标签:获取 进制 建立 img dog sea when 开始 正则表达式
? 群是一种只有一个运算的,简单的线性结构,可用来建立许多其他代数系统的一种基本结构.
? 设G是一个非空集合,a,b,c为它的任意元素.如果对G所定义的一种代数运算"."满足:
? 设H是群<G,.>的非空子集,则H是G的子群当且仅当H满足以下条件:
对任意的a,b属于H,a.b也是属于H,a^(-1)属于H;
对任意的a,b属于H,a.b^(-1)属于H;
任何群<G,.>有两个平凡子群:G和e,e是G的幺元.
? 字符串是字符的线性序列,可以采用线性表的各种实现技术实现,用顺序表或者链接表的形式表示.不论如何表示,实现的基础都是基于顺序存储或链接存储.
? 考虑字符串的表示时,有两个重要的方面必须确定:
字符串内容的存储(两个极端的存储方式)
1.把一个字符串的全部内容存储在一块连续存储区里
2.把串中的每个字符单独存入一个独立存储块,并将这些块连接在一起.
弊端:连续存储需要很大的连续空间,极长的字符串可能会带来问题,而一个字符一块存储,需要附带链接域,增大存储开销.实际中可以采用某种中间方式,把一个字符序列分段存储在一组存储块里,并连接起这些存储块.
串结束的表示:
不同的字符串长度可能不同,如果采取连续表示方式,由于存储在计算机里的都是二进制编码,计算机不会判断串的结束,那么有两个方式表示方法:
1.用一个专门的数据域记录字符串长度.
2.用一个特殊编码表示串结束.这个编码不代表任何字符,C语言就是才用了特殊编码形式.
python标准类型str可以看作是抽象的字符串概念的一种实现,str是一个不变类型,对象创建后内容和长度不变,但不同的str对象长度可能不一样,因此,在Python中str对象才用了一体式顺序表形式,

如图所示:一个字符串对象的头部,除了记录字符串的长度外,还记录了一些解释器用于管理对象的信息.
假设有两个串(其中ti,pj是字符):
$$
t = t_0t_1t_2...t_{(n-1)},p = p_0p_1p_2...p_{(m-1)}
$$
字符串匹配就是在t中查找与p相同(连续且长度相等的字符等同)的子串的操作,t是目标串,p为模式串,通常m<<n,也就是模式串远小于目标串的长度.
? 做字符串匹配的基础是逐个比较字符.
? 如果从目标串的某个位置i开始,模式串里的每个字符都与目标串里的对应字符相同,就是找到了一个匹配.如果遇到了一个不匹配的字符,那就是不匹配.串匹配算法设计的关键有两点:
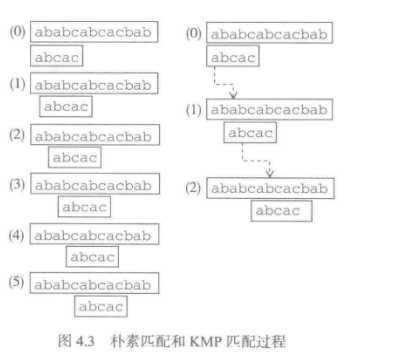
针对这两点不同的处理策略,就形成了不同的串匹配算法.从朴素匹配算法,KMP匹配算法可以看出情况.
最简答的朴素匹配算法采用最直观可行的策略:
#朴素串匹配算法:
#目标串t=t1t2t3....tn,模式串p=p1p2p3...pm
def naive_matching(t,p):
m,n=len(p),len(t)
i,j=0,0
while i < m and j<n:
if p[i]==t[j]:
i,j = i+1,j+1
else:
i,j=0,j-i+1
if i == m: #当i==m时,说明i已经比较出0到m-1的字符的匹配,说明匹配成功
return j-i
return -1 #无匹配,返回特殊值
缺点:算法易实现,但是效率低,这种需要比较n-m+1,总的比较次数是m*(n-m+1),时间复杂度O(m*n)
KMP算法是一个高效的串匹配算法.区别看图
这里主要看pi匹配失败了,模式串怎么前移?根据模式串p本身情况决定,完全可以实际地与任何目标串匹配之前,通过对模式串本身的分析,解决好匹配失败是应该如何前移?
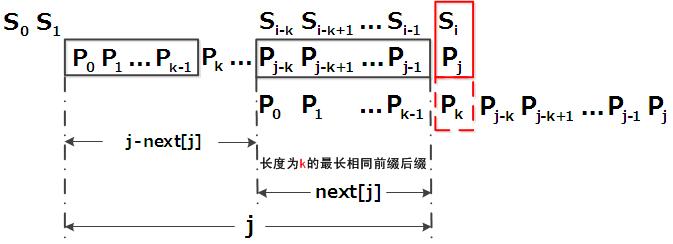
从上面的分析来看,对p中的每个i,都有与之对应的下标ki,与被匹配的目标串无关.有可能通过对模式串的预分析,得到每个i对应的ki.假定模式串p的长度是m,现在需要对每个i(0<=i<m)计算出对应的ki并将其保存起来,以便在匹配中使用.为此,我们考虑用一个长为m的表pnext,用表元素pnext[i]记录与i对应的ki值.
这里有一个特殊情况,在一些pi的匹配失败时,有可能发现pi匹配之前就做过的所有模式串字符与目标串的比较都没有实际利用价值.这样的话,下一步就应该从头开始,用p0匹配与tj+1比较,如果遇到这种情况时,就在pnext[i]里存入-1,显然对任何模式都有pnext[0]=-1
$$
t=t_0t_1t_2...t_n,p=p_0p_1p_2...p_m
$$
#KMP的基本算法是不回溯
while j<n and i<m:
if i == -1:
i,j = i+1,j+1
elif t[j] == p[i]:
i,j = i+1,j+1
else:
i = pnext[i]
#显然前两个if分支可以合并,并循环简化:
while j < n and i < m:
if i == -1 or t[j] == p[i]:
j,i = j+1,i+1
else:
i = pnext[i]
解释:当t[10]与p[6]匹配失败时,KMP不是跟保利匹配那样简单的把模式串右移一个单位,而是执行如果i!=-1且当前的字符匹配失败(即t[j]!=p[i]),则令j不变,i=pnext[i],也就是i从6变到2
pnext数组各值的含义:代表当前的字符之前的字符串中,有多大长度的相同前缀后缀,,比如pnext[j]=k,代表j之前的字符串中有最大长度是k的相同前缀后缀.
#基于上述循环的匹配函数定义:
def matching_KMP(t,p,pnext):
j,i = 0,0
n,m = len(t),len(p)
while j < n and i < m:
if i == -1 or t[j] == p[i]:
j,i = j+1,i+1
else:#失败,考虑pnext决定的下一字符
i = pnext[i]
if i == m: #找到匹配,返回其下标
return j-1
return -1 #无匹配,返回特殊值现在考虑这个算法的复杂度,关键是其中循环的执行次数.注意,在整个循环中j的值是递增的,但其加一的总次数不会多于len(t).而且,j递增时i的值也增加.而在if的另一个分支,语句i=pnext[i]总使i值减小.但if的条件有保证变量i的值不小于-1,因此,i=pnext[i]的执行次数不会多于i值的递增次数.循环次数也不会多与O(n),n是目标串的长度.寻找模式串中最长公共元素长度的前缀后缀:
对于
$$
p = p_0p_1...p_{(j-1)}p_j
$$
寻找模式串p中长度最长且相等的前缀后缀,如果存在
$$
p_0p_1...p_{(k-1)}=p_{(j-k)}p_{(j-k+1)}...p_{(j-1)}p_j,
$$
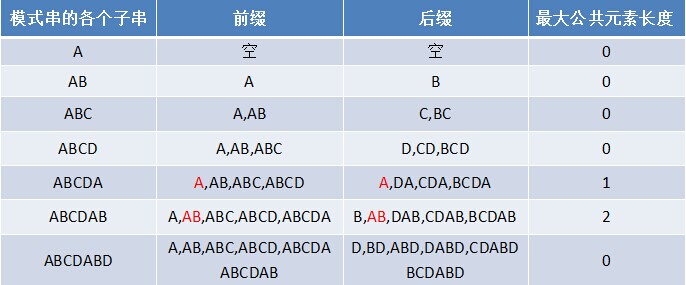
那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀.比如字符串abab来说,他有长度为2 的相同的前缀后缀ab.
? 2.求pnext
? pnext数组考虑的是除当前字符外的最长相同的前缀后缀,所以通过第一步求得的各个前缀后缀的公共元素的最大长度后,只要稍作变形即可,,将第一步求得的值整体右移一位,然后赋值为-1,比如说aba来说,第三个字符a之前的字符串ab有长度是0的相同的前缀后缀,所以第三个字符a对应next值是0;而对于abab来说,第四个字符b之前的字符串aba中有长度是1 的相同前缀后缀a,所以第四个字符b对应的pnext是1.(pnext就是next数组)
? 3.根据next数组进行匹配
? 匹配失败,i= pnext[i],模式串向右移的位数为:i-pnext[i],看图作解释:
模式串中,
$$
p_{(j-k)}p_{(j-k+1)}...p_{(j-1)}跟目标串s_{(i-k)}s_{(i-k+1)}...s_{(i-1)}匹配成功
$$
但pj与si匹配失败时,pnext[j]=k,相当于在不包含pj的模式串中有最大长度是k的相同的前缀后缀,即
$$
p_0p_1...p_{(k-1)}=p_{(j-k)}p_{(j-k+1)}...p_{(j-1)}
$$
故令j=pnext[j],从而让模式串右移j-pnext[j]位,使得模式串的前缀p0p1...pk-1对应着si-ksi-k+1...si-1,而后让pk继续和si匹配.
如果给定的模式串是"ABCDABD",从左至右遍历整个模式串,其各个子串的前缀后缀如图所示:
也就是说,原模式串对应的各个前缀后缀的公共元素的最大长度表:(匹配表)
失配右移位数:
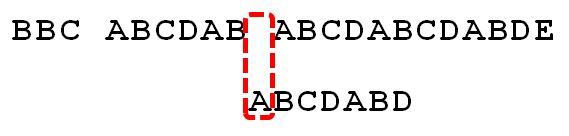
已匹配字符数-失配字符的上一位字符所对应的最大长度值假定目标串是"BBC ABCDAB ABCDABCDABDE"和模式串"ABCDABD",过程如下:
1.因为模式串中字符A与目标串的字符B,C,空格不匹配,这时还没有最长的前缀后缀,所以不断向右移一步,直至与第五个字符A匹配成功.
2.继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。
3.模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了2个字符(AB),且上一位字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。
4.A与空格失配,向右移动1 位。
5.继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。
经历第5步后,发现匹配成功,过程结束。
def get_pnext(p):
'''
生成针对p中给位置中i的下一检查位置表,KMP
'''
i , k , m = 0,-1,len(p)
pnext = [-1]*m #初始数组元素都是-1
while i < m-1:
if k == -1 or p[i]==p[k]:
i,k = i+1,k+1
pnext[i]=k#设置pnext元素
else:
k = pnext[k] #退到更短相同前缀.def get_pnext(p):
i,k,m = 0, -1,len(p)
pnext = [-1]*m
while i<m-1:
if k == -1 or p[i] == p[k]:
i,k=i+1,k+1
if p[i]==p[k]:
pnext[i]=pnext[k]
else:
pnext[i]=k
else:
k=pnext[k]
return pnext
一次KMP算法的完整执行包括构造pnext表和实际匹配,设模式串长m,目标串长n,这里(m<<n),时间复杂度O(m+n)=O(n),而朴素匹配算法O(m*n).
? 在普通字符串的基础上增加通配符,形成一种功能更强大一点的模式描述语言,一个模式描述了一字符串集,能与该集合任何一个串匹配.
? 一个非常有意义和实用价值的模式语言为正则表达式.
? 正则表达式是一种描述字符串集合的语言,基本成分是字符集里的普通字符,几种特殊组合结构,以及表示组合的括号.一个正则表达式描述了字符集的一个特定的字符串集合.
模式语言:
? 在python中书写字符串文字量的一种形式,这种文字量和普通文字量一样,就是str类型的字符串.
? 原始字符串的形式是在普通字符串文字量前加r或R前缀.
? 原始字符串其中的反斜线字符"\"不作为转义,在相应的字符串对象中原样保存,
? 正则表达式包re规定了一组特殊字符,成为元字符.. ^ $ + ? \ | { } [ ] ( )
生成正则表达式对象:re.compile(pattern,flags=0)
检索:re.search(pattern,string,flag=0)
re.search 扫描整个字符串并返回第一个成功的匹配。
print('>>>',re.search('www','www.xxxx.com'))
print('>>>',re.search('www','www.xxxx.com').group())
print('>>>',re.search('com','www.xxxx.com').group())
line = "Cats are smarter than dogs";
searchObj = re.search(r'(.*) are (.*?) .*', line, re.M | re.I)
if searchObj:
print("searchObj.group() : ", searchObj.group())
print("searchObj.group(1) : ", searchObj.group(1))
print("searchObj.group(2) : ", searchObj.group(2))
else:
print('no found')
################################################ #######################
>>> <_sre.SRE_Match object; span=(0, 3), match='www'>
>>> www
>>> com
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarter
#这里竟然可以把第二个匹配出来的对象整出来了匹配:re.match(pattern,string,flags=0)
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配的话,就返回None
import re
print('>>>',re.match('www','www.xxxx.com'))
print('>>>',re.match('www','www.xxxx.com').span())
print('>>>',re.match('www','www.xxxx.com').group())
print('>>>',re.match('com','www.xxxx.com'))
s = 'cats are smarter than dogs'
obj = re.match(r'(.*) are (.*?) .*', s ,re.I|re.M)
if obj:
print('obj.group():',obj.group())
print('obj.group():',obj.group(1))
print('obj.group():',obj.group(2))
else:
print('no match')
#################################################################################################
>>> <_sre.SRE_Match object; span=(0, 3), match='www'>
>>> (0, 3)
>>> www
>>> None
obj.group(): cats are smarter than dogs
obj.group(): cats
obj.group(): smarter分割:re.split(pattern,string,maxsplit=0,flags=0)
? maxsplit:分隔次数,maxsplit=1,分割一次,默认是0,不限次数.
? split 方法按照能够匹配的子串将字符串分割后返回列表
print(re.split('\W+','i love you when you call me senorita'))
print(re.split('(\W+)','i love you when you call me senorita'))#按照非数字字母切割
print(re.split('(\w+)','i love you when you call me senorita'))#按照数字字母切割
#######################################################################
['i', 'love', 'you', 'when', 'you', 'call', 'me', 'senorita']
['i', ' ', 'love', ' ', 'you', ' ', 'when', ' ', 'you', ' ', 'call', ' ', 'me', ' ', 'senorita']
['', 'i', ' ', 'love', ' ', 'you', ' ', 'when', ' ', 'you', ' ', 'call', ' ', 'me', ' ', 'senorita', '']非贪婪模式:尝试尽可能少的匹配字符
#re模块默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
m = 'abcde1232aac'
regex = re.compile(r'ab.*c')
print('>>:',regex.match(m).group())
reg = re.compile(r'ab.*?c')
print('>>:',reg.match(m).group())
#########################################################
>>: abcde1232aac
>>: abcfindall:findall(string[,pos[,endpos]])
pos:可选参数,指定字符的起始位置,默认是0,endpos可选参数,指定字符串的位置,默认是字符串的长度.
import re
p = re.compile(r'\d+')
print(p.findall('ikon32jkdfdsh33'))
print(p.findall('ikon32jkdfdsh33',0,5))
############################################
['32', '33']
['3']?可选描述符表示,匹配字符串的0或1次重复匹配.
a{n}与a匹配的串的n次重复匹配.
a{m,n}与a匹配的串的m到n次重复匹配,包括m次和n次.
\b描述边界,它在实际单词边界位置匹配空船(不匹配实际字符).单词是字母数字的任意连续序列,其边界就是非数字的字符或无字符.
就是匹配边界.....
\B匹配非边界
很多匹配函数成功后返回一个match对象,记录了完成匹配中信息.
取得被匹配的子串:mat.group()
在目标串里的匹配位置:mat.start()
目标串里被匹配子串的结束位置:mat.end()
目标串里被匹配的区间:mat.span()
p = re.compile(r'\d+')
s = p.search('ikon32jkdfdsh33@*()d134*(&*(ksd5855dmsli(jksdj0dklsj')
print(s)
print(s.group())
print(s.start())
print(s.end())
print(s.span())
#################################################################
<_sre.SRE_Match object; span=(4, 6), match='32'>
32
4
6
(4, 6)标签:获取 进制 建立 img dog sea when 开始 正则表达式
原文地址:https://www.cnblogs.com/Zhao159461/p/11369804.html