标签:输入 databases 查看 encode 解决方法 编码转换 desc 验证 原因
刚刚写了几百字的东西因为断网,导致全没有了,重头再写,我就只想记录东西我自己看了:
1)客户端编码格式默认是从客户端的服务器编码获取,也就是LANG环境变量。
2)客户端编码和服务器编码如果一致,则插入的数据之间不经过转码,存入服务器。
3)客户端编码和服务器编码如果不一致,则插入的数据会传输到服务器端,并进行自动转码,存入数据库服务器。
4)如果服务器端传过来的数据,本地编码对应的字符集不支持中文,那么也就不能显示,即使编码转换是正确的。
那么就有如下这种情况:
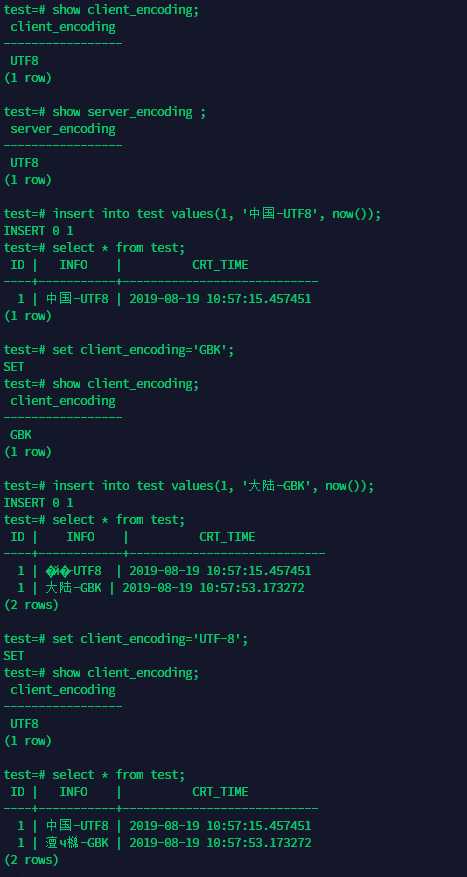
当我一开始使用UTF8插入数据,服务器端也是UTF8,查询显示都OK;然后修改客户端编码为GBK,插入数据,此时服务器自动会将GBK转换为UTF8,当在客户端查询时,再将UTF8转为GBK。
这样总会有一条数据显示的是乱码,怎么解决?
另外,不管怎么样,服务器都存放的是UTF8编码格式的数据,那么应该不存在乱码的问题啊?服务端统一将UTF8转为GBK,不能说第一条原本是UTF8没有发生转换过,因此往GBk转就失败。第二条也是从UTF8转为GBK的呢···,目前这里还有点没闹明白,下面是实验:
下面是参考的资料:
PostgreSQL数据库支持多种字符集,在配置字符集时要分清楚服务器与客户端的字符集,字符集不一致尽管有时能够发生转换,但带来的问题也很头疼。语言环境的配置也很重要。
服务器字符集<来自文档>:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
Name Description Language Server? Bytes/Char AliasesBIG5 Big Five Traditional Chinese No 1-2 WIN950, Windows950EUC_CN Extended UNIX Code-CN Simplified Chinese Yes 1-3 EUC_JP Extended UNIX Code-JP Japanese Yes 1-3 EUC_JIS_2004 Extended UNIX Code-JP, JIS X 0213 Japanese Yes 1-3 EUC_KR Extended UNIX Code-KR Korean Yes 1-3 EUC_TW Extended UNIX Code-TW Traditional Chinese, Taiwanese Yes 1-3 GB18030 National Standard Chinese No 1-2 GBK Extended National Standard Simplified Chinese No 1-2 WIN936, Windows936ISO_8859_5 ISO 8859-5, ECMA 113 Latin/Cyrillic Yes 1 ISO_8859_6 ISO 8859-6, ECMA 114 Latin/Arabic Yes 1 ISO_8859_7 ISO 8859-7, ECMA 118 Latin/Greek Yes 1 ISO_8859_8 ISO 8859-8, ECMA 121 Latin/Hebrew Yes 1 JOHAB JOHAB Korean (Hangul) No 1-3 KOI8 KOI8-R(U) Cyrillic Yes 1 KOI8RLATIN1 ISO 8859-1, ECMA 94 Western European Yes 1 ISO88591LATIN2 ISO 8859-2, ECMA 94 Central European Yes 1 ISO88592LATIN3 ISO 8859-3, ECMA 94 South European Yes 1 ISO88593LATIN4 ISO 8859-4, ECMA 94 North European Yes 1 ISO88594LATIN5 ISO 8859-9, ECMA 128 Turkish Yes 1 ISO88599LATIN6 ISO 8859-10, ECMA 144 Nordic Yes 1 ISO885910LATIN7 ISO 8859-13 Baltic Yes 1 ISO885913LATIN8 ISO 8859-14 Celtic Yes 1 ISO885914LATIN9 ISO 8859-15 LATIN1 with Euro and accents Yes 1 ISO885915LATIN10 ISO 8859-16, ASRO SR 14111 Romanian Yes 1 ISO885916MULE_INTERNAL Mule internal code Multilingual Emacs Yes 1-4 SJIS Shift JIS Japanese No 1-2 Mskanji, ShiftJIS, WIN932, Windows932SHIFT_JIS_2004 Shift JIS, JIS X 0213 Japanese No 1-2 SQL_ASCII unspecified (see text) any Yes 1 UHC Unified Hangul Code Korean No 1-2 WIN949, Windows949UTF8 Unicode, 8-bit all Yes 1-4 UnicodeWIN866 Windows CP866 Cyrillic Yes 1 ALTWIN874 Windows CP874 Thai Yes 1 WIN1250 Windows CP1250 Central European Yes 1 WIN1251 Windows CP1251 Cyrillic Yes 1 WINWIN1252 Windows CP1252 Western European Yes 1 WIN1253 Windows CP1253 Greek Yes 1 WIN1254 Windows CP1254 Turkish Yes 1 WIN1255 Windows CP1255 Hebrew Yes 1 WIN1256 Windows CP1256 Arabic Yes 1 WIN1257 Windows CP1257 Baltic Yes 1 WIN1258 Windows CP1258 Vietnamese Yes 1 ABC, TCVN, TCVN5712, VSCII |
常用的简体中文字符集是UTF8和EUC_CN两种。
可自动转换字符集<来自文档>:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
Server Character Set Available Client Character SetsBIG5 not supported as a server encodingEUC_CN EUC_CN, MULE_INTERNAL, UTF8EUC_JP EUC_JP, MULE_INTERNAL, SJIS, UTF8EUC_KR EUC_KR, MULE_INTERNAL, UTF8EUC_TW EUC_TW, BIG5, MULE_INTERNAL, UTF8GB18030 not supported as a server encodingGBK not supported as a server encodingISO_8859_5 ISO_8859_5, KOI8, MULE_INTERNAL, UTF8, WIN866, WIN1251ISO_8859_6 ISO_8859_6, UTF8ISO_8859_7 ISO_8859_7, UTF8ISO_8859_8 ISO_8859_8, UTF8JOHAB JOHAB, UTF8KOI8 KOI8, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251LATIN1 LATIN1, MULE_INTERNAL, UTF8LATIN2 LATIN2, MULE_INTERNAL, UTF8, WIN1250LATIN3 LATIN3, MULE_INTERNAL, UTF8LATIN4 LATIN4, MULE_INTERNAL, UTF8LATIN5 LATIN5, UTF8LATIN6 LATIN6, UTF8LATIN7 LATIN7, UTF8LATIN8 LATIN8, UTF8LATIN9 LATIN9, UTF8LATIN10 LATIN10, UTF8MULE_INTERNAL MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8, LATIN1 to LATIN4, SJIS, WIN866, WIN1250, WIN1251SJIS not supported as a server encodingSQL_ASCII any (no conversion will be performed)UHC not supported as a server encodingUTF8 all supported encodingsWIN866 WIN866, ISO_8859_5, KOI8, MULE_INTERNAL, UTF8, WIN1251WIN874 WIN874, UTF8WIN1250 WIN1250, LATIN2, MULE_INTERNAL, UTF8WIN1251 WIN1251, ISO_8859_5, KOI8, MULE_INTERNAL, UTF8, WIN866WIN1252 WIN1252, UTF8WIN1253 WIN1253, UTF8WIN1254 WIN1254, UTF8WIN1255 WIN1255, UTF8WIN1256 WIN1256, UTF8WIN1257 WIN1257, UTF8WIN1258 WIN1258, UTF8 |
以下针对客户端与服务器字符集配置问题作几个小测试。
测试一:服务器、客户端、语言环境一致的情况
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
[postgre@iss3984 ~]$ echo $LANGen_US.UTF-8[postgre@iss3984 ~]$ psql daduxiongWelcome to psql 8.3.11 (server 8.3.10), the PostgreSQL interactive terminal. Type: \copyright for distribution terms \h for help with SQL commands \? for help with psql commands \g or terminate with semicolon to execute query \q to quit daduxiong=# \l List of databases Name | Owner | Encoding-----------+---------+---------- daduxiong | postgre | UTF8 postgres | postgre | UTF8 template0 | postgre | UTF8 template1 | postgre | UTF8(4 rows) daduxiong=# show client_encoding; client_encoding----------------- UTF8(1 row) daduxiong=# insert into t1 values (1,‘中国‘);INSERT 0 1daduxiong=# select * from t1; id | name ----+------------------------ | 中国 (1 row) |
服务器与客户端字符集相同,在数据录入时不发生字符集转换;因语言环境也相同所以展现不会出现乱码。
测试二:客户端与服务器、语言环境不一致的情况
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
daduxiong=# \encoding GBKdaduxiong=# show client_encoding; client_encoding----------------- GBK(1 row) daduxiong=# insert into t1 values (2,‘日本‘);INSERT 0 1daduxiong=# select * from t1; id | name ----+------------------------- | ?й? | 日本 (2 rows) |
客户端与服务器的字符集不一致,在数据录入时将发生字符集转换;当前展现的第二条记录非乱码形式是因为客户端字符集为GBK,在UTF8下同样出现乱码,在使用时需要语言环境进行配置。
测试三:服务器与客户端、语言环境不一致的情况
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
daduxiong=# \q[postgre@iss3984 ~]$ LANG=GBK export LANG[postgre@iss3984 ~]$ echo $LANGGBK[postgre@iss3984 ~]$ psql daduxiongWelcome to psql 8.3.11 (server 8.3.10), the PostgreSQL interactive terminal. Type: \copyright for distribution terms \h for help with SQL commands \? for help with psql commands \g or terminate with semicolon to execute query \q to quit daduxiong=# show client_encoding; client_encoding----------------- UTF8(1 row) daduxiong=# \encoding GBKdaduxiong=# select * from t1; id | name ----+------------------------- | ?й? | 日本 (2 rows) daduxiong=# insert into t1 values (3,‘美国‘);INSERT 0 1daduxiong=# select * from t1; id | name ----+------------------------- | ?й? | 日本 | 美国 (3 rows)daduxiong=# \q |
客户端、语言环境均配置为GBK字符集,在当前环境下展现的为非乱码形式,数据录入时将发生字符集转换。
测试四:服务器与客户端、语言环境恢复一致的情况
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
[postgre@iss3984 ~]$ LANG=en_US.UTF8 export LANG[postgre@iss3984 ~]$ psql daduxiongWelcome to psql 8.3.11 (server 8.3.10), the PostgreSQL interactive terminal. Type: \copyright for distribution terms \h for help with SQL commands \? for help with psql commands \g or terminate with semicolon to execute query \q to quit daduxiong=# show client_encoding; client_encoding----------------- UTF8(1 row) daduxiong=# select * from t1; id | name ----+------------------------- | 中国 | 鏃ユ湰 | 缇庡浗 (3 rows) daduxiong=# |
通过恢复原始的字符集状态,所有环境均为UTF8字符集,此时发现经过字符集转换后的内容为乱码
PG支持客户端和服务器端编码方式设置,如果两端编码一样,则在存取时不进行任何转换;如果不一样则自动进行转换。但其支持的有些编码只能用在服务端,不能用在客户端。
详细可参考其官方文档http://www.postgresql.org/docs/9.2/interactive/multibyte.html。支持简体中文有四种编码:EUC_CN(Extended UNIX Code-CN)、GB18030、GBK和UTF-8。但GB18030和GBK只能作为客户端编码,不能设置为服务端编码;由于Windows上又不支持EUC_CN编码,所以在Windows上服务端编码只能设为UTF-8。
下面通过两个简单的示例,来说明其编码转换过程。
数据:表test,字段name,类型text
示例一 客户端编码和服务端编码之间的转换(使用psgl)
1、服务端编码为UTF-8,客户端工具psgl默认为GBK

2、在此环境下插入“汉字”,一切正常。此时传到客户的“汉字”为GBK编码,自动转为UTF-8编码存到服务端;而查询时,又自动将服务端的UTF-8编码转为GBK来显示,所以没有出现乱码。

3、将客户端编码设置为UTF-8,则刚才插入的“汉字”不能正常显示。因为此时客户端和服务端的编码一样,在取数据时不进行任何转换,直接将存在服务端的UTF8编码的字节传到客户端,之后psgl直接显示,所以就乱码了。

4、在此环境下插入“汉字”,则添加不成功,因为“汉字”直接以GBK的形式传到服务端,UTF8编码不认识,所以就报错。(现在客户端编码为UTF8,所以提示的中文信息也乱码了)。

总结:1、在此示例中,应用程序psgl,对所输入和获取的字符没做任何处理,直接显示,其使用了pg客户端一样的编码方式(GBK)。
2、在使用时尽量保证客户端编码和操作系统环境一致,不然显示和添加就会出现乱码情况。
示例二 应用程序、客户端和服务端编码转换(pgAdmin3可视化界面)
pgAdmin3内部使用UTF8编码,是我根据下面的现象猜测的,没看源代码。
1、通过pgAdmin3查看在服务器以UTF8编码存储的“汉字”
Ø 在查询窗口中执行show client_encoding;可见pgAdmin3的默认客户端编码为UNICODE(在pg中为UTF8的别名)。查询select * from test,能正常显示“汉字”。
Ø 重设客户端编码set client_encoding to ‘GBK‘;后再查询,却无法显示“汉字”。
在客户端编码为GBK的psgl中能正常显示的“汉字“到客户端编码为GBK的pgAdmin3中却无法显示。这是由于pgAdmin3与psgl内部使用了不同的编码方式所造成的:
应用程序psgl使用与pg客户端一样的编码方式,对从操作系统所得到的字符直接传给pg客户端,对从pg客户端所得到的字符直接传给操作系统显示。
应用程序pgAdmin3内部可能统一使用的是UTF8编码,对从操作系统所得到的字符(ANSI本地编码)要先转成UTF8编码后再传给pg客户端;对从pg客户端所得到的字符要先转成ANSI本地编码后再传给操作系统显示。
对于pgAdmin3 client_encoding = ‘GBK‘ 时,“汉字“转换流程: UTF8 àGBKàGBK;
pgAdmin3把本来是转后GBK编码的字符又当成UTF8进行转换,所以无法显示(转后没有对应的字符)。
对于pgAdmin3 client_encoding = ‘UTF8‘ 时,“汉字“转换流程:UTF8 à GBK;
此时客户端与服务端编码一样,不用转,直接将得到的字符转成GBK,所以能正常显示。
2、在client_encoding = ‘GBK’ 环境下,插入“汉字G“
此时pgAdmin3把ANSI编码的“汉字G“转成UTF8编码给客户端,因为客户端编码为GBK和服务端编码不一样,所以数据库又将其作为GBK编码转成UTF8编码进行存储。本来就已经是UTF8编码的字符又作为GBK编码转成UTF8,存储字符就是错的了。但查询时却能正常显示,因为在此环境逆转换的字符还是正确的。
3、在client_encoding = ‘UTF8’ 环境下,插入“汉字U“
此时pgAdmin3把ANSI编码的“汉字G“转成UTF8编码给客户端,因为客户端编码为UTF8和服务端编码一样,不进行任何转换直接存储。查询时在此环境下逆转换后也是正确的,因此也能正常显示。
总结:
1、pgAdmin3内部使用UTF8编码,并将pg客户端也设为UTF8编码,如果服务端也设为UTF8时,pgAdmin3就比较强大了,可以支持各国语言,存取各国文字,就没有国际化问题了。并且在存取时只用在本地的ANSI编码和UTF8编码之间转换一次即可。
2、应用程序内部应尽量使用与数据库客户端相同的编码(或传给客户端的字符编码与客户端编码相同),以保证存到库里的字符是正确的;数据库客户端与服务端编码如不一样,数据库自身会自动转换后存储。
验证pgAdmin3内部使用UTF8编码:用encode查看字符在数据库的存储字节
set client_encoding to ‘UTF8‘;
select encode(‘汉字‘,‘hex‘) from test;
输出:"e6b189e5ad97" 为“汉字”的UTF-8编码。
set client_encoding to ‘GBK‘;
select encode(‘汉字‘,‘hex‘) from test;
输出:" "e5a7b9e5a48ae793a7" 为将"e6b189e5ad97"作为GBK编码转换为UTF-8后的编码。
当初学者在使用PostgreSQL数据库,输入中文时,会遇到“ERROR: invalid byte sequence for encoding "UTF8": 0xd6d0”的错误,原因是由于没有正确设置客户端字符集。
PostgreSQL编码格式:客户端服务器、客户端、服务器端相关影响
标签:输入 databases 查看 encode 解决方法 编码转换 desc 验证 原因
原文地址:https://www.cnblogs.com/kuang17/p/11378845.html