标签:nump padding src 测试 dem sci 就是 otl int
一: 环境准备:
1.导入的库:
import numpy as np import matplotlib.pyplot as plt import pandas as pd import mglearn
2.导入数据集
from sklearn.datasets import load_iris iris_dataset = load_iris()
二. 划分训练数据和测试数据
1. train_test_split: 将数据集打乱并进行拆分
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( iris_dataset[‘data‘], iris_dataset[‘target‘], random_state=0)
其中,random_state=0,表示每次调用train_test_split返回的输出都是不变的,即随机数生成器的种子是相同的.
生成的
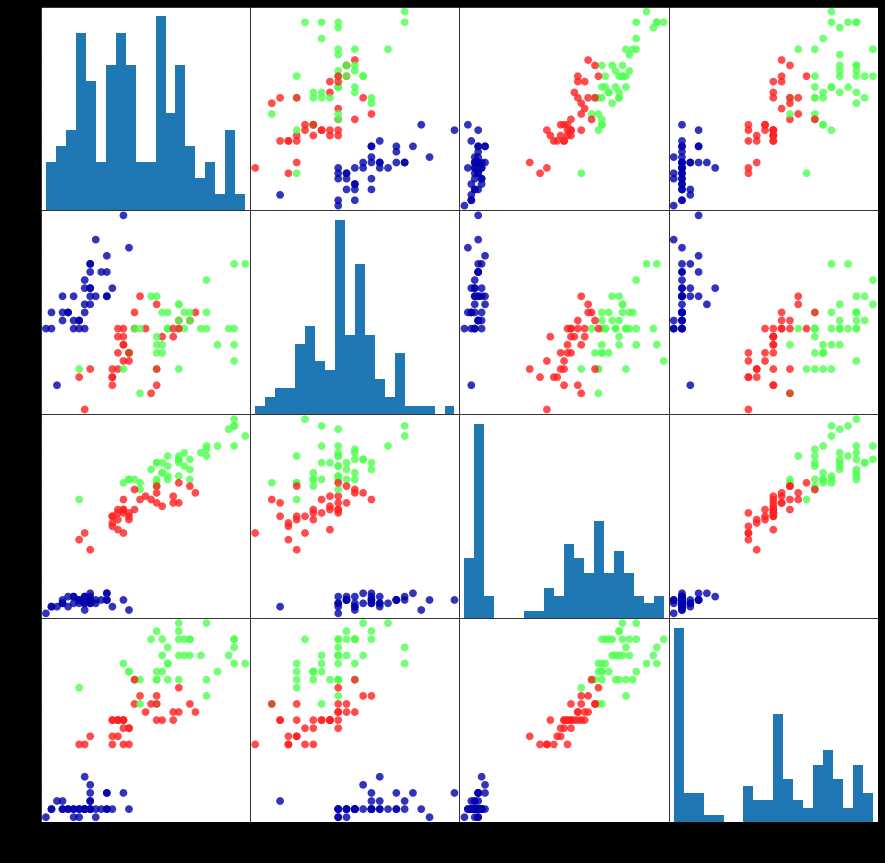
2.scatter_matrix: 使用pandas绘制散点图矩阵(即取出两行,一行的元素作为横坐标,一行的元素作为纵坐标)
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names) #columns设置索引
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15,15),
marker=‘o‘, hist_kwds={‘bins‘:20}, s=60, alpha=.8, cmap=mglearn.cm3)
参数解释: frame:数据的dataframe,本例为4*150的矩阵; c是颜色,本例中按照y_train的不同来分配不同的颜色; figsize设置图片的尺寸; marker是散点的形状,‘o‘是圆形,‘*‘是星形 ; hist_kwds是直方图的相关参数,{‘bins‘:20}是生成包含20个长条的直方图;
s是大图的尺寸 ; alpha是图的透明度; cmap是colourmap,就是颜色板
三 k近邻算法
1.原理: 将新数据点放到训练集中,找出训练集中与新数据点直线距离最近的若干个点,然后找出这若干个点属于哪个类别的点最多,就将训练集视为哪个类别.
2.使用方法
2.1.scikit-learn中所有的机器学习模型都在各自的类中实现,这些类被称为Estimator类。k近邻分类算法是在neighbors模块的KNeighborsClassifier类中实现。
from sklearn.neighbors import KNeighborsClassifier
2.2.使用k近邻首先需要将KNeighborsClassifier实例化成一个对象.
knn = KNeighborsClassifier(n_neighbors=1)
knn对象可以用训练数据重新训练,也可以对新数据点进行预测,也可以从训练数据中提取信息.
2.3 基于训练集构建模型
调用knn对象的fit方法,输入参数X_train和y_train
In: knn.fit(X_train,y_train)
2.4 做出预测
2.4.1 构建numpy数组(scikit-learn输入的数据必须是二维数组)
X_new = np.array([[5,2.9,1,0.2]]) print(X_new.shape)
2.4.2 调用predict函数
prediction = knn.predict(X_new) print(prediction) print(iris_dataset[‘target_names‘][prediction])
2.5 评估模型
y_pred = knn.predict(X_test) print(y_pred) print(np.mean(y_pred == y_test))
print(knn.score(X_test,y_test))
---摘录自python机器学习基础教程
标签:nump padding src 测试 dem sci 就是 otl int
原文地址:https://www.cnblogs.com/draven123/p/11372308.html