标签:bsp ref general 线性 size nbsp 之间 扩展 介绍
论文:https://arxiv.org/pdf/1811.05233.pdf
译文:大规模分布式SGD:瞬间训练完基于ImageNet的ResNet50
摘要
由于大mini-batch训练的不稳定性(为什么不稳定?),和梯度同步的开销,深度学习分布式训练很难线性扩展到拥有大量GPU的集群。我们通过控制batch_size和label smoothing(这是什么意思?),来解决不稳定性。通过2D-Torus all reduce 算法来解决梯度同步的开销。2D-Torus all reduce 算法把GPU按照2D网格的方式组织,并且从不同方向执行通信操作。这两种技术在NNL中实现了,我们在ABCI集群中,用122秒训练完了基于ImageNet的ResNet50。
介绍
随着数据集和DNN模型的size越来越大,训练模型所需的时间也越来越长。基于数据并行的大规模分布式深度学习是一种减少训练时间的有效手段。但是,大规模分布式训练有两个技术难题。1)大mini-batch训练会导致准确率下降。2)GPU间梯度同步的通信开销。需要一种新方法来解决这两个难题。
在过去的几年,提出了很多技术来解决这两个难题。这些工作利用基于ImageNet的ResNet50来衡量训练效果。基于ImageNet的ResNet50是衡量大规模分布式深度学习的最受欢迎的数据集和模型之一。表1展示了最近工作的训练时间和准确率。
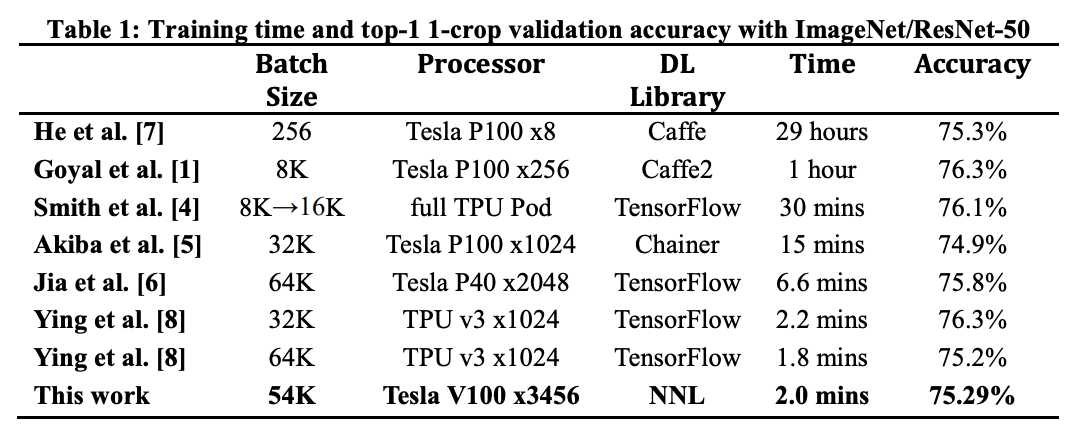
大mini-batch的不稳定性,和梯度同步代价,是我们想要解决的核心问题。我们用3456个Tesla V100 GPU,122秒训练完,并且准确率75.29%。我们还想在不损失准确率的情况下,提高GPU扩展效率。1024个Tesla V100 GPU的扩展效率是84.75%(意思是假设一个GPU的利用率是100%,那么1024个GPU的利用率就是84.75%)。(见表2)

方法
众所周知,大mini-batch训练不稳定,而且会产生泛化差距(generalization gap)(这是什么意思?),mini-batch=32K时,不稳定性得到缓解。还有mini-batch=64K。
基于数据并行的分布式训练,需要在GPU之间同步并平均梯度,再开始下一个迭代。这通过all reduce操作来实现。在大规模GPU集群,all reduce操作的开销导致很难达到线性扩展。
1、大mini-batch训练技术:
1)控制batch_size,逐步增大mini-batch,可以减少不稳定性。直观来说,增大batch_size,损失的走势更加平坦,有利于避免局部最小值。本文,我们实验batch_size控制,来减少准确率损失,batch_size超过32K。训练过程采用了batch_size自适应。
2)label smoothing,正规化可以提高泛化能力。我们实验label smoothing来减少准确率损失,batch_size超过32K。label smoothing降低了true标签的概率,同时提高了false标签的概率,以避免过拟合。
2、2D-Torus all reduce:
一种高效的通信拓扑,对降低通信开销极其重要。前人提出的通信拓扑包括ring all reduce和分级ring all reduce。
在特别大的GPU集群中,ring all reduce算法没法完全利用网络带宽。通信开销跟GPU个数成正比,因为网络延迟。(ring all reduce算法中,通信时间跟GPU个数无关才对?)
我们用2D-Torus all reduce来解决这个问题,拓扑结构如图1。GPU按2D网格组织。在2D-Torus中,all reduce分3步:reduce scatter、all reduce和all gather,如图2。1)水平执行reduce scatter;2)竖直执行all reduce;3)水平执行all gather。2D-Torus all reduce的通信开销比ring all reduce小
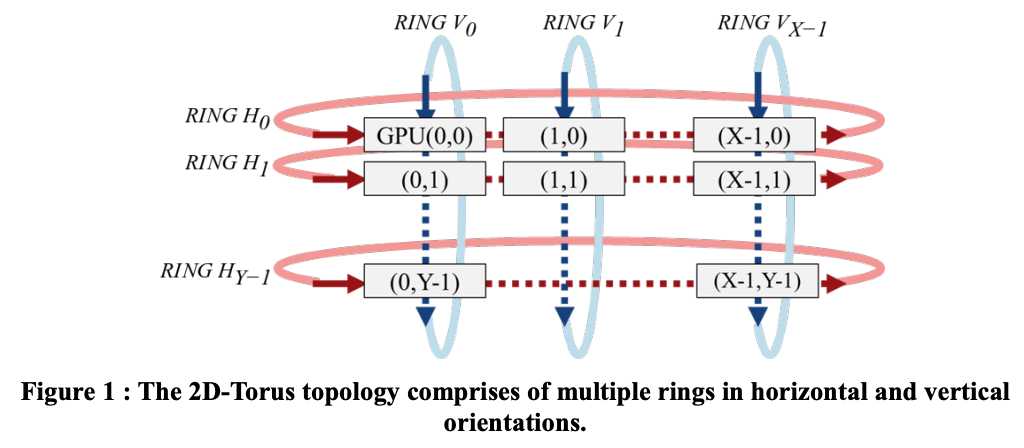
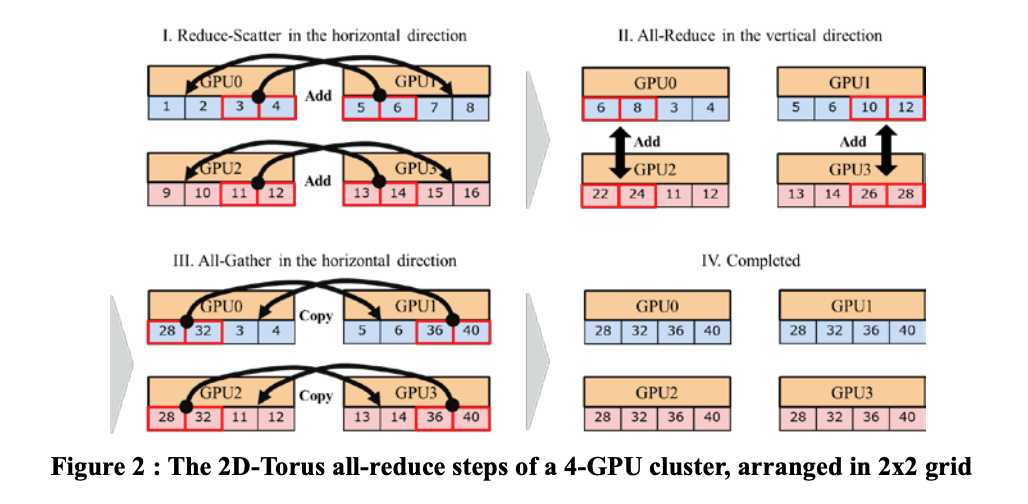
注:有关batch_size对训练的影响,众说纷纭。
参考链接
https://openreview.net/pdf?id=H1oyRlYgg
AI 大规模分布式SGD:瞬间训练完基于ImageNet的ResNet50
标签:bsp ref general 线性 size nbsp 之间 扩展 介绍
原文地址:https://www.cnblogs.com/yangwenhuan/p/11362715.html