标签:ges 系统 sele 最新 _id sts tps mod data-
此讲解版本为
4.0.0-RC1,目前最新的版本 2019年5月21日发布
t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
${['online', 'offline']}_table${1..3}最终解析为
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3通过解析SQL语句提取分片键列与值并进行分片是ShardingSphere对SQL零侵入的实现方式。若SQL语句中没有分片条件,则无法进行分片,需要全路由。
在一些应用场景中,分片条件并不存在于SQL,而存在于外部业务逻辑。因此需要提供一种通过外部指定分片结果的方式,在ShardingSphere中叫做Hint。
ShardingSphere使用ThreadLocal管理分片键值。可以通过编程的方式向HintManager中添加分片条件,该分片条件仅在当前线程内生效。
指定了强制分片路由的SQL将会无视原有的分片逻辑,直接路由至指定的真实数据节点。

dataSource方法,它会把shardingProperties配置进去,而shardingProperties的来源就是application.propertes中的配置属性####################################
# 分库分表配置
####################################
#actual-data-nodes:真实数据节点,由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds${0..1}.t_order_${0..1}
# 自定义分库分表算法
spring.shardingsphere.sharding.tables.t_order.databaseStrategy.complex.shardingColumns=order_id,user_id
spring.shardingsphere.sharding.tables.t_order.databaseStrategy.complex.algorithmClassName=com.xxx.shardingjdbc .cusalgo.algorithm.DbShardingAlgorithm
## 自定义分表算法
spring.shardingsphere.sharding.tables.t_order.tableStrategy.complex.shardingColumns=order_id,user_id
spring.shardingsphere.sharding.tables.t_order.tableStrategy.complex.algorithmClassName=com.xxx .shardingjdbc.cusalgo.algorithm.TableShardingAlgorithm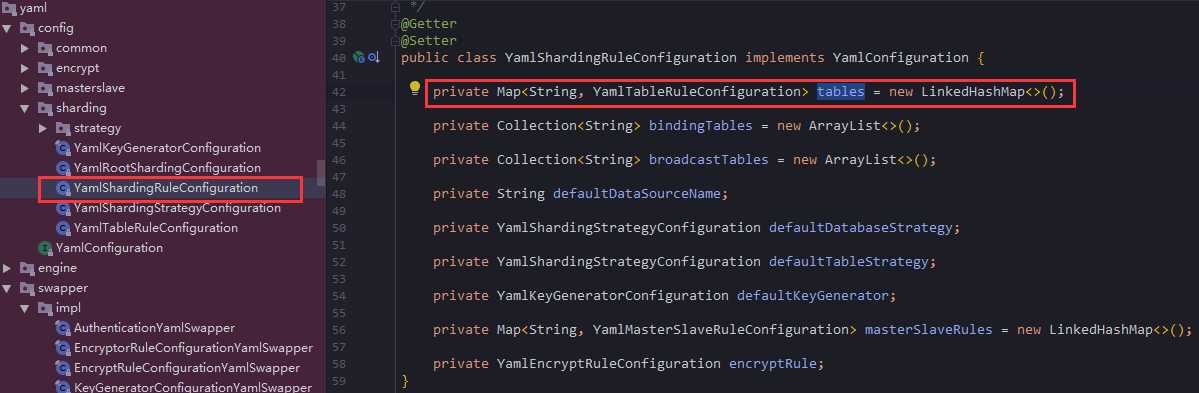
你可以看到除了tables,你还可以配置很多其他属性,bindingTables,broadcastTables等等,看名字也知道是绑定表和广播表,绑定表我第一章就讲到了,广播表理解也很简单,默认你不分库的就是广播表,也就是数据在所有分库分表的节点都保存一份
这里着重讲自定义配置类,上面配置文件配置了DbShardingAlgorithm这个类就是自定义类,它实现了ComplexKeysShardingAlgorithm
public class DbShardingAlgorithm implements ComplexKeysShardingAlgorithm {
private static Logger logger = LoggerFactory.getLogger(DbShardingAlgorithm.class);
// 取模因子
public static final Integer MODE_FACTOR = 1331;
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, Collection<ShardingValue> shardingValues) {
List<String> shardingResults = new ArrayList<>();
Long shardingIndex = getIndex(shardingValues) % availableTargetNames.size();
// loop and match datasource
for (String name : availableTargetNames) {
// get logic datasource index suffix
String nameSuffix = name.substring(2);
if (nameSuffix.equals(shardingIndex.toString())) {
shardingResults.add(name);
break;
}
}
logger.info("DataSource sharding index : {}", shardingIndex);
return shardingResults;
}
/**
* get datasource sharding index <p>
* sharding algorithm : shardingIndex = (orderId + userId.hashCode()) % db.size
* @param shardingValues
* @return
*/
private long getIndex(Collection<ShardingValue> shardingValues)
{
long shardingIndex = 0L;
ListShardingValue<Long> listShardingValue;
List<Long> shardingValue;
for (ShardingValue sVal : shardingValues) {
listShardingValue = (ListShardingValue<Long>) sVal;
if ("order_id".equals(listShardingValue.getColumnName())) {
shardingValue = (List<Long>) listShardingValue.getValues();
shardingIndex += Math.abs(shardingValue.get(0)) % MODE_FACTOR;
} else if ("user_id".equals(listShardingValue.getColumnName())) {
shardingValue = (List<Long>) listShardingValue.getValues();
// 这里 % 1313 仅仅只是防止溢出
shardingIndex += Math.abs(shardingValue.get(0).hashCode()) % MODE_FACTOR;
}
}
return shardingIndex;
}
}继续追踪进入
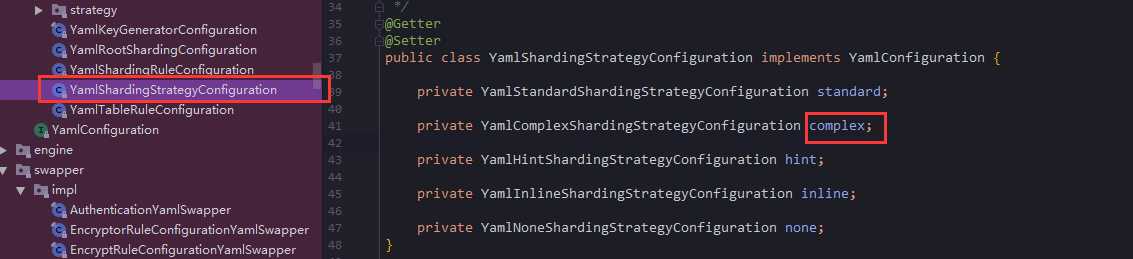
可以发现它总共实现了5个接口配置,上面的ComplexKeysShardingAlgorithm就来自complex的配置

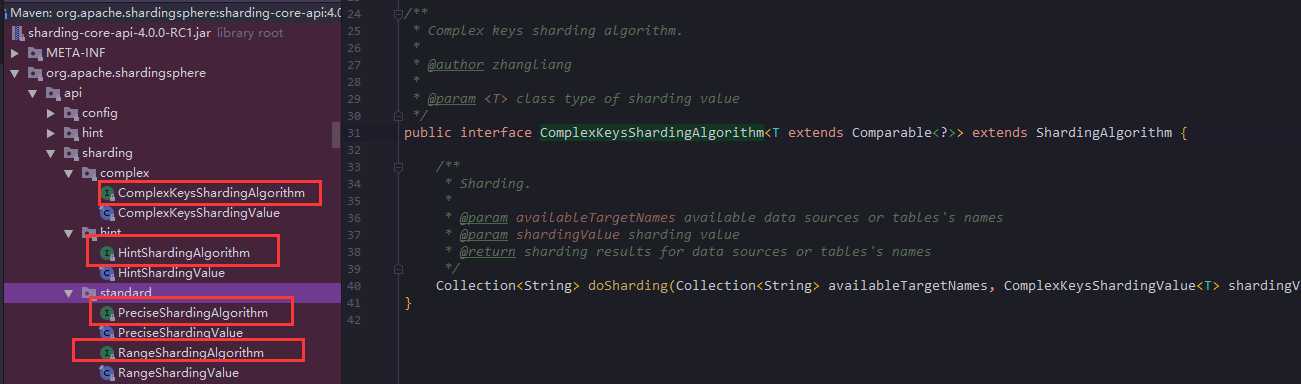
想要全面了解Sharding-jdbc和它相关组件的,移步这里
标签:ges 系统 sele 最新 _id sts tps mod data-
原文地址:https://www.cnblogs.com/sky-chen/p/11393659.html