标签:切换 注意 use 自测 最大 http The 情况 线程
1、起因
隐约听到坐在我对面的测试说测试环境的接口有问题
他们一番商讨后,朝我这边反馈说,现在测试环境的接口报504
我条件反射的回了句那是接口超时,再多试几次(测试环境的性能比较差,尤其是数据库,经常504
测试同学并不信服的点点头
再一会,有同事反馈自测自己的功能发现操作数据库失败,我去瞅了一眼
invalid connection,嗯,这个我很熟悉,我前几天也偶尔遇到过
再接着,测试为了让我们重视起来,用了一个很提神的说法——"测试环境炸了"
我们几个同事看了下,发现测试说的接口炸了,其实是测试的数据库炸了,从偶尔的连不上变成偶尔的连上再到彻底连不上
2、初步排查
接口全挂,测试怀着复杂的心情呆坐着,不时的问我们接口好了没
我们开始回忆今天一切有关数据库的操作……
老大下午四点的时候好像在群里反馈过一波,说谁把测试数据库的连接打满了,大家都从自己当前的线程中抽了几秒钟象征性的回忆了下自己是否有操作数据库,然后发现与我无瓜后,继续切换到主线程code
后来,有隐约听到老大说数据库卡死,需要重启下
这个回忆起来的操作,让我们认为重启是导致这次数据库炸了的元凶,然而,这都是猜测,一时半会还拿不出什么证据(直到最后,我们找到原因,也无法断定是此次重启造成的,后面再细说
于是,有的同事通过"show full processlist"查看当前连接数,发现连接并不多;有同事通过调试的方式企图找到一些线索……
20分钟过去了,大家还没有明显的思路,显然,这种问题大家之前也没有遇到过。
在这段时间里,我进入数据库所在的机器,执行‘ps -ef |grep "mysql" ‘看到了error.log
/usr/sbin/mysqld --defaults-file=/etc/mysql/my.cnf --basedir=/usr --datadir=/data/mysql --plugin-dir=/usr/lib/mysql/plugin --user=root --log-error=/var/log/mysql/error.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/run/mysqld/mysqld.sock --port=3306
于是打开error.log,看到了大量的报错
InnoDB: is in the future! Current system log sequence number 1405123835. InnoDB: Your database may be corrupt or you may have copied the InnoDB InnoDB: tablespace but not the InnoDB log files. See InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html InnoDB: for more information. 2019-08-05 16:00:24 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:01:04 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:01:14 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:01:21 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:02:59 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:04:21 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:04:50 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:04:50 7fc2f0aa1700 InnoDB: Error: page 0 log sequence number 7062646246 InnoDB: is in the future! Current system log sequence number 1405130514. InnoDB: Your database may be corrupt or you may have copied the InnoDB InnoDB: tablespace but not the InnoDB log files. See InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html InnoDB: for more information. 2019-08-05 16:06:48 31322 [Warning] IP address xxx could not be resolved: Name or service not known 2019-08-05 16:07:53 7fc2f0d1e700 InnoDB: Error: page 1 log sequence number 5259699595 InnoDB: is in the future! Current system log sequence number 1405134555. InnoDB: Your database may be corrupt or you may have copied the InnoDB InnoDB: tablespace but not the InnoDB log files. See InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html InnoDB: for more information. 2019-08-05 16:07:53 7fc2f8103700 InnoDB: Error: page 1 log sequence number 5262439743 InnoDB: is in the future! Current system log sequence number 1405134555. InnoDB: Your database may be corrupt or you may have copied the InnoDB InnoDB: tablespace but not the InnoDB log files. See InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html
大部分都是这样的报错。
Error: page 1 log sequence number 5262439743
网上找了一番,说是数据库的文件损坏,问了下运维,运维也承认是这个问题并且无法修复,建议我们dump数据再重建数据库(是不是玩大了
我把这个情况,和其他同事同步了下,大家应该也注意到这块了。
3、误伤的innodb_force_recovery
有同事看了上面的错误日志,结合网上的资料,决定先拿innodb_force_recovery这个参数开刀。
Innodb_force_recovery的介绍参见https://blog.csdn.net/edyf123/article/details/81026155
具体操作
登录机器,"sudo vim /etc/mysql/my.cnf"即进入mysql配置文件
将原本注释的innodb_force_recovery放开,并将值设置为6(默认值应该是0)
结果
怀着期待的心情,重启MySQL后,发现,数据库还是炸。这个操作不仅没有解决问题,还为后面埋了个雷~
4、回归错误本身"invalid connection"
大家开始冷静下来,从其他方面寻找问题根源。
调用接口时,MySQL给出的错误信息就是"invalid connection"
于是顺着这个信息,在网上找了一番,大部分给出的都是和wait_timeout以及interactive_timeout有关。
通过命令‘show variables like "%timeout%"‘看到
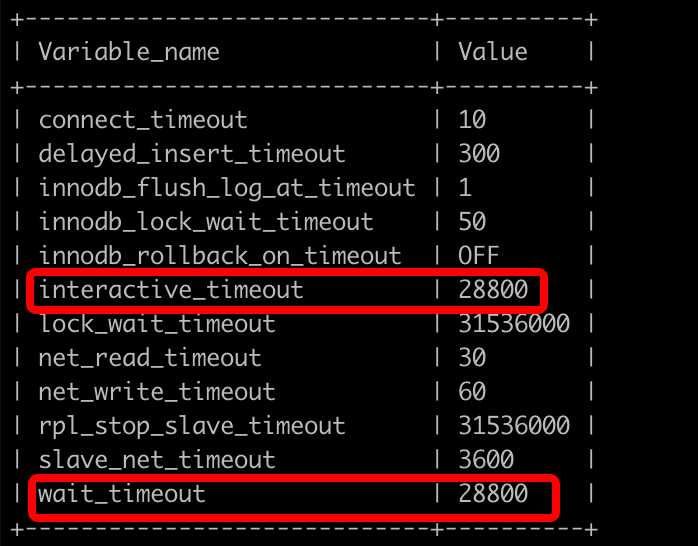
其中wait_timeout和interactive_timeout都是28800即8小时,都是正常的。
到此,我个人排查感觉陷入了僵局~~~
5、Abort_clients
到此问题尚未解决, innodb_force_recovery和wait_timeout以及interactive_timeout都已经排除嫌疑。
下一步我的思路是,通过"show status"和"show global variables"查看各项指标。
执行"show status"后,我发现Abort_client这个值很大,虽然我也不知道这个值正常应该是多少,但是我当时看到的时候已经飙到1w+,然后还在继续增长。
我查了下这个指标的含义。
Abort_clients表示客户端没有正确的关闭连接,而被终止的连接数,引起的原因:
1.客户端程序退出之前未调用mysql_close()来关闭mysql连接
2.客户端的休眠时间超过了mysql系统变量wait_timeout和interactive_timeout的值,导致连接被mysql进程终止
3.客户端程序在数据传输过程中突然结束
看这意思应该是服务端根据超时时间设置关闭了连接,导致客户端连接失败。
针对这几个原因,一一排查感觉应该都不会出现,尤其是wait_timeout和interactive_timeout这两个指标,上面还看过他们的值。
但是Abort_clients的值还是很大这是事实。
于是继续在网上找相关资料,这一次,终于有了转机……
6、真相大白
我已经忘记当时是以怎样的关键词组合才搜索到了这篇文章https://www.jianshu.com/p/39b140d03531
看到文章最后部分,让我觉得这次跑不了了,就是你了。

怀着激动的心情进入my.cnf文件,看了一眼wait_timeout的值,震惊,居然是5,也就是5秒。
但是当时使用‘show variables like "%timeout%"‘它明明是28800,原因上面文章中已经给出了。
于是修改这个值为28800,再重启数据库~~~
7、挖走最后一颗雷
还记得上面提到的那个雷吗?
没错,我们重启后,信誓旦旦告诉测试已经修复了。结果测试反馈还是报错,我们在后台看了下,报的是插入数据失败一类的错误。
我突然想到,之前同事还设置过指标innodb_force_recovery,我记得当时看文章的时候提到这个指标会影响数据库的插入和更新操作。
即文章https://blog.csdn.net/edyf123/article/details/81026155提到的备注部分:当设置innodb_force_recovery大于0后,可以对标进行select、create、drop操作,但insert、update或者delete这类操作是不允许的。
于是,注释这个值,在重启数据库。
问题解决!(虽然找到了真正的原因,但是已经找不到是谁把这个值设置成了5~~~
8、总结
从发现问题,到排查error.log,到聚焦innodb_force_recovery,再到看走眼wait_timeout,最后从单个指标扩大到各项指标,再次聚焦到wait_timeout上找到真正的原因。
排查问题的思路不应该是过分钻牛角尖,结合已有的现场信息分析可能的原因,再去验证,从点到面再到点。
常见MySQL命令需要数据,比如”show status“、”show full processlist“、”show global variables“等等
版本信息
MySQL:5.6.43
Go:1.12.4
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!如果您想持续关注我的文章,请扫描二维码,关注JackieZheng的微信公众号,我会将我的文章推送给您,并和您一起分享我日常阅读过的优质文章。
标签:切换 注意 use 自测 最大 http The 情况 线程
原文地址:https://www.cnblogs.com/bigdataZJ/p/invalid_connection_for_wait_timeout.html
