标签:语言模型 相同 src OLE 结果 研究 hub 应该 使用
原作者:Christopher Olah
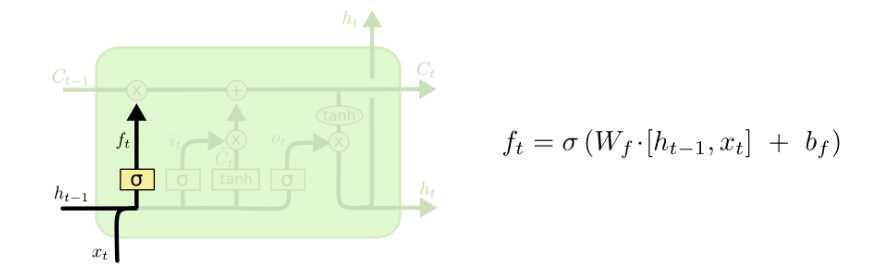
原址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/LSTM的第一步是决定将哪些信息从cell state中去除。我们通过一个叫做“forget gate layer”的sigmoid layer来实现这一步。
它接收\(h_{t-1}\)和\(x_{t}\)作为参数,然后为cell state \(C_{t-1}\)中的每个数字产生一个0或者1的输出。1代表完全保留该信息,0表示完全去除该信息。
考虑前文提到的根据之前的所有单词来预测下一个单词的语言模型。在这样一个问题中,cel state可能包含了当前主语的性别,这样我们就可以选择合适的代词。而当我们看到一个新的主语时,我们希望忘记之前的主语。
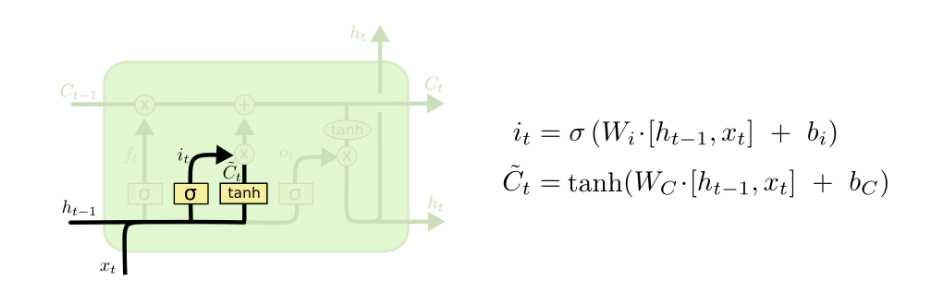
第二步是决定我们需要在cell state中保存哪些新的信息。这包括两部分。首先,一个叫做“input gate layer”的sigmoid层决定了我们将会更新哪些值。下一步,一个tanh层创建了一个新的向量,\(\tilde{C_{t}}\),它可以被加进cell state中。在下一步中,我们将会将这两者结合起来为state创建一个更新。
在我们语言模型的例子中,我们想要将新主语的性别加进cell state。
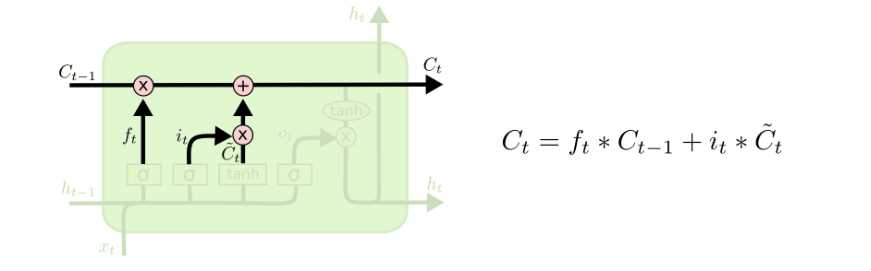
OK现在是时候将旧的状态\(C_{t-1}\)更新为新的状态\(C_{t}\)了。前面的步骤决定了要做哪些事,现在我们只需要真正执行这一步。
我们给old state乘上\(f_{t}\),来将我们之前决定忘记的内容清除。然后添加 \(t_{t}*\tilde{C_{t}}\)。这就是新的状态值,由我们希望每个状态值被更新的程度来决定其标度。
在我们的语言模型中,这里就是我们实际上将旧值替换为新值的地方。
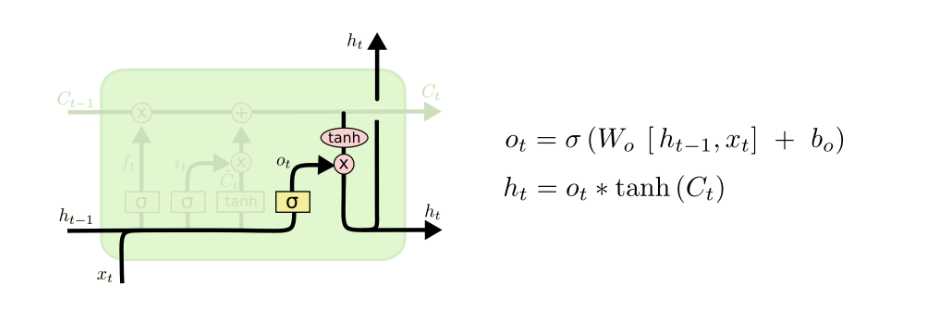
最后,我们需要决定我们的输出。这个输出将会基于我们的cell state,但是是一个修改过的版本。首先,通过一个sigmoid层,该层决定我们要输出cell state中的哪些部分。然后,将cell state输入一个tanh(将值映射到-1和1之间),再乘一个sigmoid层的输出,这样我们就仅仅输出我们想要输出的部分。
对于语言模型,由于我们刚刚遇到了一个主语,那么可能我们想要输出一个动词相关的信息。比如,它可能输出主语是单数还是负数,这样我们就知道动词应该是什么形式。
一个流行的LSTM变种,由Gers & Schmidhuber(2000)提出,增加了“peephole connections”。这意味着我们让gate layer可以看到cell state
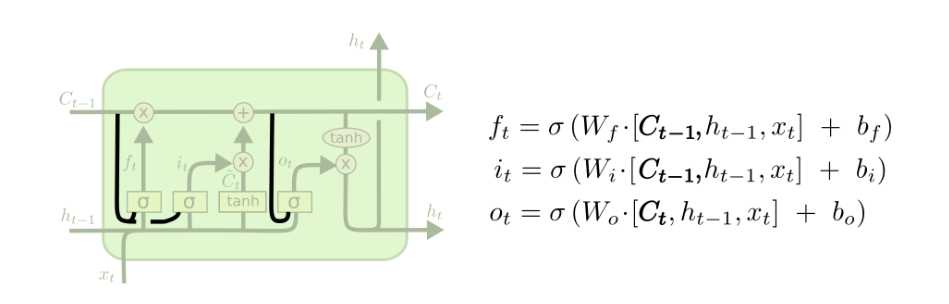
上面的图中我们向所有的gate layer增加了窥视孔,不过许多论文中只是部分增加。
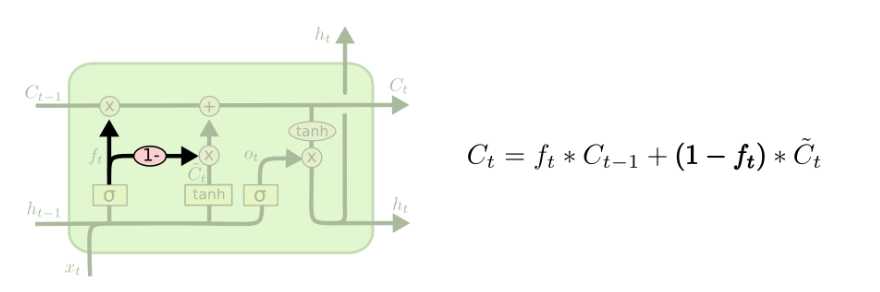
另一个变种是使用耦合 forget and input gates。之前的方式是独立地决定需要忘记哪些信息、增加哪些信息,现在则是将这两个决定结合在一起。只有当我们将会添加信息的时候我们才会消除信息,只有当我们决定消去信息时才会增加信息。
另一个变化比较大的变种是 Gated Recurrent Unit,简称 GRU,Cho, et al. (2014)。它将 forget and input layer 结合成一个"update gate"。
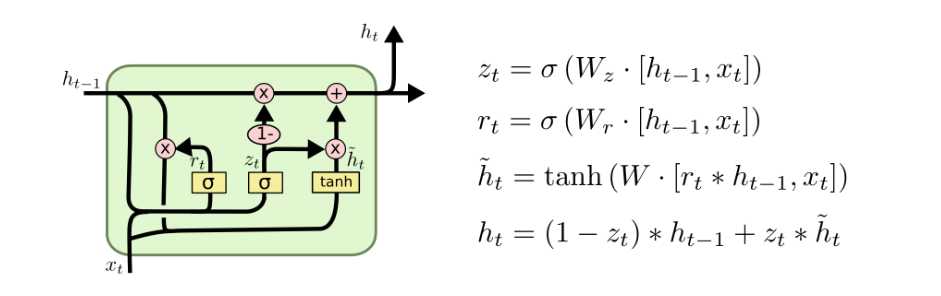
类似的还有很多。Greff, et al. (2015)对流行的各个变种做了一个对比,发现他们几乎是相同的。Jozefowica, et al.(2015)测试了超过10000种 RNN 架构,发现他们在有些任务上要比LSTM及其变种优秀。
前面,我提到人们在实现RN过程中得到的惊人的结果。其中绝大多数都是利用LSTM实现的。
关于RNN自然而然会有疑问:是否还有更大的进步?在研究者中有一个共识:The idea is to let every step of an RNN pick information to look at from some larger collection of information.比如,如果你正在使用RNN来为图片创建字幕,它可能会选取图像的一部分作为输出单词的依据。实际上如果你想要探索注意力机制的话,这会是一个很好的开头,这正是Xu, et al.所做的。
标签:语言模型 相同 src OLE 结果 研究 hub 应该 使用
原文地址:https://www.cnblogs.com/hezhiqiangTS/p/11359658.html