标签:镜像 读数 性能 价格变化 mem add 实现 备份 后台
对强一致要求比较高的,应采用实时同步方案,即查询缓存查询不到再从DB查询,保存到缓存;
更新缓存时,先更新数据库,再将缓存的设置过期(建议不要去更新缓存内容,直接设置缓存过期)。
为什么不去更新缓存内容,而是设置缓存过期呢?
答:我们先来了解两个概念
1.1. 缓存穿透
缓存穿透是指查询一个数据库中一定不存在的数据,由于缓存是不命中时需要从数据库中查询,查不到数据则不写入缓存,这就将导致这个不存在的数据每次请求都要到数据库中查询,造成缓存穿透。
你可以通俗的理解,直接把缓存穿透了,没有利用到缓存。。。
举例:
If(redis存在此key){
查询redis值
}else{
查询数据库,如果能查到数据,就写入到redis中
}
这一段代码逻辑就会造成缓存穿透的恶果。。
你想,假设这个查询数据库中永远没有值,那么这个redis中这个key是不是就不会创建,那么代码就永远只走查询数据库这段代码,跟redis没关系了。。
解决缓存穿透很简单,就是数据库查询不到也要缓存结果,不过缓存结果赋值为空而已,但它的过期时间会很短,最长不超过五分钟。
If(redis存在此key){
Var redisValue=查询redis值
返回值
}else{
查询数据库.
If(能查到数据){
就写入到redis中
}else{
如果查询不到,也写到redis中,只不过值是空值
}
}
要注意的点:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
第三,Insert时需要事先移除要查询的key,否则即便DB中有值也查询不到(当然也可以设置空缓存的过期时间)
1.2. 缓存雪崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
解决方法
1. 加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket [1]
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
2.数据预热
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
3.做二级缓存,或者双缓存策略。
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
4.缓存永远不过期
这里的“永远不过期”包含两层意思:
(1) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
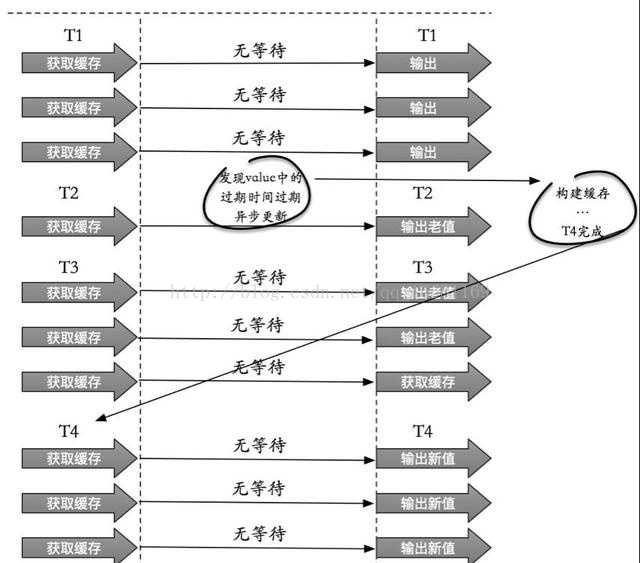
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
1.3. 热点Key
热点key:某个key访问非常频繁,当key失效的时候有大量的线程来构建缓存,导致负载增加,系统崩溃。
解决办法:
1、使用锁,单机用synchronized,lock等,分布式用分布式锁
2、缓存过期时间不设置,而是设置在key对应的value里。如果检测到存的时间超过过期时间则异步更新缓存
3、在value设置一个比过期时间t0小的过期时间值t1,当t1过期的时候,延长t1并做更新缓存操作
4、设置标签缓存,标签缓存设置过期时间,标签缓存过期后,需要异步更新实际缓存
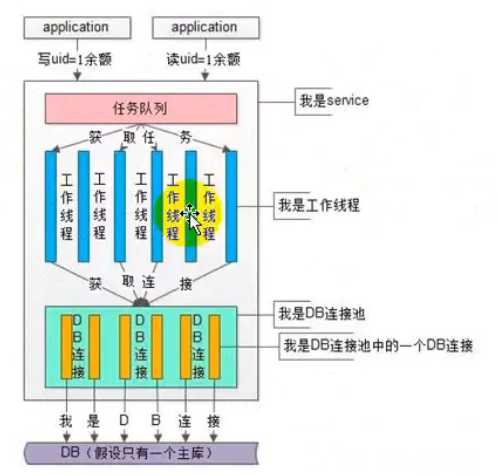
对于并发程度较高的,可采用异步队列的方式同步,可采用kafka等消息中间件处理消息生产和消费。
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
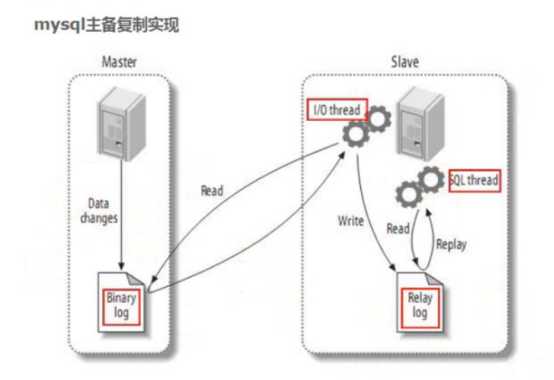
起源:早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。
基于日志增量订阅&消费支持的业务:
数据库镜像
数据库实时备份
多级索引 (卖家和买家各自分库索引)
search build
业务cache刷新
价格变化等重要业务消息
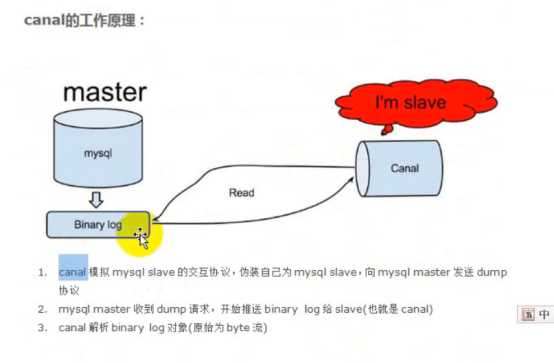
简单来说,Canal 会将自己伪装成 MySQL 从节点(Slave),并从主节点(Master)获取 Binlog,解析和贮存后供下游消费端使用。Canal 包含两个组成部分:服务端和客户端。服务端负责连接至不同的 MySQL 实例,并为每个实例维护一个事件消息队列;客户端则可以订阅这些队列中的数据变更事件,处理并存储到数据仓库中
原理相对比较简单:
标签:镜像 读数 性能 价格变化 mem add 实现 备份 后台
原文地址:https://www.cnblogs.com/schangxiang/p/11356514.html