这是个相当简单却有用的模块,主要用于打印复杂的数据结构对象,例如多层嵌套的列表、元组和字典等。
先看看 print() 打印的一个例子:
mylist = ["Beautiful is better than ugly.", "Explicit is better than implicit.", "Simple is better than complex.", "Complex is better than complicated."]
print(mylist)
# 结果如下:
[‘Beautiful is better than ugly.‘, ‘Explicit is better than implicit.‘, ‘Simple is better than complex.‘, ‘Complex is better than complicated.‘]这是一个简单的例子,全部打印在一行里。
想象一下,如果对象中的元素是多层嵌套的内容(例如复杂的 Json 数据),或者有超多的元素(例如在列表中存了很多 URL 链接),再打印出来会是怎样?
那肯定是一团糟的,不好阅读。
使用 pprint 模块的 pprint() 替代 print(),可以解决如下痛点:
- 设置合适的行宽度,作适当的换行
- 设置打印的缩进、层级,进行格式化打印
- 判断对象中是否出现无限循环,并优化打印内容
1、简单使用
语法:pprint(object, stream=None, indent=1, width=80, depth=None, *,compact=False)
默认的行宽度参数为 80,当打印的字符(character)小于 80 时,pprint() 基本上等同于内置函数 print(),当字符超出时,它会作美化,进行格式化输出:
import pprint
# 打印上例的 mylist
pprint.pprint(mylist)
# 打印的元素是换行的(因为超出80字符):
[‘Beautiful is better than ugly.‘,
‘Explicit is better than implicit.‘,
‘Simple is better than complex.‘,
‘Complex is better than complicated.‘]2、设置缩进为 4 个空格(默认为1)
pprint.pprint(mylist, indent=4)
[ ‘Beautiful is better than ugly.‘,
‘Explicit is better than implicit.‘,
‘Simple is better than complex.‘,
‘Complex is better than complicated.‘]3、设置打印的行宽
mydict = {‘students‘: [{‘name‘:‘Tom‘, ‘age‘: 18},{‘name‘:‘Jerry‘, ‘age‘: 19}]}
pprint.pprint(mydict)
# 未超长:
{‘students‘: [{‘age‘: 18, ‘name‘: ‘Tom‘}, {‘age‘: 19, ‘name‘: ‘Jerry‘}]}
pprint.pprint(mydict, width=20)
# 超长1:
{‘students‘: [{‘age‘: 18,
‘name‘: ‘Tom‘},
{‘age‘: 19,
‘name‘: ‘Jerry‘}]}
pprint.pprint(mydict, width=70)
# 超长2:
{‘students‘: [{‘age‘: 18, ‘name‘: ‘Tom‘},
{‘age‘: 19, ‘name‘: ‘Jerry‘}]}4、设置打印的层级(默认全打印)
newlist = [1, [2, [3, [4, [5]]]]]
pprint.pprint(newlist, depth=3)
# 超出的层级会用...表示
[1, [2, [3, [...]]]]5、优化循环结构的打印
当列表或其它数据结构中出现循环引用时,要完整打印出所有内容是不可能的。
所以 print 作了简化处理,就像上例一样,只打印外层的壳,而不打印内层循环的东西。
这种处理方式是简化了,但没有指出是谁导致了循环,还容易看漏。
pprint() 方法作了改进,遇到无限循环结构时,会表示成<Recursion on typename with id=number> 的格式。
还有个 saferepr() 方法,也是这样优化,而且返回的是个字符串:
newlist = [1, 2]
newlist.insert(0, newlist)
# 列表元素指向列表自身,造成循环引用
# 直接 print 的结果是:[[...], 1, 2]
pprint.pprint(newlist)
# [<Recursion on list with id=1741283656456>, 1, 2]
pprint.saferepr(newlist)
# ‘[<Recursion on list with id=1741283656456>, 1, 2]‘6、判断是否出现循环结构
有两个方法可以判断一个对象中是否出现无限循环:
pprint.isrecursive(newlist)
# True
pprint.isreadable(newlist)
# Falseisreadable() 除了能像 isrecursive() 一样判断循环,还能判断该格式化内容是否可被 eval() 重构。
以上就是 pprint 模块的快捷入门介绍,除此之外,还有 pformat() 方法、PrettyPrinter 类,以及某些参数的使用等内容,我觉得没有大用,就不多说了。
如若感兴趣,你可查阅:
- 官方介绍:https://docs.python.org/zh-cn/3/library/pprint.html
- 源码地址:https://github.com/python/cpython/blob/3.7/Lib/pprint.py
最后,还有两个小小的点:
1、用 pprint() 替换 print() 的技巧
在不考虑 print() 函数本身的参数的情况下,可以在引入 pprint 模块后,写上 “print = pprint.pprint”,令 print() 起到改头换面的效果:
import pprint
print = pprint.pprint
mylist = ["Beautiful is better than ugly.", "Explicit is better than implicit.", "Simple is better than complex.", "Complex is better than complicated."]
print(mylist)
# 可对比本文开头的例子
[‘Beautiful is better than ugly.‘,
‘Explicit is better than implicit.‘,
‘Simple is better than complex.‘,
‘Complex is better than complicated.‘]2、国人开发的 beeprint
国内某位 pan 同学在 Github 开源了个beeprint,明显是对标 pprint 的。
项目地址:https://github.com/panyanyany/beeprint
它优化了字典对象的打印,对于从其它语言转过来的同学而言(例如 Java),这是个福音:

它还优化了长文本的打印,支持自定义对象的打印,看起来不错。
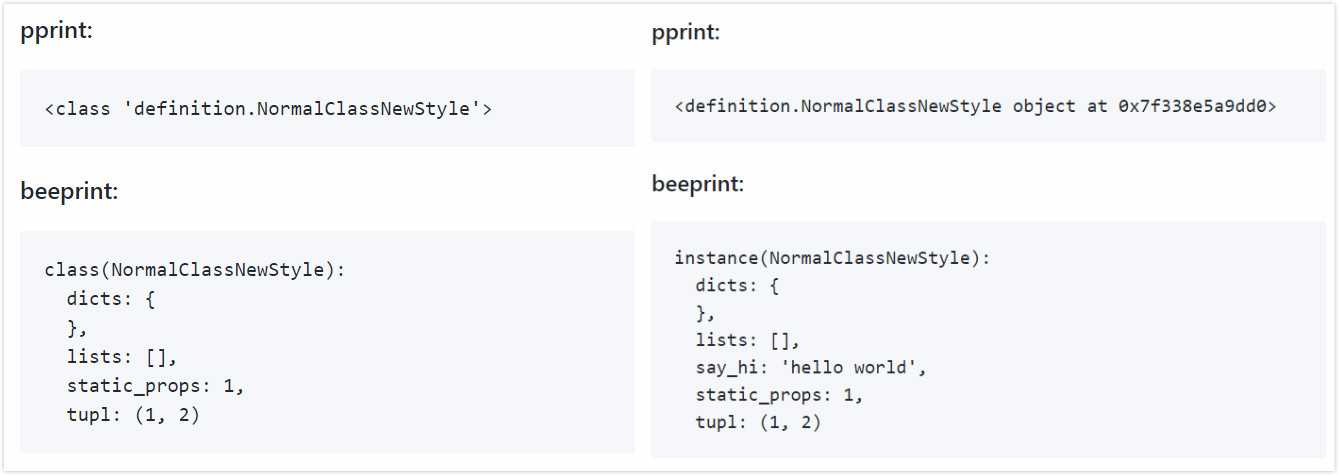
但是,其它功能不够齐全,而且作者停止维护两年了,荒废已久……
总体而言,pprint 算是 print() 的轻量级替代,简单实用,极其方便(毕竟是标准库),文档丰富而有保障。
所以,若想要打印美观易读的数据,这个 pprint 标准库,不妨一试哦。