标签:数字 line obj 变量 默认 char 正数 order das
字符串是Python中最常用的数据类型,可以使用单引号或双引号来创建字符串
创建字符串很简单,为变量分配一个值即可。
val1 = ‘hello world’
var2 = “Runoob”
Python访问字符串的值
Python不支持单字符类型,单字符在Python中也是作为 一个字符串使用
Python访问子字符串,可以使用方括号来截取字符串,如下:
/*** string.py ***/ var1 = ‘hello world‘ var2 = "runoob" print ("var1[0]: ",var1[0]); print ("var2[1:5]: ",var2[1:5])
运行结果:
robot@ubuntu:~/wangqinghe/python/20190822$ python3.5 string.py
var1[0]: h
var2[1:5]: unoo
Python字符串更新
可以截取字符串的一部分和其他字段拼接,如下:

Python转义字符
在需要在字符中使用特殊字符,python用反斜杠转义字符
|
转义字符 |
描述 |
|
\(在行尾) |
续行符 |
|
\\ |
反斜杠符 |
|
\’ |
单引号 |
|
\” |
双引号 |
|
\a |
响铃 |
|
\b |
退格(space) |
|
\000 |
空 |
|
\n |
换行 |
|
\v |
纵向制符表 |
|
\t |
横向制符表 |
|
\r |
回车 |
|
\f |
换页 |
|
\oyy |
八进制,yy表示字符, |
|
\xyy |
十六进制,yy表示字符 |
|
\other |
其他的字符以普通格式输出 |
Python字符串运算符
|
操作符 |
描述 |
|
+ |
字符串连接 |
|
* |
重复输出字符串 |
|
[] |
通过索引获取字符串中字符 |
|
[:] |
截取字符串一部分,遵循左闭右开原则 |
|
in |
成员运算符—如果字符中包含给定的字符返回true |
|
not in |
成员运算符—如果字符中不包含给定的字符返回true |
|
r/R |
原始字符串—原始字符串:所有的字符串都是直接按照字面意思来使用,没有转义特殊或不能打印的字符。原始字符串除在字符串的第一个引号前加上字母r(R)以外,与普通字符串有着几乎完全相同的语法 |
|
% |
格式化字符串 |
/*** arch.py ***/ a = "hello" b = "python" print("a + b is : ", a+b) print("a * 2 is : ", a*2) print("a[1] is : ",a[1]) print("a[1:4] is : ",a[1:4]) if("h" in a): print("h in a is true") else : print("h in a is false") if("m" not in a): print("m not in a is true") else: print("m not in ta is false") print (r‘\n‘) print (R‘\n‘)
运行结果:
robot@ubuntu:~/wangqinghe/python/20190822$ python3.5 archi.py
a + b is : hellopython
a * 2 is : hellohello
a[1] is : e
a[1:4] is : ell
h in a is true
m not in a is true
\n
\n
Pyt字符串格式化
Python支持格式化字符串输出,尽管这样可能会用到非常复杂的表达式,但是最基本的用法就是将一个值插入到一个有字符串格式符%s的字符串中
在Python中,字符串格式化使用与C中的sprintf函数一样的语法
print (“我叫 %s 今年 %d 岁!“ (‘小明’,10))
Python字符串格式化符号
|
符号 |
描述 |
|
%c |
格式化字符及其ASCII码 |
|
%s |
格式化字符串 |
|
%d |
格式化整数 |
|
%u |
格式化无符号整型 |
|
%o |
格式化无符号八进制数 |
|
%x |
格式化无符号十六进制数 |
|
%X |
格式化无符号十六进制数(大写) |
|
%f |
格式化浮点数,可指定小数点后的精度 |
|
%e |
用科学计数法格式化浮点数 |
|
%E |
作用同上 |
|
%g |
%f和%e的简写 |
|
%G |
%f和%E的简写 |
|
%p |
用十六进制数格式化变量的地址 |
格式化操作辅助指令
|
符号 |
功能 |
|
* |
定义宽度或者小数点精度 |
|
- |
用作左对齐 |
|
+ |
在正数前面显示加号 |
|
<sp> |
在正数前面显示空格 |
|
# |
在八进制数前显示零,在十六进制前面显示’0x’或‘0X’ |
|
0 |
显示的数字前面填充’0’而不是默认的空格 |
|
% |
‘%%’输出的一个单一的‘%‘ |
|
(var) |
映射变量(字典参数) |
|
m.n |
m是显示的最小的总宽度,n是小数点后的位数 |
Python三引号
Python三引号运行一个字符串跨多行,字符串中可以包含换行符、制表符、以及其他特殊字符。
Python的字符串内建函数
Python的字符串常用内建函数如下:
|
方法 |
描述 |
|
capitalize() |
将字符串第一个字符转换成大写 |
|
center(width,fillchar) |
返回一个指定的宽度width居中的字符串,fillchar为填充的字符,默认为空格 |
|
count(str,beg = 0,end = len(string)) |
返回str在string里面出现的次数,如果beg或end指定则返回指定返回内str出现的次数 |
|
bytes.decode(encoding=”utf-8”,errors=”strict”) |
bytes对象的decode()方法来解码给定的ebytes对象,这个bytes对象可以由str.encode()来编码返回 |
|
encode(encoding=’UTF-8’,errors=’strict’) |
以encoding指定的编码格式编码字符串,如果出错,则默认报一个ValueError的异常,除非errors指定的是’ignore’或者’replace’ |
|
endswith(suffix,beg=0,end=len(string)) |
检查字符串是否事宜obj结束,如果beg或end指定则检查指定的范围内是否以obj结束,如果是,返回true,反之返回false |
|
expandtabs(tabsize=8) |
把字符串string中的tab符号转换成空格, tab符号默认的空格数是8 |
|
find(str,beg=0,end=len(string)) |
检查str是否包含在字符串中,如果是指范围的beg和end,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
|
index(str,beg=0,end=len(string)) |
很find返回一样,只不过如果str不在字符串中会报一个异常 |
|
isalnum() |
如果字符串至少有一个字符,并且所有字符都是字母或数字返回true,否则返回false |
|
isalpha() |
如果字符串至少有一个字符,并且所有字符都是字母返回true,否则返回false |
|
isdigit() |
如果字符串只包含数字返回true否则返回false |
|
islower() |
如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回true,否则返回false |
|
isnumeric() |
如果字符串只包含数字字符返回true否则返回false |
|
isspace() |
如果字符串只包含空白返回true否则返回false |
|
istitle() |
如果字符串是标题化的则返回true,否则返回false |
|
isupper() |
如果字符串中包含至少一个区分大小写的而字符,并且这些字符都是大写,则返回true,否则返回false |
|
join(seq) |
以指定字符为分隔符,将seq中所有的元素合并为一个新的字符串 |
|
len(string) |
返回字符串长度 |
|
ljust(width[,fillchar]) |
返回一个原始字符串左对齐,并使用fillchar填充至长度width的新字符串,fillchar默认为空格 |
|
lower() |
转换字符串中的所有大写字符串为小写 |
|
lstrip() |
截掉字符串左边的空格或指定字符 |
|
maketrans() |
创建字符映射的转换表时,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标 |
|
min(str) |
返回字符串str中最小的字母 |
|
replace(old,new[,max]) |
将字符串中的str1替换成str2,如果max指定,则替换次数不超过maxn |
|
rfind(str,beg=0,end=lens(string)) |
类似find函数,从右开始找起 |
|
rindex(str,beg=0,end=len(string)) |
类似index函数,从右才是找起 |
|
rjust(width,[,fillchar]) |
返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度width的新字符串 |
|
rstrip() |
删除字符串末尾空格 |
|
split(str=””,num=string.count(str)) |
num=string.count(str)以str为分隔符截取字符串,如果num有指定值,则仅截取num+1个子字符串 |
|
splitlines([keepends ]) |
按照行(‘\r’,’\r\n’,’\n’)分隔,返回一个包含各行作为元素的列表。如果参数keepends为false,不包含换行符,如果为true则保留换行符 |
|
startwith(substr,beg=0,end=len(string)) |
检查字符串是否是以指定子字符串substr开头,是则返回true,否则返回false。如果beg和end指定值,则在指定范围内检查 |
|
strip([chars]) |
在字符串上执行istrip()和rstrip() |
|
swapcase() |
将字符串中大写转换成小写,小写转换成大写 |
|
title() |
返回“标题化“的字符串,也就是说所有的单词都是以大写开始,所有字母均为小写 |
|
tanslate(table,deltechars=””) |
根据str给出的表,转换成string的字符,要过滤掉的字符放到deletechars参数中 |
|
upper() |
转换字符串中的小写字母为大写 |
|
zfill(width) |
返回长度为width的字符串。原字符串右对齐,前面填充0 |
|
isdecimal() |
检查字符串是否包含十进制字符,如果是返回true,否则返回false |

[::2]表示从头到尾,步长为2,第一个冒号的两侧数字是截取字符串长度的范围,第二个冒号后面是指截取的步长
也可以使用负数从字符串右边尾部向左边反向索引,最右侧索引值为-1
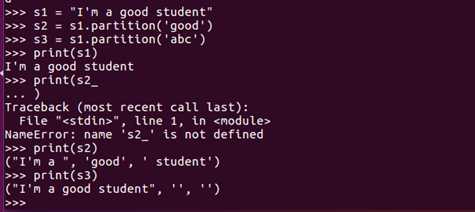
字符串分隔还有partition()的方式
partition(seq) ---- > (head,seq,tail)
从左向右遇到分隔符把字符串分割成两部分,返回头、分割符、尾三部分的三元组。如果没有找到分割符,就返回头、尾两个空元素的三元组。
python字符串格式化符号%f可指定小数点后的精度,同C的使用
g是自动选择输出格式,在六位数的情况下就会以科学计数法方式输出,
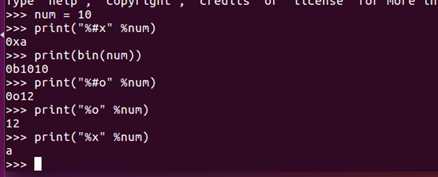
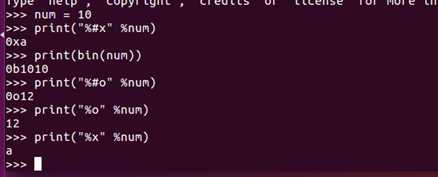
python输出二进制、八进制、十六进制的方法
counter升级使用:
IP掩码换算
/*** mask.py ***/ b = ‘1‘ bs_len = len(b) while bs_len < 9: b_b = b.ljust(8,‘0‘) d = int(b_b,2) print("binary %s is equal with %s" %(b_b,d)) b = b + "1" bs_len = len(b) 运行结果: robot@ubuntu:~/wangqinghe/python/20190822$ vim mask.py robot@ubuntu:~/wangqinghe/python/20190822$ python3.5 mask.py binary 10000000 is equal with 128 binary 11000000 is equal with 192 binary 11100000 is equal with 224 binary 11110000 is equal with 240 binary 11111000 is equal with 248 binary 11111100 is equal with 252 binary 11111110 is equal with 254 binary 11111111 is equal with 255
标签:数字 line obj 变量 默认 char 正数 order das
原文地址:https://www.cnblogs.com/wanghao-boke/p/11396050.html