标签:区别 失败 散列 判断 也会 优先级 target ati link
我们知道在 Java 中最常用的两种结构是数组和模拟指针(引用),几乎所有的数据结构都可以利用这两种来组合实现,HashMap 也是如此。实际上 HashMap 是一个**“链表散列”**。
HashMap 是基于 hashing 的原理。
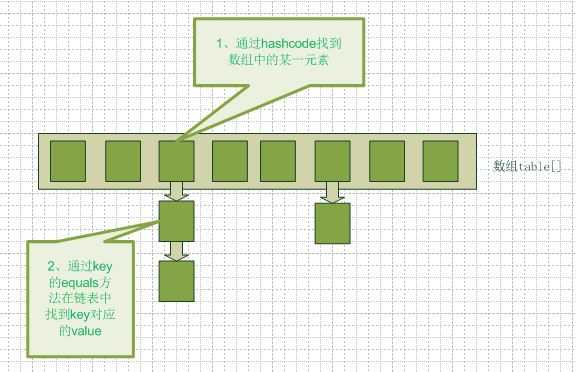
#put(key, value) 方法来存储对象到 HashMap 中,使用 get(key) 方法从 HashMap 中获取对象。#put(key, value) 方法传递键和值时,我们先对键调用 #hashCode() 方法,返回的 hashCode 用于找到 bucket 位置来储存 Entry 对象。?? 当两个对象的 hashCode 相同会发生什么?
因为 hashcode 相同,所以它们的 bucket 位置相同,“碰撞”会发生。
因为 HashMap 使用链表存储对象,这个 Entry(包含有键值对的 Map.Entry 对象)会存储在链表中。
?? hashCode 和 equals 方法有何重要性?
HashMap 使用 key 对象的 #hashCode() 和 #equals(Object obj) 方法去决定 key-value 对的索引。当我们试着从 HashMap 中获取值的时候,这些方法也会被用到。
#hashCode() 和 #equals(Object obj) 输出,HashMap 将会认为它们是相同的,然后覆盖它们,而非把它们存储到不同的地方。同样的,所有不允许存储重复数据的集合类都使用 #hashCode() 和 #equals(Object obj) 去查找重复,所以正确实现它们非常重要。#hashCode() 和 #equals(Object obj) 方法的实现,应该遵循以下规则:
o1.equals(o2) ,那么 o1.hashCode() == o2.hashCode() 总是为 true 的。o1.hashCode() == o2.hashCode() ,并不意味 o1.equals(o2) 会为 true 。?? HashMap 默认容量是多少?
默认容量都是 16 ,负载因子是 0.75 。就是当 HashMap 填充了 75% 的 busket 是就会扩容,最小的可能性是(16 * 0.75 = 12),一般为原内存的 2 倍。
?? 有哪些顺序的 HashMap 实现类?
?? 我们能否使用任何类作为 Map 的 key?
我们可以使用任何类作为 Map 的 key ,然而在使用它们之前,需要考虑以下几点:
1、如果类重写了 equals 方法,它也应该重写 hashcode 方法。
2、类的所有实例需要遵循与 equals 和 hashcode 相关的规则。
3、如果一个类没有使用 equals ,你不应该在 hashcode 中使用它。
比如,我有一个 类MyKey ,在 HashMap 中使用它。代码如下:
//传递给MyKey的name参数被用于equals()和hashCode()中
|
?? HashMap 的长度为什么是 2 的幂次方?
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。
这个算法应该如何设计呢?我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了:
%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash % length == hash & (length - 1) 的前提是 length 是 2 的 n 次方;)。&,相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
HashSet 是构建在 HashMap 之上的 Set hashing 实现类。让我们直接撸下源码,代码如下:
// HashSet.java
|
map 属性,当我们创建一个 HashMap 对象时,其内部也会创建一个 map 对象。后续 HashSet 所有的操作,实际都是基于这个 map 之上的封装。PRESENT 静态属性,所有 map 中 KEY 对应的值,都是它,避免重复创建。OK ,再来看一眼 add 方法,代码如下:
// HashSet.java
|
?? HashSet 如何检查重复?
艿艿:正如我们上面看到 HashSet 的实现原理,我们自然可以推导出,HashMap 也是如何检查重复滴。
如下摘取自 《Head First Java》 第二版:
当你把对象加入 HashSet 时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较。
如果没有相符的 hashcode ,HashSet会假设对象没有重复出现。
但是如果发现有相同 hashcode 值的对象,这时会调用 equals 方法来检查 hashcode 相等的对象是否真的相同。
java.util.EnumSet ,是使用枚举类型的集合实现。
当集合创建时,枚举集合中的所有元素必须来自单个指定的枚举类型,可以是显示的或隐示的。EnumSet 是不同步的,不允许值为 null 的元素。
它也提供了一些有用的方法,比如 #copyOf(Collection c)、#of(E first, E... rest) 和 #complementOf(EnumSet s) 方法。
关于 EnumSet 的源码解析,见 《EnumSet 源码分析》 文章。
Java 中的 TreeMap 是使用红黑树实现的。
TODO TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方法如何比较元素?
等到源码解析后,在进行补充。
PriorityQueue 是一个基于优先级堆的无界队列,它的元素都以他们的自然顺序有序排列。
在它创建的时候,我们可以可以提供一个比较器 Comparator 来负责PriorityQueue 中元素的排序。
PriorityQueue 不允许 `` null元素,不允许不提供自然排序的对象,也不允许没有任何关联 Comparator 的对象。
最后,PriorityQueue 不是线程安全的,在执行入队和出队操作它需要 O(log(n)) 的时间复杂度。
?? poll 方法和 remove 方法的区别?
poll 和 remove 方法,都是从队列中取出一个元素,差别在于:
?? LinkedHashMap 和 PriorityQueue 的区别是什么?
标签:区别 失败 散列 判断 也会 优先级 target ati link
原文地址:https://www.cnblogs.com/zwhu1216/p/11386220.html