标签:gre 构造 定位 before output 大小 学习 数据初始化 inf
1.从底层数据结构,扩容策略
2.LinkedList的增删改查
3.特殊处理重点关注
4.遍历的速度,随机访问和iterator访问效率对比
构造函数不做任何操作,只要再add的时候进行数据初始化操作,以操作推动逻辑,而且linkedlist是一个双向链表,所以可以向前向后双向遍历
由于构造函数并没有任何操作,其实这里我们可以先看新增操作,并且因为用的是链表所以无法随机访问,这里随机读取就会比较慢
?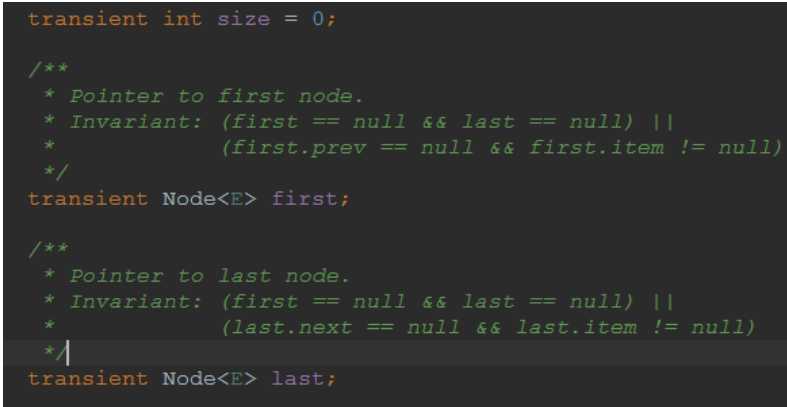
底层结构就是size,首节点,尾节点,还有就是一个List都有的共性就是modCount,这值用来记录这个list被修改了多少次
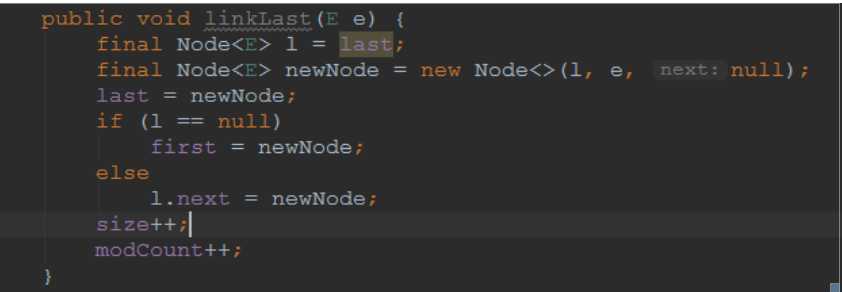
Add操作的实质就是进行linklast操作
linklast的操作就是再最后吧节点添加到尾部,并修正size大小
public boolean add(E ele) { linkLast(ele); return true; }
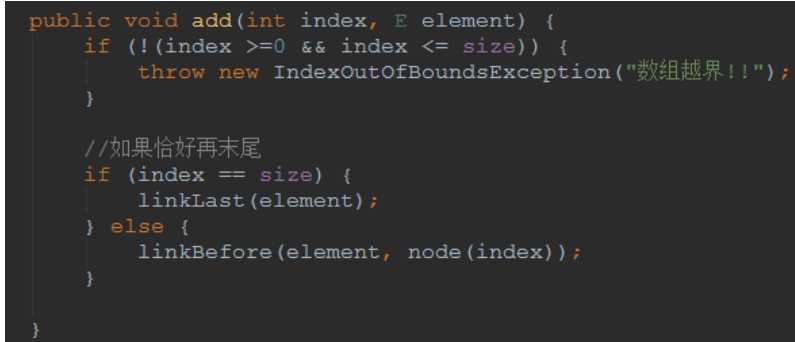
我们看看如果是在指定的位置插入元素的操作
首先要确认index再指定范围内
这里有个小优化,如果是在末尾进行添加的话,我们直接调用linklast就可以了
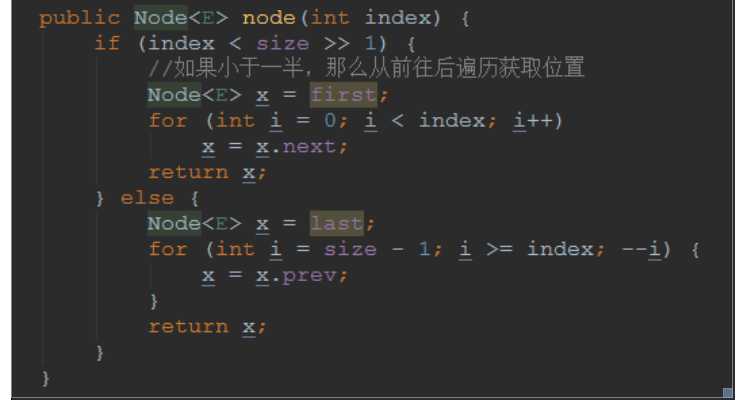
如果不是最后一个,那么首先要获取指定位置的node节点,我们遍历指定位置的时候
可以确定index的位置如果过半了,那么就从后往前,如果没有过半,那么就从前往后
1.直接再index创建一个节点,然后前后合并一下
2.吧原来的index位置的节点断开,吧这个节点的pre指向新节点
3.判断前置节点是否到头了,为空
4.把前置节点的next指向新节点
先看看node定位操作
然后我们看看linkbefore,前置插入
public void linkBefore(E e, Node<E> succ) { final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }
那么我们需要插入到指定的位置的方法就可以很简单的实现了
Linkbefore(e, node(index))即可
查看源码,比较remove(),remove(object),remove(index)等等操作,归根到底还是一个unlink操作
我们需要对指定的节点进行unlink操作
就2步操作
1.当前节点的前一个节点指向当前节点的下一个节点,说白了node.pre.next = node.next;
2.当前节点的下一个节点的前置节点指向当前节点的上一个节点:node.next.pre = node.pre;
其他细节部分就是首尾节点的处理
public E unlink(Node<E> node) { // assert x != null; //这里需要操作的就是三个节点,前置节点,当前节点,后置节点 final E element = node.item; final Node<E> prev = node.prev; final Node<E> next = node.next; //当前节点的前一个节点指向当前节点的下一个节点,说白了node.pre.next = node.next; if (prev == null) { //避免首节点操作 first = next; } else { prev.next = next; node.prev = null; //断开原始连接 } //当前节点的下一个节点的前置节点指向当前节点的上一个节点:node.next.pre = node.pre; if (next == null) { last = prev; } else { next.prev = prev; node.next = null; } //清除当前节点 node.item = null; size--; modCount++; return element; }
其余操作基本就是调用unlink方法进行操作
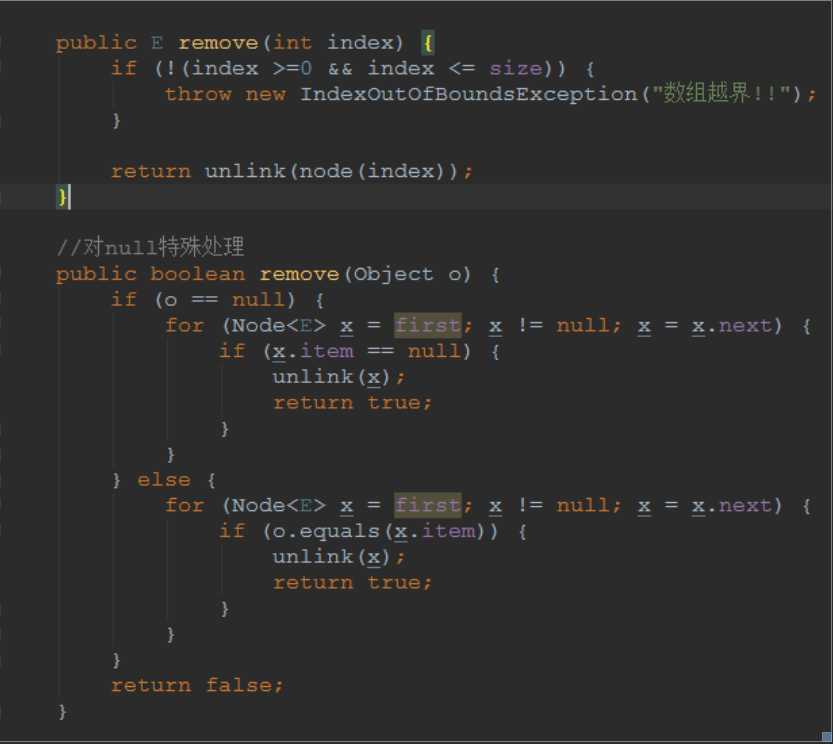
修改set和获取get就不多说了,就注意一点就是set操作的时候,会返回旧值,并且这两个操作不会修改modCount值,也就是不会产生链表变动
对于iterator这个就不多说了,其实还是调用上面的那些方法,遍历也就是next和pre和循环遍历没差别
但是注意一点就是通过迭代器进行remove和add是可以的,但是注意一点,如果使用迭代器进行remove或者add操作的通过,还使用了一般的remove和add那么就会使迭代器失效
序列化这里我们先只做一个了解,后续开章节专门学习一下java的序列化:
进行序列化、反序列化时,虚拟机会首先试图调用对象里的writeObject和readObject方法,进行用户自定义的序列化和反序列化。如果没有这样的方法,那么默认调用的是ObjectOutputStream的defaultWriteObject以及ObjectInputStream的defaultReadObject方法。换言之,利用自定义的writeObject方法和readObject方法,用户可以自己控制序列化和反序列化的过程。
---------------------
版权声明:本文为CSDN博主「zthgreat」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u014634338/article/details/78165127
这个问题其实也可以舍弃掉了,这里遍历的实质还是使用链表的遍历方式进行遍历
LinkedList 是线程不安全的,允许元素为null的双向链表。
参考:https://blog.csdn.net/u014634338/article/details/78165127
标签:gre 构造 定位 before output 大小 学习 数据初始化 inf
原文地址:https://www.cnblogs.com/cutter-point/p/11365579.html