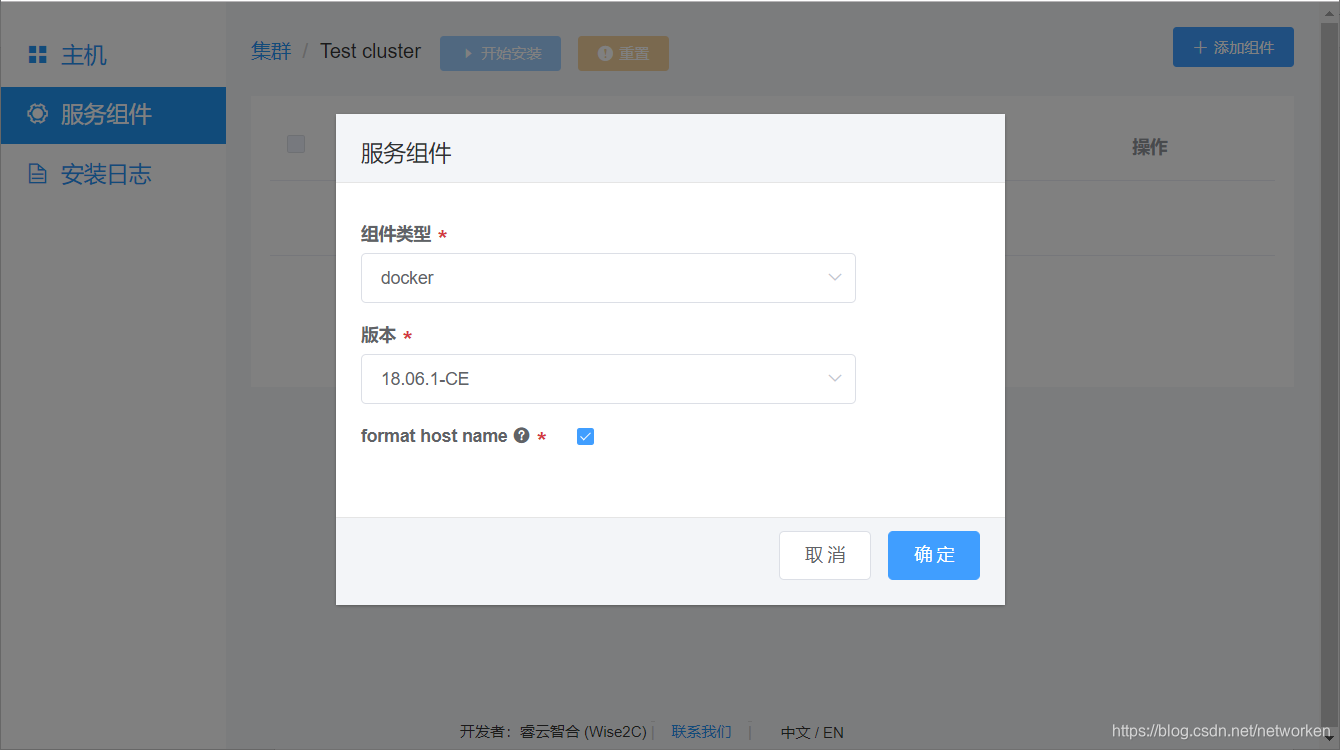
镜像仓库设置这里的harbor entry point是指用户端访问镜像仓库的URL,可以直接写IP地址或写对应的域名: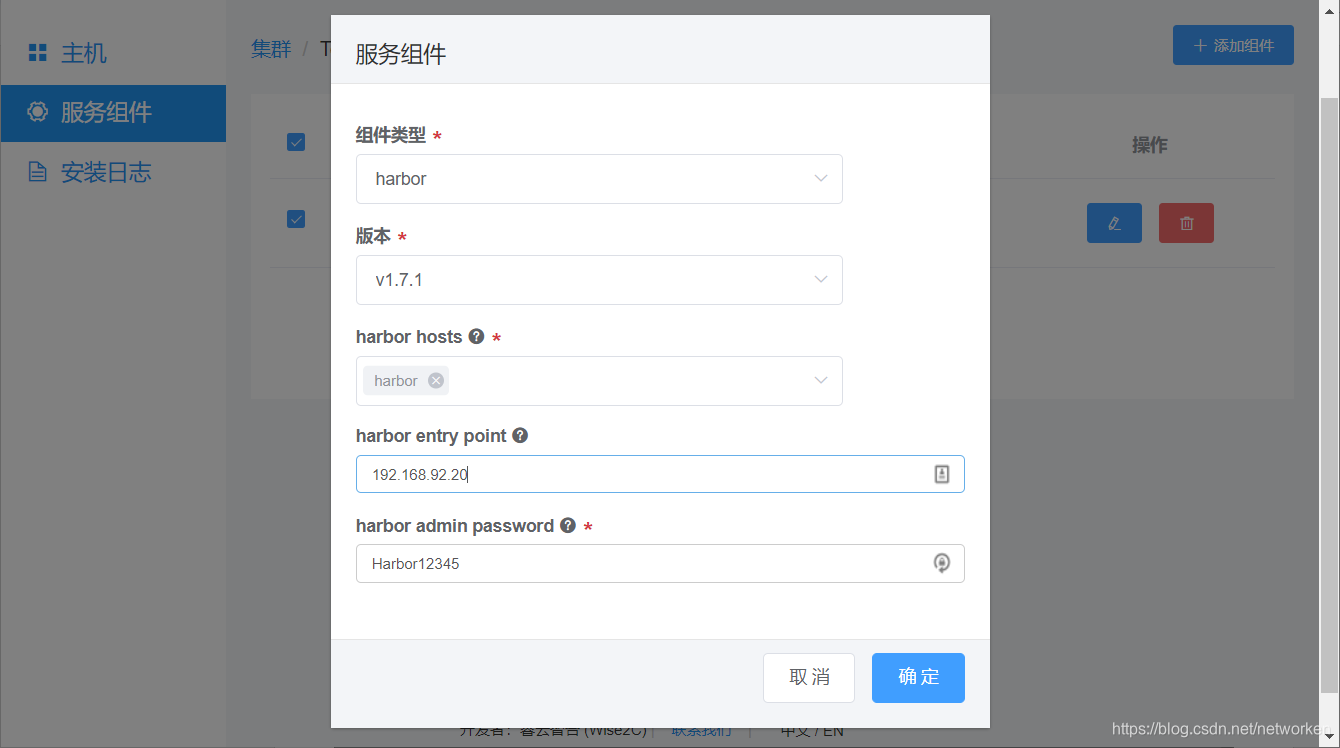
接下来是设置高可用组件(haproxy+keepalived):
vip for k8s master是指三个k8s master服务器的高可用虚拟浮动IP地址;网卡请填写实际操作系统下的网卡名,注意请保证3个节点网卡名一致;router id和virtual router id请确保不同k8s集群使用不同的值。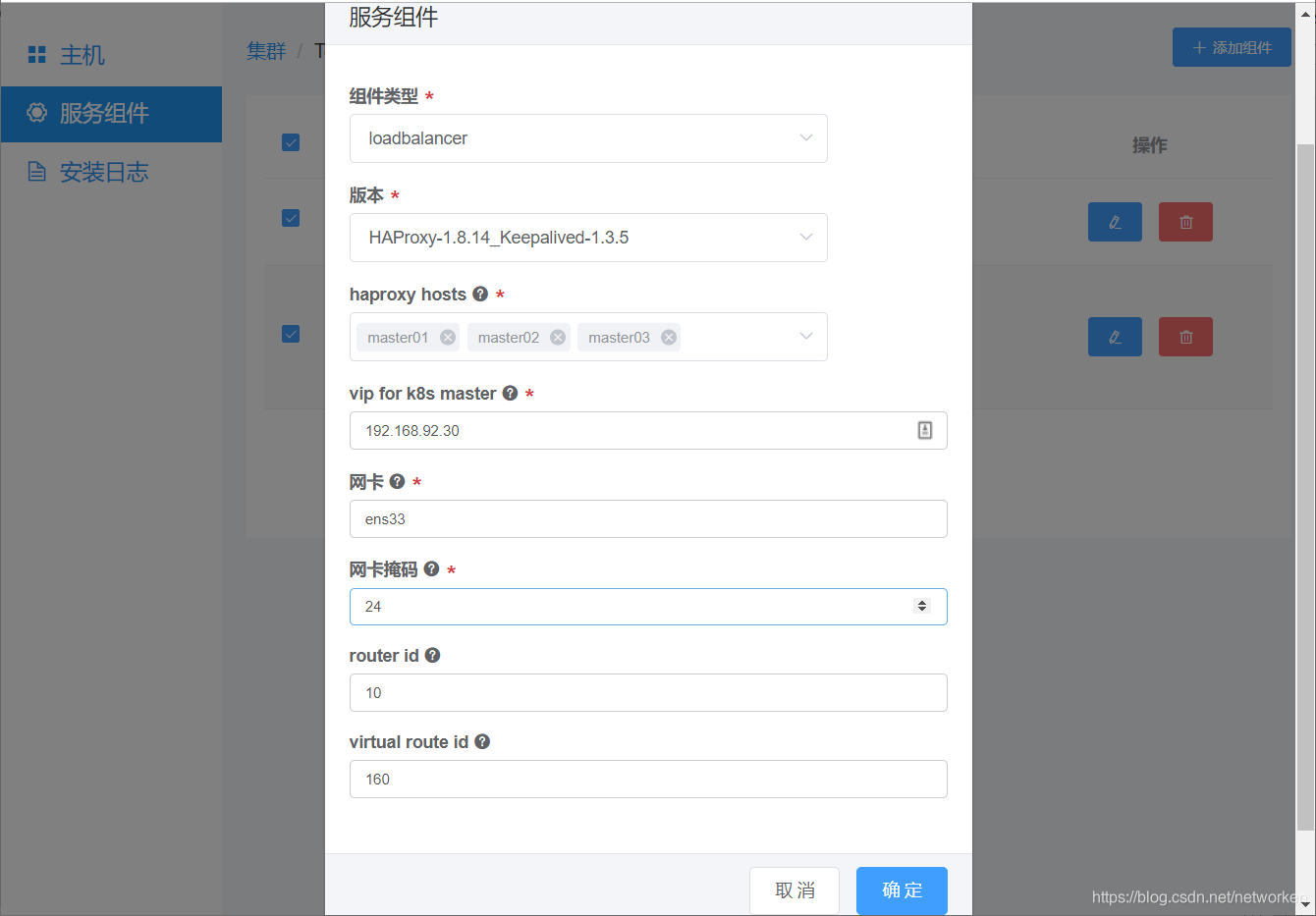
Etcd可以选择部署于K8S Master节点也可以选择独立的三台主机: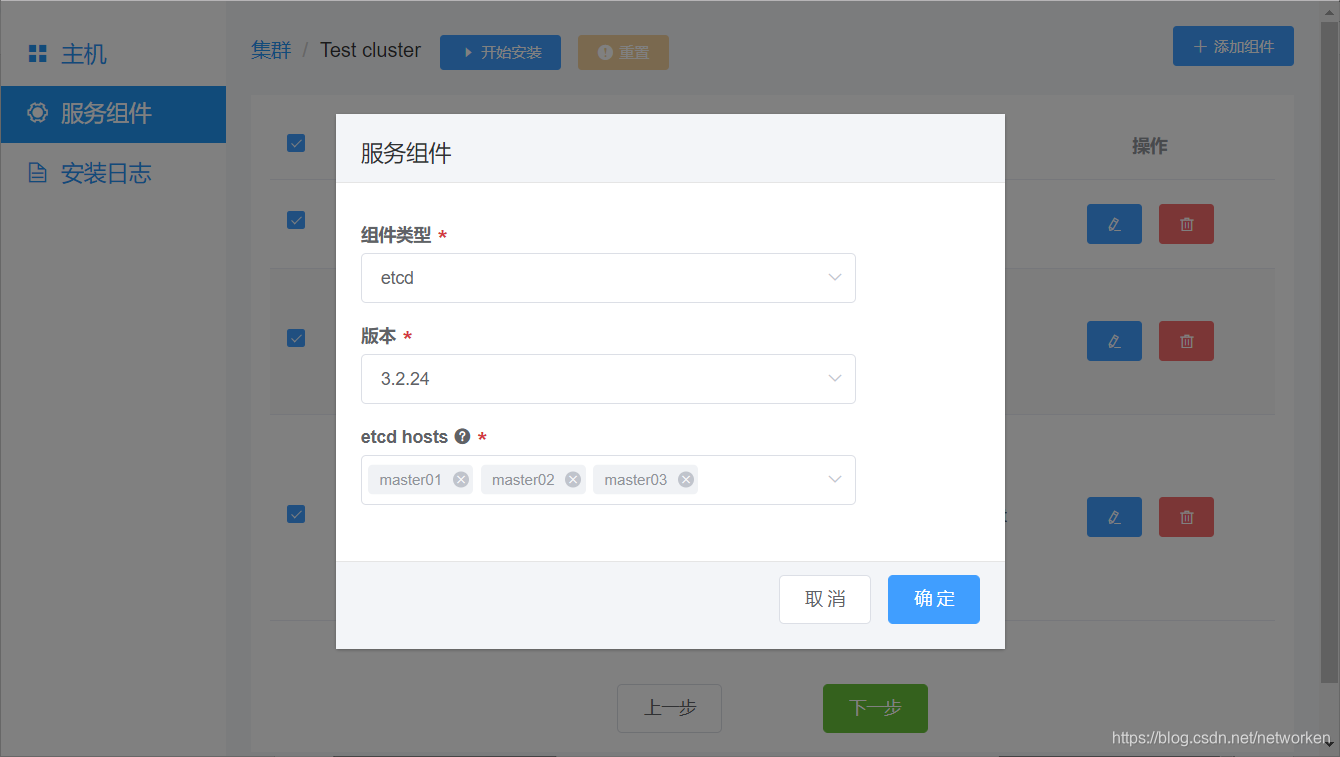
kubernetes entry point是指高可用的一个设定值,如果生产环境有硬件或软件负载均衡指向这里的k8s master所有节点,那么就可以在这里填写负载均衡的统一入口地址。
相对于昂贵的F5专业硬件设备,我们也可以使用HAProxy和Keepalived的组合轻松完成这个设置,Breeze自带这个组合模块的部署。
例如下图的 192.168.92.30:6444 就是k8s集群高可用的统一入口,k8s的worker node会使用这个地址访问API Server。请注意如果使用的是Breeze自带的高可用组件haproxy+keepalived,则请填写实际的虚IP与默认端口6444。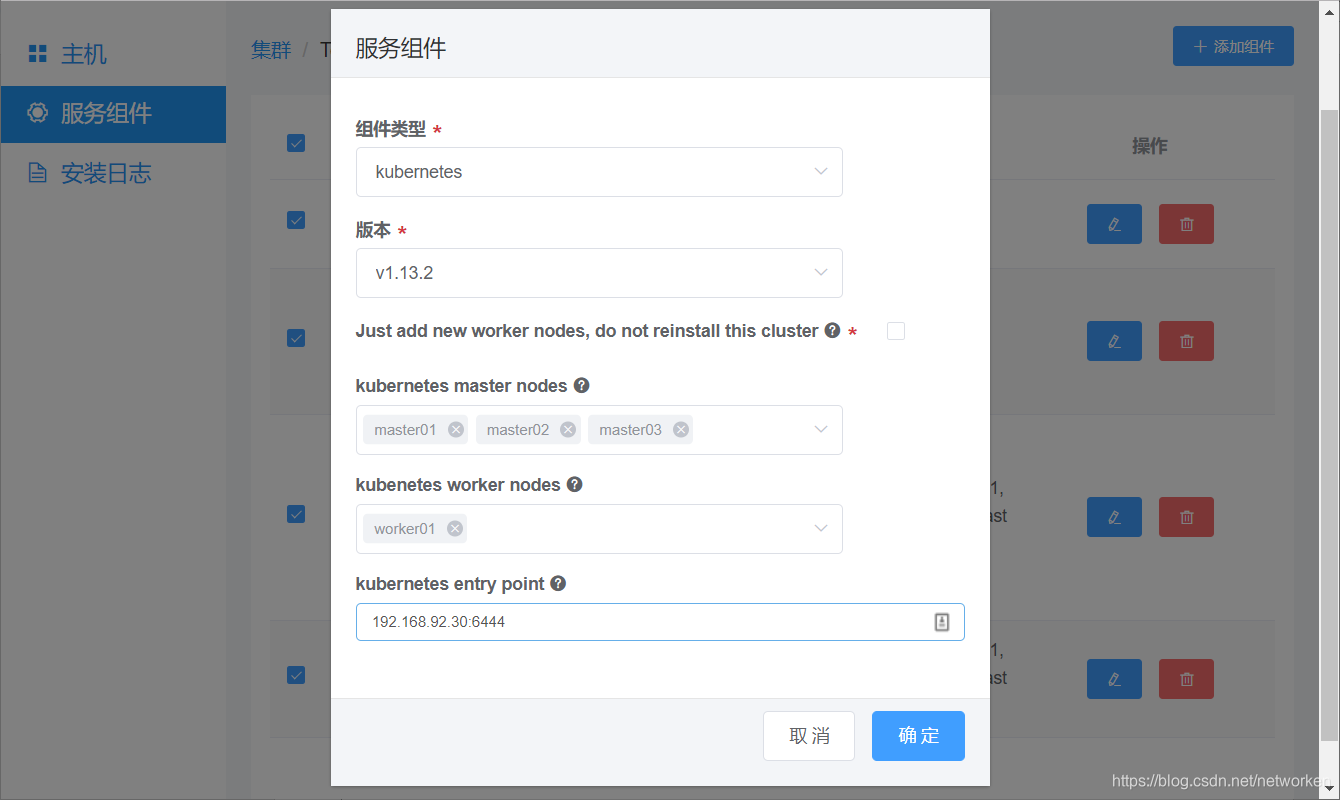
接下来是可选安装项Prometheus(基于Prometheus Operator方式部署,集成Prometheus、Alertmanager、Grafana),这里请择一台Worker节点进行部署即可,有三个服务暴露端口可自行设定,注意NodePort端口号大于30000。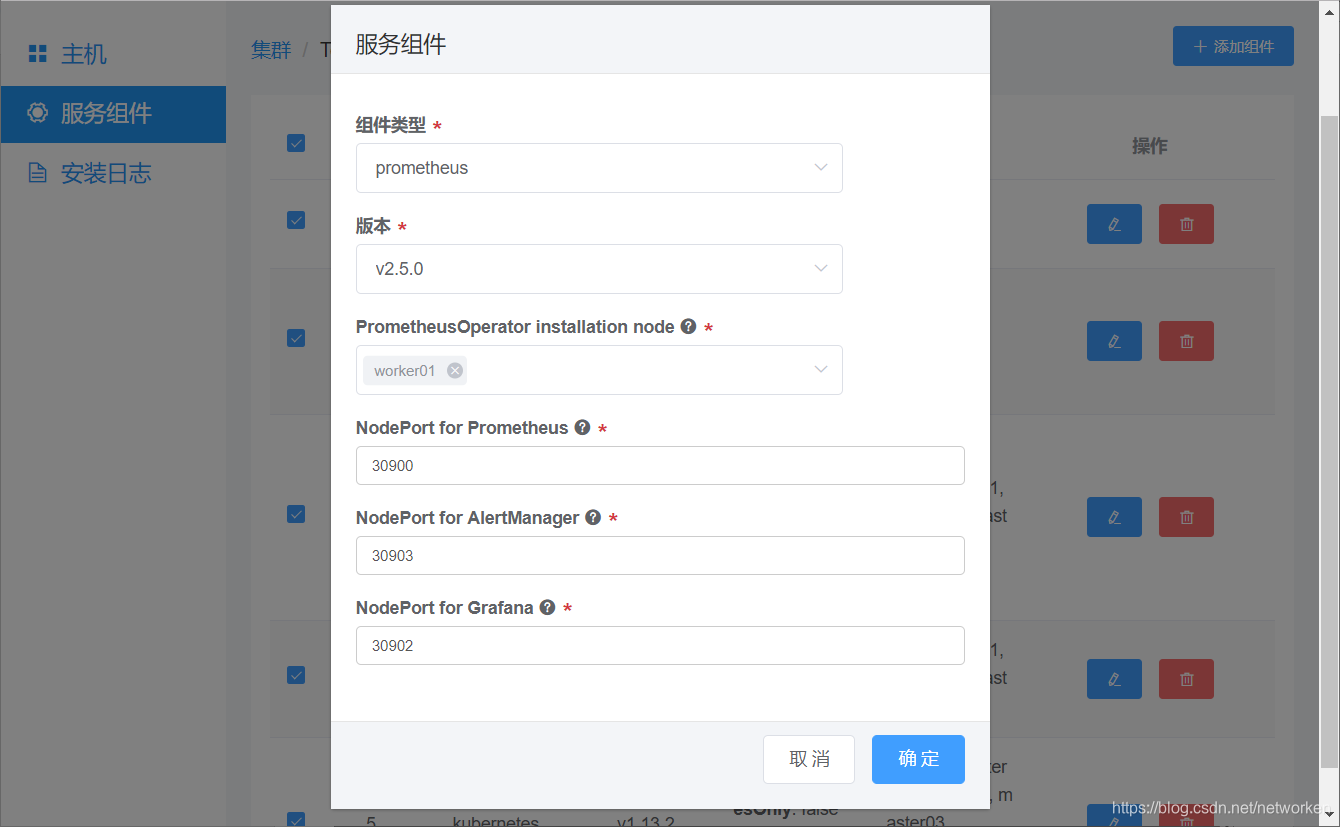
所有角色定义完成如下: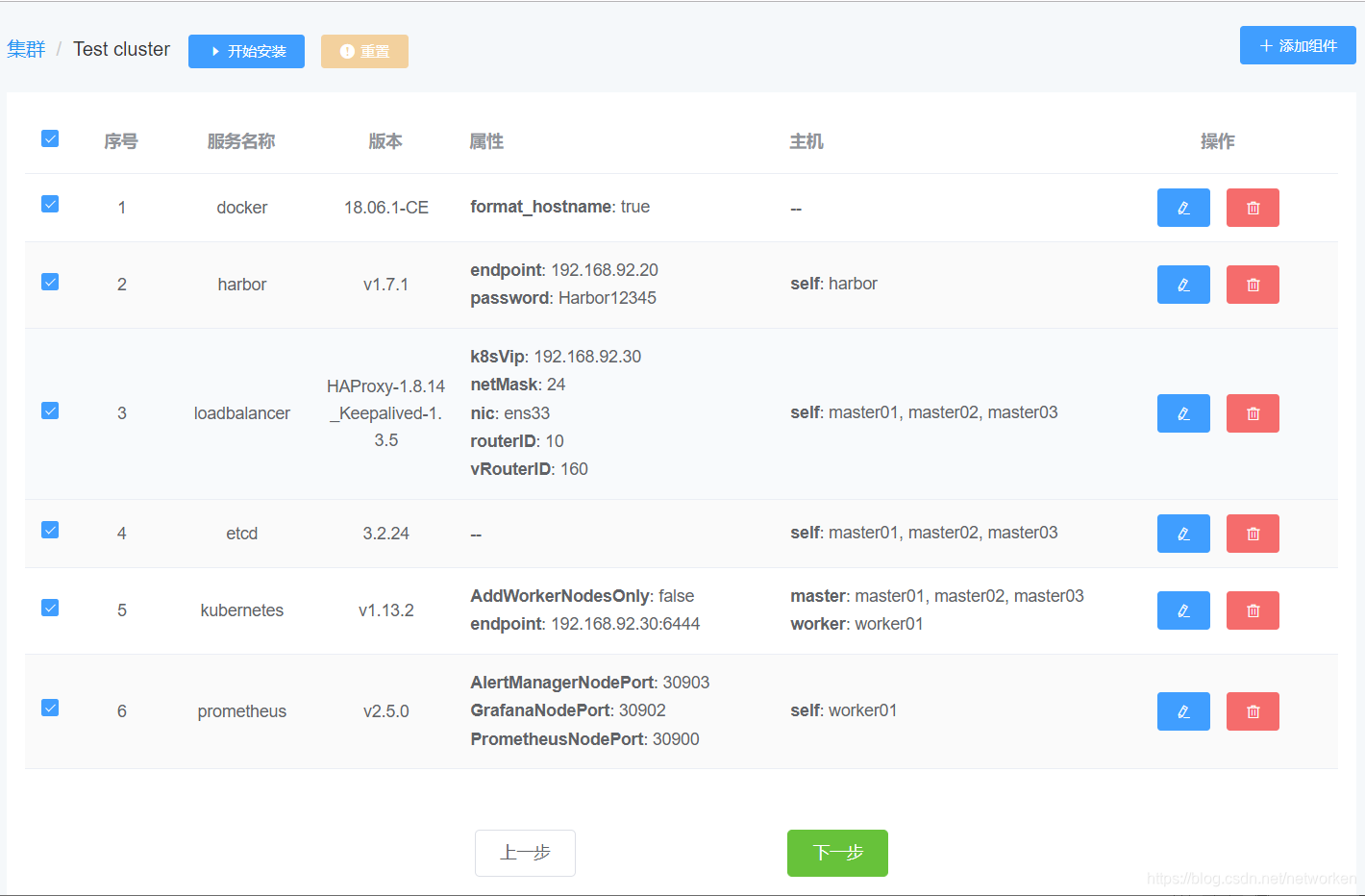
点击“下一步”开始安装部署。
如果界面上所有角色图标全部变为绿色,则表示部署任务结束。可以登录任一k8s节点运行命令 kubectl get nodes 查看结果。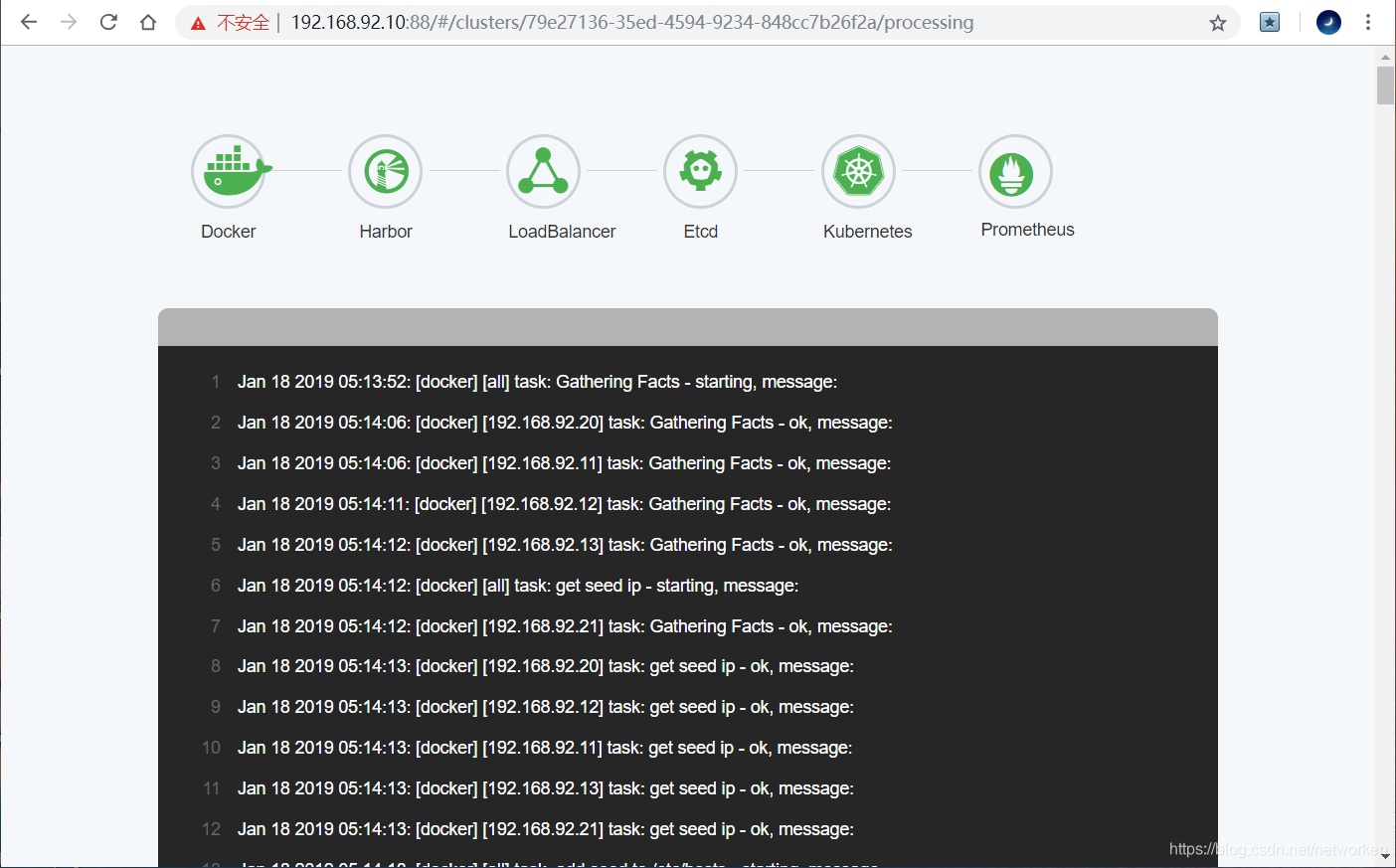
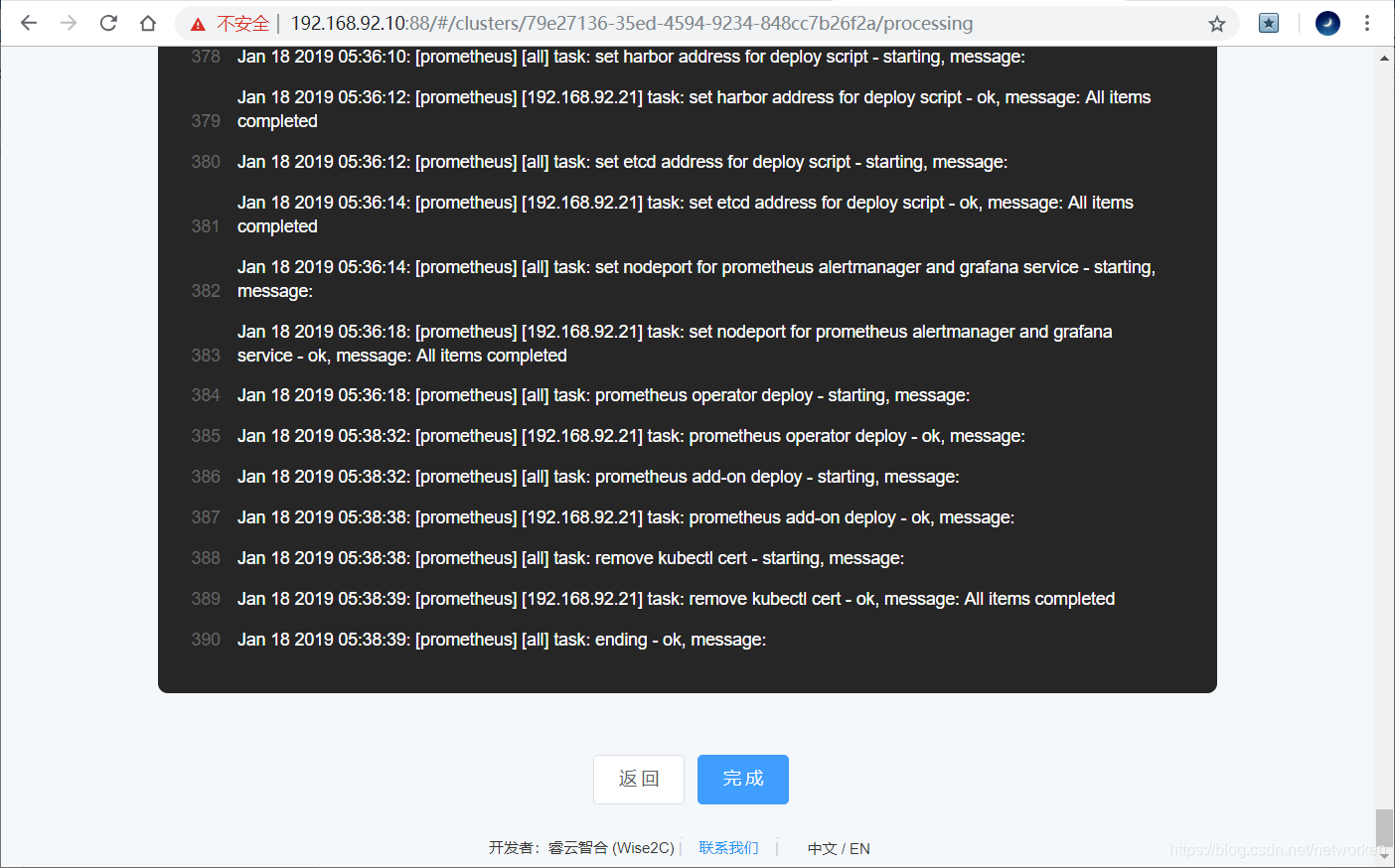
以上例子是3台etcd、3台k8s master、1台k8s worker node、1台镜像仓库的环境。实际可以增减规模。
Kubernetes Dashboard的访问入口我们采用了NodePort:30300的方式暴露端口,因此可以通过火狐浏览器访问 https://任意服务器IP:30300 来登录Dashboard页面,注意其它浏览器例如Chrome因为不接受自签名证书会拒绝访问请求。
新版本Dashboard引入了验证模式,可以通过以下命令获取admin-user的访问令牌:
$ kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk ‘{print $1}‘)
将返回的token字串粘贴至登录窗口即可实现登录。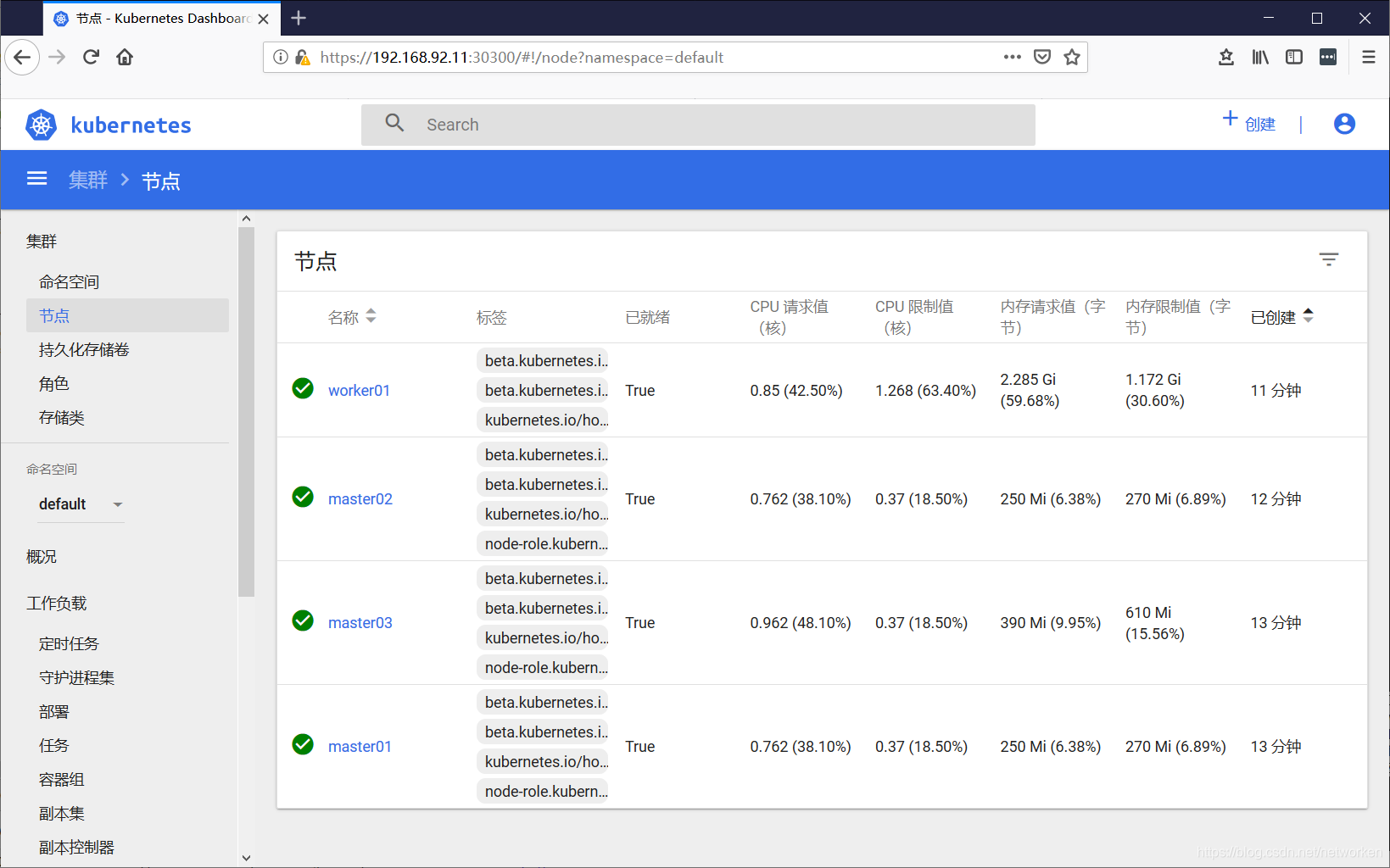
安装好Prometheus之后,可以访问以下服务页面:
Grafana:
用户名密码默认为admin/admin
这里使用ID 315的dashboard模板进行展示: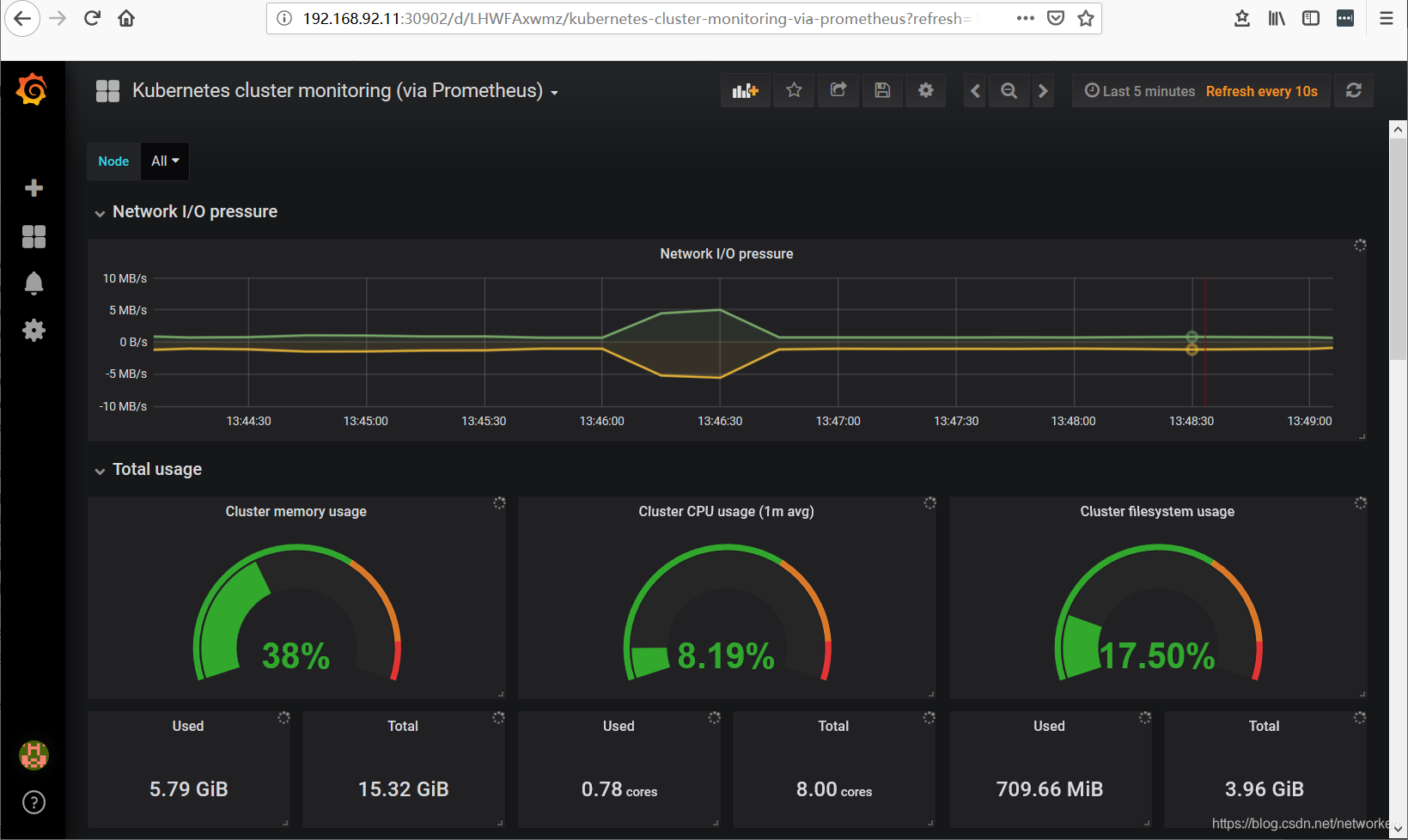
Prometheus:
http://任意服务器IP:30900
Alertmanager:
http://任意服务器IP:30903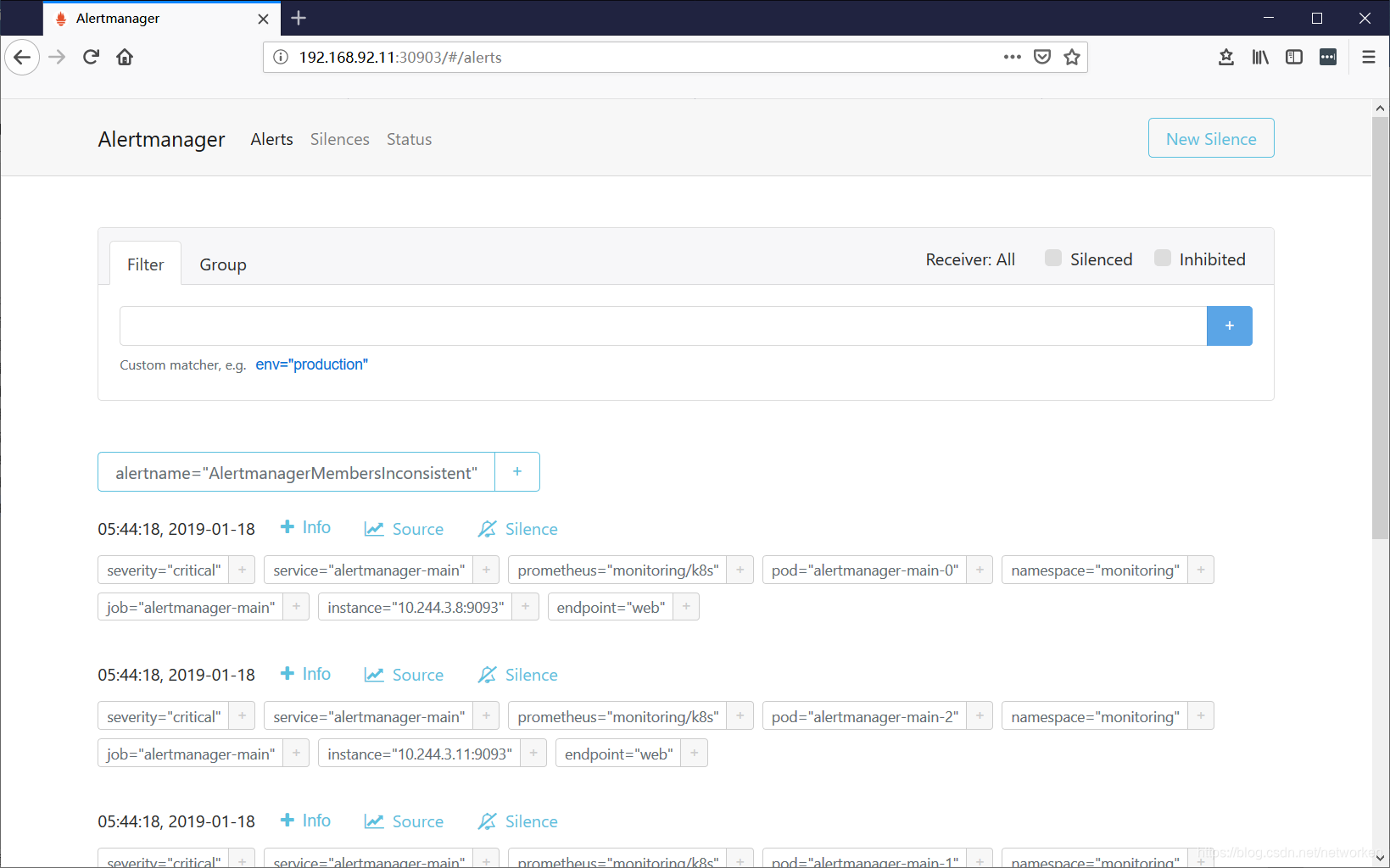
默认用户名密码admin/Harbor12345 登录成功:
登录成功:
查看集群状态:
[root@master01 ~]# kubectl get cs NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-1 Healthy {"health": "true"} etcd-2 Healthy {"health": "true"} etcd-0 Healthy {"health": "true"} [root@master01 ~]#
查看节点状态:
[root@master01 ~]# kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME master01 Ready master 25m v1.13.2 192.168.92.11 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 master02 Ready master 24m v1.13.2 192.168.92.12 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 master03 Ready master 24m v1.13.2 192.168.92.13 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 worker01 Ready <none> 23m v1.13.2 192.168.92.21 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 [root@master01 ~]#
查看集群组件pod状态:
[root@master01 ~]# kubectl -n kube-system get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-8595b69b-25nqs 1/1 Running 0 25m 10.244.1.2 master03 <none> <none> coredns-8595b69b-dfzwz 1/1 Running 0 25m 10.244.1.3 master03 <none> <none> kube-apiserver-master01 1/1 Running 0 25m 192.168.92.11 master01 <none> <none> kube-apiserver-master02 1/1 Running 0 24m 192.168.92.12 master02 <none> <none> kube-apiserver-master03 1/1 Running 0 24m 192.168.92.13 master03 <none> <none> kube-controller-manager-master01 1/1 Running 0 24m 192.168.92.11 master01 <none> <none> kube-controller-manager-master02 1/1 Running 0 24m 192.168.92.12 master02 <none> <none> kube-controller-manager-master03 1/1 Running 0 24m 192.168.92.13 master03 <none> <none> kube-flannel-ds-6v625 1/1 Running 0 24m 192.168.92.13 master03 <none> <none> kube-flannel-ds-8p8m7 1/1 Running 0 24m 192.168.92.12 master02 <none> <none> kube-flannel-ds-m4ppq 1/1 Running 0 23m 192.168.92.21 worker01 <none> <none> kube-flannel-ds-xrmd2 1/1 Running 0 24m 192.168.92.11 master01 <none> <none> kube-proxy-bh4vl 1/1 Running 0 25m 192.168.92.13 master03 <none> <none> kube-proxy-cq4fc 1/1 Running 0 23m 192.168.92.21 worker01 <none> <none> kube-proxy-dz6l2 1/1 Running 0 25m 192.168.92.12 master02 <none> <none> kube-proxy-qkmq8 1/1 Running 0 25m 192.168.92.11 master01 <none> <none> kube-scheduler-master01 1/1 Running 0 24m 192.168.92.11 master01 <none> <none> kube-scheduler-master02 1/1 Running 0 24m 192.168.92.12 master02 <none> <none> kube-scheduler-master03 1/1 Running 0 24m 192.168.92.13 master03 <none> <none> kubernetes-dashboard-6f9bfdf8cb-rn6wd 1/1 Running 0 24m 10.244.1.4 master03 <none> <none> [root@master01 ~]#
查看prometheus相关pod
[root@master01 ~]# kubectl -n monitoring get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES alertmanager-main-0 2/2 Running 0 19m 10.244.3.8 worker01 <none> <none> alertmanager-main-1 2/2 Running 0 19m 10.244.3.10 worker01 <none> <none> alertmanager-main-2 2/2 Running 0 19m 10.244.3.11 worker01 <none> <none> grafana-5c59c6fb9c-78ng5 1/1 Running 0 20m 10.244.3.4 worker01 <none> <none> kube-state-metrics-565c6647f7-sc8d5 4/4 Running 0 20m 10.244.3.5 worker01 <none> <none> node-exporter-5hdqk 2/2 Running 0 20m 192.168.92.21 worker01 <none> <none> node-exporter-nxllq 2/2 Running 0 20m 192.168.92.11 master01 <none> <none> node-exporter-q2znp 2/2 Running 0 20m 192.168.92.12 master02 <none> <none> node-exporter-shdt8 2/2 Running 0 20m 192.168.92.13 master03 <none> <none> prometheus-adapter-68c9d7dc54-bb9t4 1/1 Running 0 20m 10.244.3.6 worker01 <none> <none> prometheus-k8s-0 3/3 Running 1 19m 10.244.3.9 worker01 <none> <none> prometheus-k8s-1 3/3 Running 1 19m 10.244.3.7 worker01 <none> <none> prometheus-operator-5fcf4d9b4d-qkpb8 1/1 Running 0 20m 10.244.3.2 worker01 <none> <none> [root@master01 ~]#
查看service
[root@master01 ~]# kubectl get service -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE coredns-prometheus ClusterIP None <none> 9153/TCP 23m kube-controller-manager-prometheus-discovery ClusterIP None <none> 10252/TCP 23m kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 30m kube-scheduler-prometheus-discovery ClusterIP None <none> 10251/TCP 23m kubelet ClusterIP None <none> 10250/TCP 21m kubernetes-dashboard NodePort 10.99.39.217 <none> 8443:30300/TCP 30m [root@master01 ~]# kubectl get service -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main NodePort 10.101.39.236 <none> 9093:30903/TCP 24m alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 23m etcd-k8s ClusterIP None <none> 2379/TCP 23m grafana NodePort 10.110.93.179 <none> 3000:30902/TCP 24m kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 24m node-exporter ClusterIP None <none> 9100/TCP 24m prometheus-adapter ClusterIP 10.105.49.184 <none> 443/TCP 24m prometheus-k8s NodePort 10.103.34.132 <none> 9090:30900/TCP 24m prometheus-operated ClusterIP None <none> 9090/TCP 23m prometheus-operator ClusterIP None <none> 8080/TCP 24m [root@master01 ~]#
在已经部署的集群内添加新的Worker Nodes。
准备worker节点,执行之前部署环境准备的配置相关步骤,配置主机名,配置ssh免密登录等。
(1) 在Breeze界面添加主机(设定主机名、IP地址、备注)。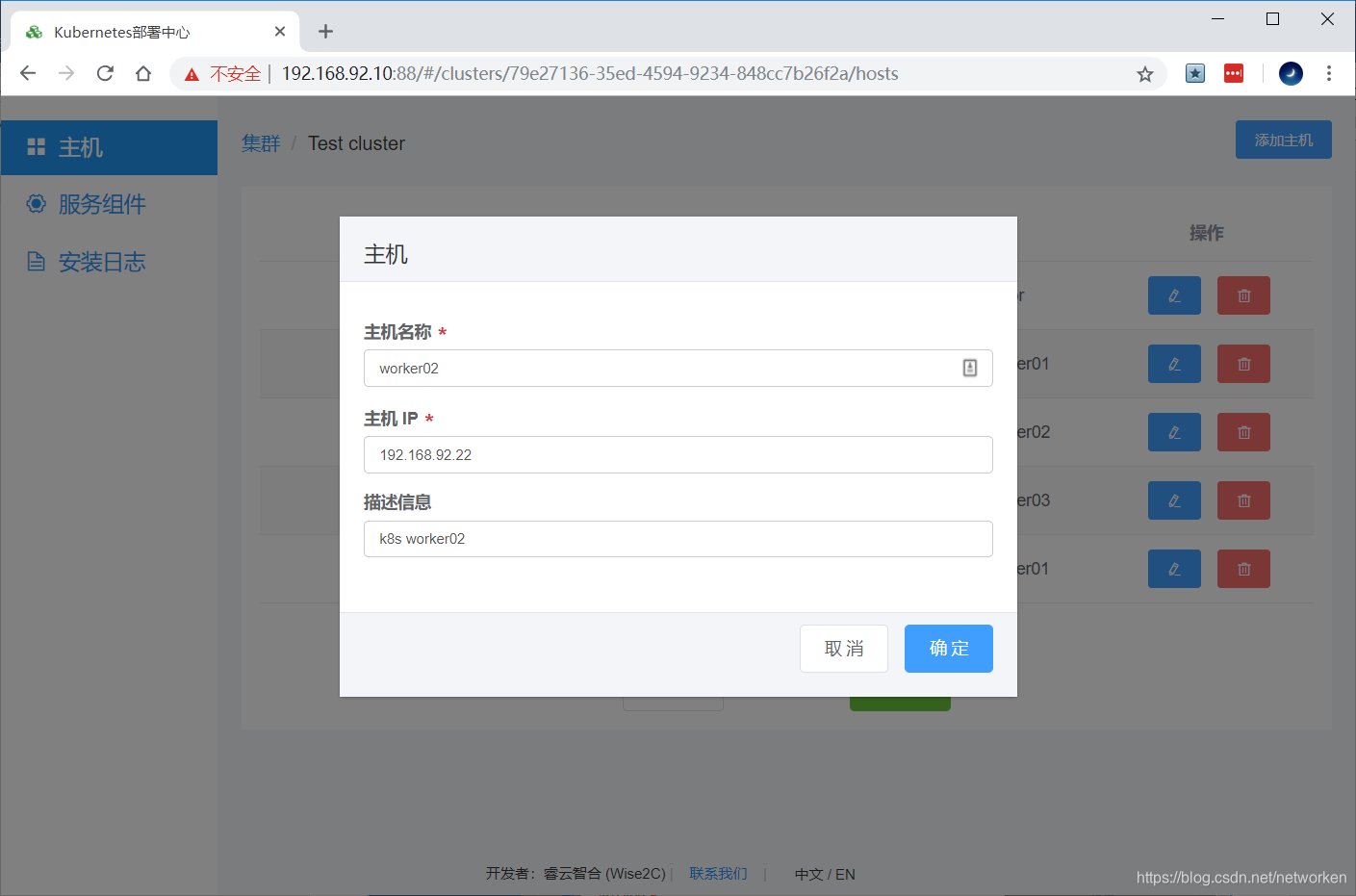
(2) 在Breeze界面编辑Kubernetes角色,将新主机加入到kubernetes worker nodes列表并勾选"Just add new worker nodes, do not reinstall this cluster"。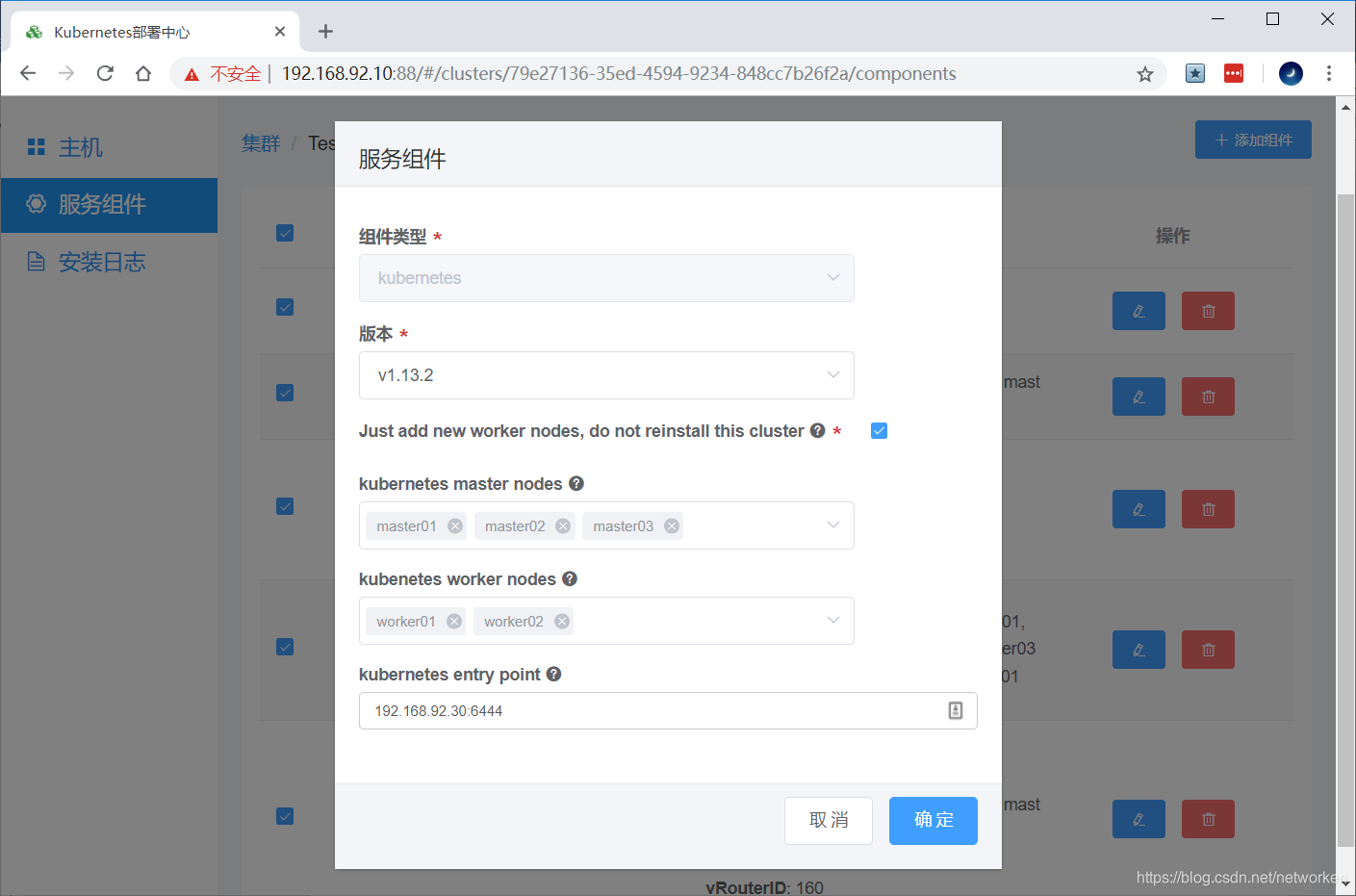
(3) 在Breeze界面仅仅勾选Docker和Kubernetes并开始部署。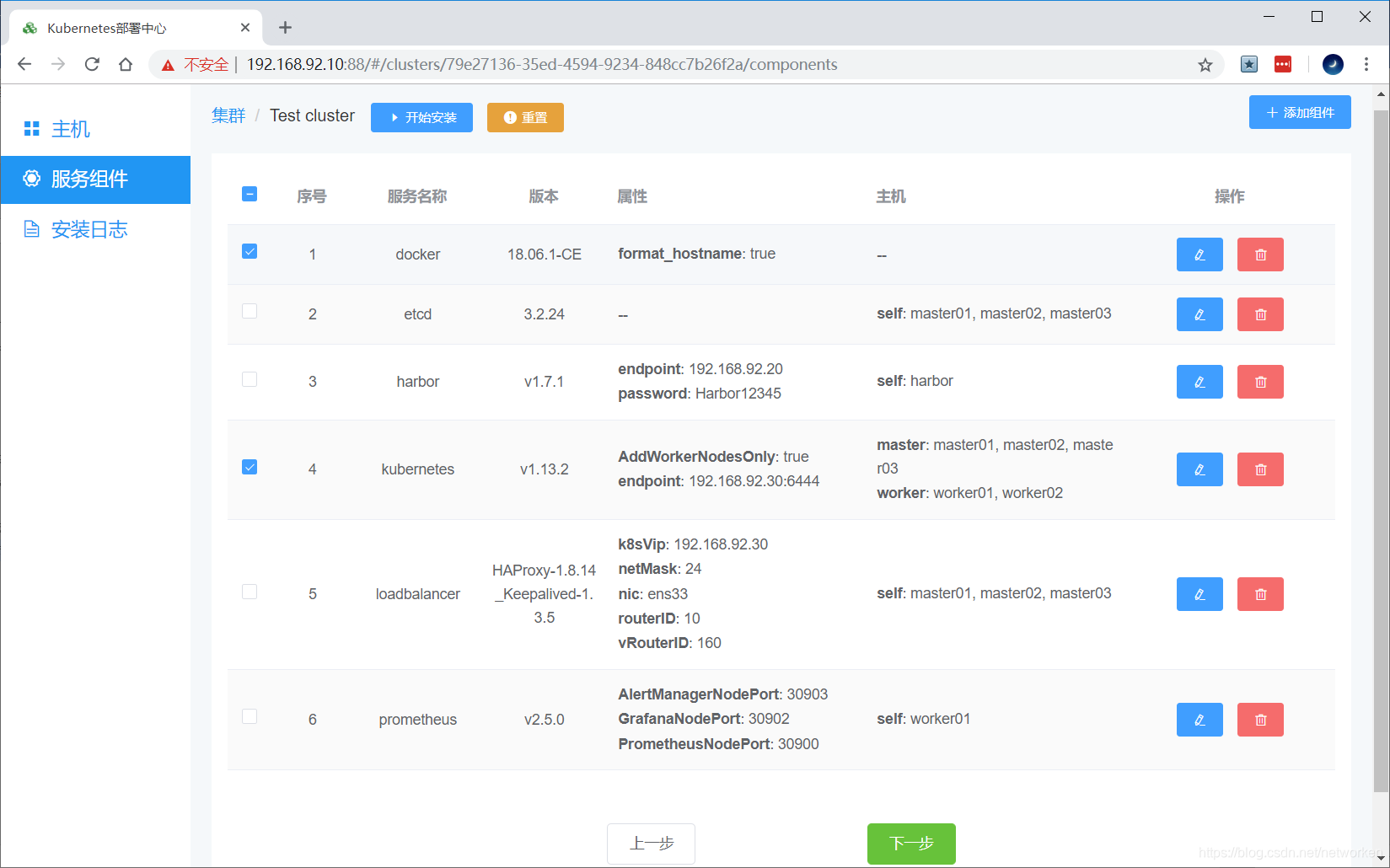
添加节点完成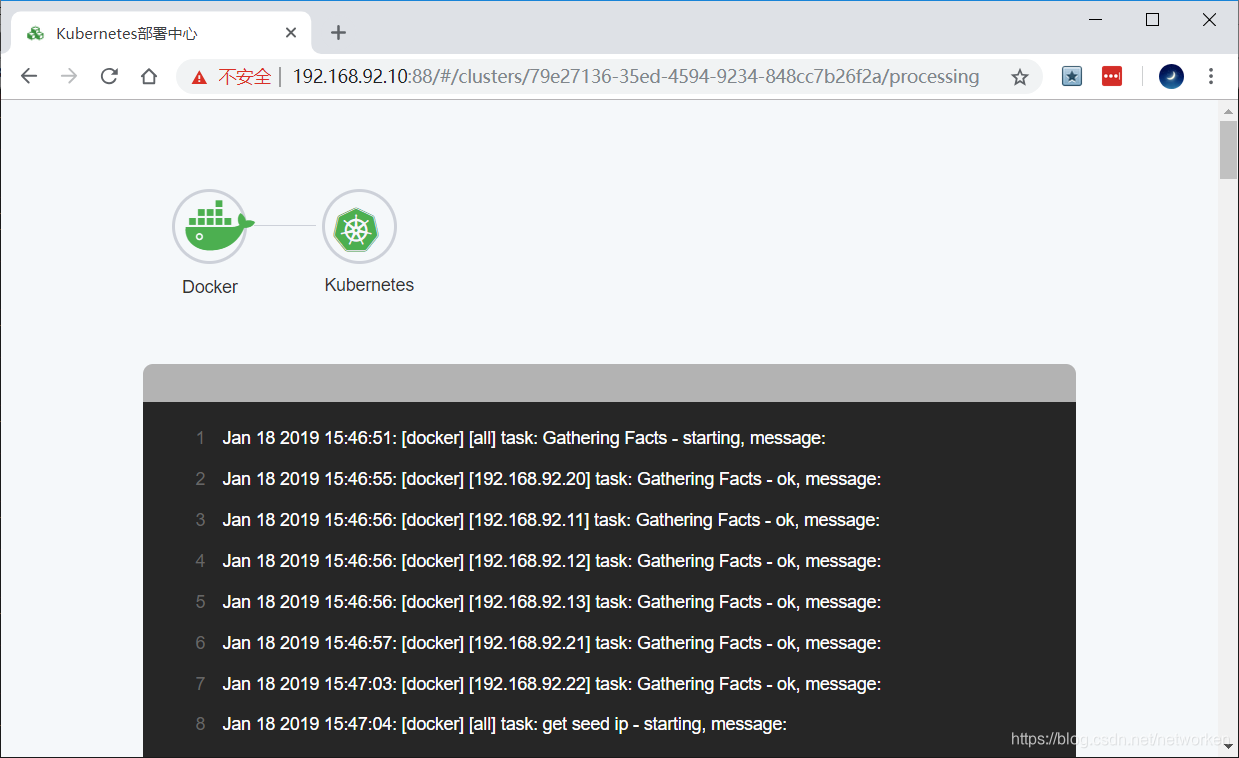
查看节点状态
[root@master01 ~]# kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME master01 Ready master 10h v1.13.2 192.168.92.11 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 master02 Ready master 10h v1.13.2 192.168.92.12 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 master03 Ready master 10h v1.13.2 192.168.92.13 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 worker01 Ready <none> 10h v1.13.2 192.168.92.21 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 worker02 Ready <none> 4m48s v1.13.2 192.168.92.22 <none> CentOS Linux 7 (Core) 4.20.2-1.el7.elrepo.x86_64 docker://18.6.1 [root@master01 ~]#
手动删除节点
在Master节点上运行:
[root@master01 ~]# kubectl drain worker02 --delete-local-data --force --ignore-daemonsets [root@master01 ~]# kubectl delete node worker02 node "worker02" deleted [root@master01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready master 10h v1.13.2 master02 Ready master 10h v1.13.2 master03 Ready master 10h v1.13.2 worker01 Ready <none> 10h v1.13.2 [root@master01 ~]#
上面两条命令执行完成后,在k8s-node2节点执行清理命令,重置kubeadm的安装状态:
[root@worker02 ~]# kubeadm reset在master上删除node并不会清理k8s-node2运行的容器,需要在删除节点上面手动运行清理命令。
常见故障排错方法
参考:https://github.com/wise2c-devops/breeze/blob/master/TroubleShooting-CN.md
前端Web UI的日志如果不能判断出具体问题所在,可以在部署机上输入以下命令来获取更详细的日志:
[root@deploy ~]# docker logs -f deploy-main[转帖]Breeze部署kubernetes1.13.2高可用集群
标签:端口 容器 use targe 目标 bfd external 查看 cluster
原文地址:https://www.cnblogs.com/jinanxiaolaohu/p/11320586.html