标签:nat 模拟 自己 let 利用 one plt 遍历 sibling
---恢复内容开始---
| 方法 | 描述 |
|
requests.request() |
构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTPde POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTTP页面提交删除的请求,对应于HTTP的DELETE |
import requests def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status()#如果状态不是200,引发HTTPError异常 r.encoding=r.apparent_encoding return r.text except: return "产生异常" if __name__=="__main__": url="http://www.baidu.com" print(getHTMLText(url))
连接有风险,异常处理很重要
#注释 *代表所有 / 代表根目录
user-agent: *
Disallow: /
查看头部信息r.request.headers user_agent字段为python-requests被拒绝访问,因此修改头部信息user-agent字段为模拟浏览器首先构造一个键值对
kv={‘user-agent‘:‘Mozilla/5.0‘} #重新定义user-agent的内容
通过headers字段让代码模拟浏览器放亚马逊服务器提供HTTP请求
import requests url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y" try: kv={‘user-agent‘:‘Mozilla/5.0‘} #标准浏览器 r=requests.get(url,headers=kv) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[1000:2000]) except: print("爬取失败")
百度,360搜索关键字提交
import requests keyword = ‘python‘ try: kv={‘wd‘:keyword} r = requests.get("http://www.baidu.com/s",params=kv) r.raise_for_status print(len(r.text)) except: print("爬取失败")
360搜索代码只需将键值对中的键‘wd‘改为‘q‘
若 一个url链接是以.jpg结尾的,例如http://www.example.com/picture.jpg他就是一个图片链接,且是一个文件
import requests import os url =‘http://image.nationalgeographic.com.cn/2017/0211/201702111061910157.jpg‘ root="D://pics//" path=root+url.split(‘/‘)[-1] try: if not os.path.exists(root):#判断当前根目录是否存在,如果根目录不存在,则建立目录 os.mkdir(root) if not os.oath.exists(path):#判断文件是否存在,文件不存在用get方式从网上获取相关文件 r=requests.get(url) with open(path,‘wb‘) as f: f.write(r.content) f.close() print("文件保存成功") else: print("文件已存在") except: print("爬取失败")
import requests url = "http://m.ip138.com/ip.asp?ip=" try: r=requests(url+‘202.204.80.112‘) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[-500:]) except: print("爬取失败")
每一个API都对应一个URL,以爬虫的视角看待网络内容
demo.html
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
demo
BeautifulSoup库安装小测
from bs4 import BeautifulSoup soup = BeautifulSoup(demo,"html.parser") print(soup.prettify())
from bs4 import BeautifulSoup import bs4

from bs4 import BeautifulSoup soup = BeautifulSoup(‘<htnl>data</html>‘,""html.parser") soup2 = BeautifulSoup(open(‘D://demo.html‘),"html.parser")
BeautifulSoup类对应一个HTML/XML文档的全部内容


Tag:任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当html文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。
Name:每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型。
Attributes:一个<tag>可以有0个或多个属性,字典类型。
Navigablestring:可以跨越多个层次。
Comment:特殊类型(注释)。
<>.....</>构成了所属关系,形成了标签的属性结构

for child in soup.body.children: print(child) #遍历儿子节点
for child in soup.body.descendant: print(child) #遍历子孙节点

soup = BeautifulSoup(demo,"html.parser") for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)
遍历所有先辈节点,包括soup本身,所以要区别判断。
运行结果
p
body
html
[document]

平行遍历的条件:所有的平行遍历必须发生在同一个父节点下,如果不是同一个父亲节点下的标签之间不构成平行遍历关系。
注意:
在标签树中,尽管树形结构采用的是标签的形式来组织,但是标签之前的Navigablestring也构成了标签树的节点。即任何一个节点的平行标签他的儿子标签是可能存在Navigablestring类型的,所以不能想当然地认为平行遍历获得的下一个节点一定是标签类型。
for sibling in soup.a.next_siblings: print(sibling) #遍历后续节点 for sibling in soup.a..previous_siblings: print(sibling) #遍历前序节点
prettify()方法:
可以为HTML文本的标签以及内容增加换行符,也可以对每一个标签做相关处理
bs4库将任何读入的HTML或字符串都转换为utf-8编码,python3.x默认支持编码是utf-8,解析无障碍
form bs4 import BeautifulSoup soup = BeautifulSoup(demo,"html.parser") soup.prettify() print(soup.prettify())

使用有类型的键值将信息组织起来,值的地方有多个地方与键相对应,采用 [ ]形式,将新的键值对作为值的一部分放在键值对中,采用{ }形式进行嵌套

无类型的键值对组织信息,兼职之间无“ ”,用缩进来表示所属相关关系。- 表达并列关系,| 表达整块数据,# 表示注释信息,键值对之间可以嵌套

xml:每个信息域定义相关的标签,并且采用嵌套的形式组织起来(大多数信息被标签占用)

json:键值之间用“ ”来表达类型

ymal







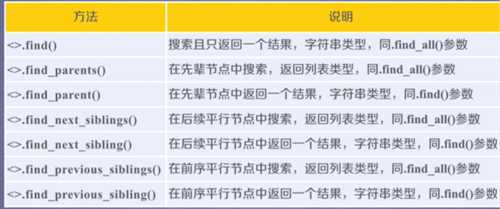
find_all()

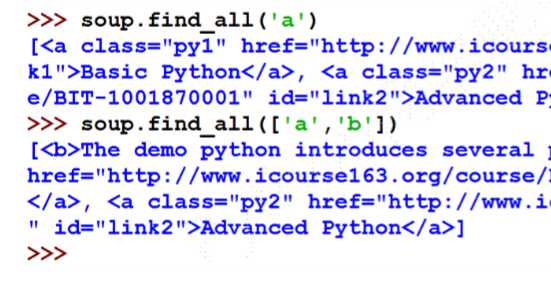

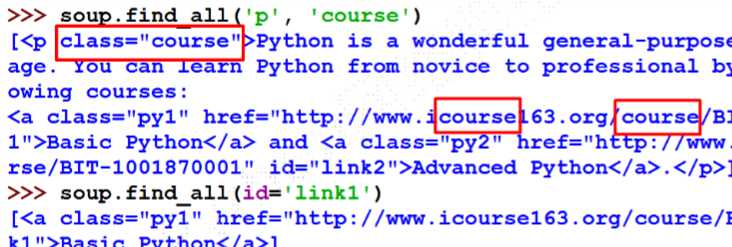

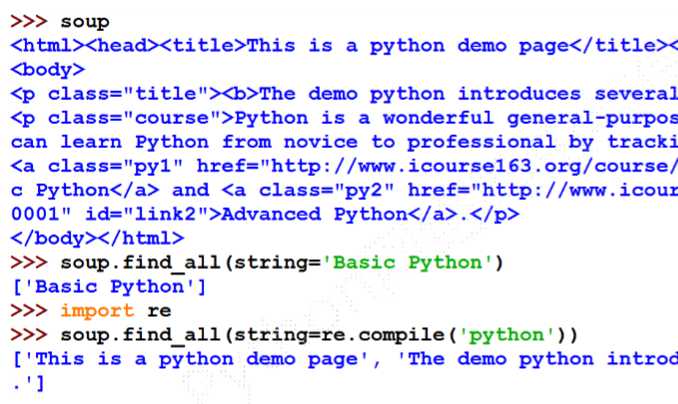
等价形式:
<tag>(..)等价于<tag>.find_all(..)
soup(..)等价于soup.find_all(..)
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): #从网络上获取大学排名网页内容 try: r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist,html): #提取网页内容中信息到合适的数据结构 soup = BeautifulSoup(html,"html.parser") for tr in soup.find(‘tbody‘).children: if isinstance(tr,bs4.element.Tag):#检测标签类型,若标签类型不是bs4库定义的Tag类型将被过滤掉 tds = tr(‘td‘) ulist.append([tds[0].string,tds[1].string,tds[3].string]) def printUnivList(ulist,num): #利用数据结构展示并输出结果 tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" #输出结果中中文对齐问题,当中文字符宽度不够采用西文字符填充;中西文宽度不同,采用中文字符的空格填充 chr(12288) print(tplt.format("排名","学校名称","总分",chr(12288))) for i in range (num): u=ulist[i] print(tplt.format(u[0],u[1],u[2],chr(12288))) print("Suc"+str(num)) def main(): uinfo = [] url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" html = getHTMLText(url) fillUnivList(uinfo,html) printUnivList(uinfo,20) #20univs main()

---恢复内容结束---
标签:nat 模拟 自己 let 利用 one plt 遍历 sibling
原文地址:https://www.cnblogs.com/SGzhang/p/11246387.html