标签:列表 html iterable 测试 map isp super python解释器 保存
a = input():用户从电脑输入一些字符,放到a中
a是一个变量,随便起什么名字都可以
print():
在括号中加上字符串,就可以向屏幕上输出指定的文字
print("这里写字符串")
接受多个字符串,用逗号“,”隔开,就可以连成一串输出
print("this","is","python")
tab : 4个空格
整数:任意大小的整数。无大小限制,整数运算永远是精确。
浮点数:小数。写法:数学写法,如1.23,3.14;科学计数法:1.23x10^9在程序中写成1.23e9,浮点数运算则可能会有四舍五入的误差
字符串:以单引号‘或双引号"括起来的任意文本。
布尔值:True,False。首字母大写。运算:and、or、not
空值:None
变量: 程序中就是用一个变量名,变量名必须是大小写英文、数字和_的组合,且不能用数字开头。
常量:全部大写的变量名表示常量,如PI=3.14159265359
注意:
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数
print(a)
a = 'ABC' # a变为字符串
print(a)这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下(// 表示注释):
int a = 123; // a是整数类型变量
a = "ABC"; // 错误:不能把字符串赋给整型变量总结:
/:
10 / 3 # 3.3333333333333335/除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数:
//:称为地板除,整数的地板除//永远是整数,即使除不尽。
10 // 3 # 3余数运算%,可以得到两个整数相除的余数:
10 % 3 # 1ASCII编码:由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,比如大写字母A的编码是65,小写字母z的编码是122。
Unicode编码:Unicode把所有语言都统一到一套编码里,解决各国编码方式不一样造成的乱码问题。但是存储空间大大;
UTF-8编码:一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
节省空间。
ASCII编码实际上可以被看成是UTF-8编码的一部分
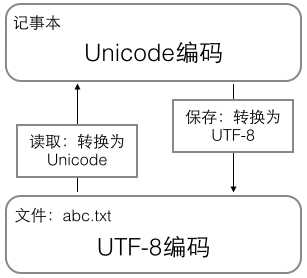
内存中使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,
读:UTF-8==>Unicode。硬盘到内存
保存:Unicode==>UTF-8。内存到硬盘
Python 3的字符串使用Unicode,直接支持多语言。
特性:不可修改
ord()函数获取字符的整数表示
chr()函数把编码转换为对应的字符
>>> ord('A')
65
>>> ord('中')
20013len():计算字符串长度
name.capitalize() 首字母大写
name.casefold() 大写全部变小写
name.center(50,"-") 输出 '---------------------Alex Li----------------------'
name.count('lex') 统计 lex出现次数
name.encode() 将字符串编码成bytes格式
name.endswith("Li") 判断字符串是否以 Li结尾
"Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格
name.find('A') 查找A,找到返回其索引, 找不到返回-1
msg.index('a') 返回a所在字符串的索引
'9aA'.isalnum() True
'9'.isdigit() 是否整数
name.isnumeric
name.isprintable
name.isspace
name.istitle
name.isupper
"|".join(['alex','jack','rain'])
'alex|jack|rain'
maketrans
>>> intab = "aeiou" #This is the string having actual characters.
>>> outtab = "12345" #This is the string having corresponding mapping character
>>> trantab = str.maketrans(intab, outtab)
>>>
>>> str = "this is string example....wow!!!"
>>> str.translate(trantab)
'th3s 3s str3ng 2x1mpl2....w4w!!!'
msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}')
>>> "alex li, chinese name is lijie".replace("li","LI",1)
'alex LI, chinese name is lijie'
msg.swapcase 大小写互换
>>> msg.zfill(40)
'00000my name is {name}, and age is {age}'
>>> n4.ljust(40,"-")
'Hello 2orld-----------------------------'
>>> n4.rjust(40,"-")
'-----------------------------Hello 2orld'
>>> b="ddefdsdff_哈哈"
>>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则
True| %d | 整数 |
|---|---|
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
%s把任何数据类型转换为字符串
字符串格式化符:.format
print("{} is eating {}.".format('benjie','meat'))
print("{a} is eating {b}.".format(a = 'benjie',b = 'meat'))
print('{0} is eating {1}.'.format('benjie','meat'))由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes
bytes类型:带b前缀的单引号或双引号表示:
x = b'ABC'"字符串".encode(): 字符串到bytes
b"字节".decode():bytes到字符串
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
特性:有序
访问列表中元素:list[index],索引是从0开始的:
names = ['benjie','jack','alex'] print(names[0]) # benjie print(names[1]) # jack print(names[2]) # alex # print(names[3])# IndexError: list index out of range
切片
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 ['Tenglan', 'Eric', 'Rain'] >>> names[1:-1] #取下标1至-1的值,不包括-1 ['Tenglan', 'Eric', 'Rain', 'Tom'] >>> names[0:3] ['Alex', 'Tenglan', 'Eric'] >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 ['Alex', 'Tenglan', 'Eric'] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 ['Rain', 'Tom', 'Amy'] >>> names[3:-1] #这样-1就不会被包含了 ['Rain', 'Tom'] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 ['Alex', 'Eric', 'Tom'] >>> names[::2] #和上句效果一样 ['Alex', 'Eric', 'Tom']
追加
>>> names = ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy'] >>> names.append("我是新来的") >>> names ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
插入
insert(index, p_object):
names = ['benjie','jack','alex'] names.insert(2,"新人") print(names) # ['benjie', 'jack', '新人', 'alex']
删除
del names[0] # 删第一个元素['jack', '新人', 'alex']
修改
names = ['benjie','jack','alex'] names[1] = "新换的" # ['benjie', '新换的', 'alex']
扩展
L.extend(iterable) -> None -- extend list by appending elements from the iterable
拷贝
names = ['benjie', 'jack', 'alex'] name_copy = names.copy() print(name_copy) # ['benjie', 'jack', 'alex']
统计
L.count(value) -> integer -- return number of occurrences of value
排序和翻转
>>> names ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] >>> names.sort() #排序 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦 >>> names[-3] = '1' >>> names[-2] = '2' >>> names[-1] = '3' >>> names ['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '1', '2', '3'] >>> names.sort() >>> names ['1', '2', '3', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom'] >>> names.reverse() #反转 >>> names ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
获取下标
names = ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1'] >>> names.index("Amy") 2 #只返回找到的第一个下标
只读列表。有序
特性:一旦创建不能修改。元组用来存放一些希望不被改变的值.
两个方法:count,index
tuple_test = ("alex","ben","alex","benjie")
print(tuple_test.index("alex")) # 0 获取该元素第一次出现的位置
print(tuple_test.count("alex")) # 2无序,元素不重复。
s = set([1, 2, 3])
>>> s
{1, 2, 3}传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
特性:
# -*- coding: utf-8 -*-
# Author:benjamin
# Date: 3.3
'''
list_1 = [1,4,5,7,6,7,8,3]
list_1 = set(list_1)
list_2 = set([2,5,6,0,66,22,8])
print(list_1 | list_2)#并
print(list_1 & list_2)#交
print(list_1 - list_2)#差集
print(list_1 ^ list_2)#对称差集
'''
list_1 = [10,7,5,7,6,7,8,3,2]
list_1 = set(list_1)
# 打印集合,自动去重;
print(list_1,type(list_1))
# {2, 3, 5, 6, 7, 8, 10} <class 'set'>
# 无序
list_2 = set([2,5,6,0,66,22,8])
print(list_1,list_2)
# {2, 3, 5, 6, 7, 8, 10} {0, 2, 66, 5, 6, 8, 22}
# 交集
print(list_1.intersection(list_2)) # {8, 2, 5, 6}
# 并集
print(list_1.union(list_2)) # {0, 2, 3, 66, 5, 6, 7, 8, 10, 22}
# 差集 in list_1 but not in list_2
print(list_1.difference(list_2)) # {10, 3, 7}
# 子集
print('list_1 is subset list-2',list_1.issubset(list_2)) # False
print('list_1 is superset list_2',list_1.issuperset(list_2)) # False
list_3 = set([2,7])
print(list_3.issubset(list_1)) # True
print(list_1.issuperset(list_3)) # True
# 对称差集 返回一个新的 set 包含 list1和 list2中不重复的元素
print(list_1.symmetric_difference(list_2)) # {0, 66, 3, 7, 22, 10}
# Return True if two sets have a null intersection.
print(list_2.isdisjoint(list_3)) # False
# 增
list_1.add(99)
print(list_1)
# 增一组
list_1.update([33,22,56])
print(list_1) # {33, 2, 3, 99, 5, 6, 7, 8, 10, 22, 56}
# 判断元素是否在集合中,用于条件判断
print('元素在list_1', {3333} in list_1)
print(list_1) # {33, 2, 3, 99, 5, 6, 7, 8, 10, 22, 56}
print(list_1.pop()) # 33
print(list_1.discard('7')) # None
print(list_1.discard('ssss')) # None
print(list_1.remove(8)) # Nonekey-value形式,无序,key唯一。
增
删
要删除一个key,用
pop(key)方法,对应的value也会从dict中删除:
改
查
1. key in dict 2. dict.get(key):方法不存在返回none 推荐使用
插
# -*- coding: utf-8 -*-
# Author:benjamin
# Date:
# 字典是无序的,输出不一定,通过key来取出。
#
info = {
'n1': '小明',
'n2': '小红',
'n3': '小张'
}
info1 = info
# 增
info['n4'] = '小来'
print(info)
# 删
info.pop('n4')
print(info)
# del 删
del info['n2']
print(info)
# 随机删
info.popitem()
print(info)
info = {'n1': '小明', 'n2': '小红', 'n3': '小张'}
# 改
info['n3'] = '呵呵'
print(info)
# 查
print('n3' in info) # True
print(info.get('n4')) # None get方法不存在返回none
# print(info['n6'])#Traceback (most recent call last): KeyError: 'n6' key不存在会报错
# 遍历
for i in info:
print(i, info[i])
# 会先把dict转成list,数据大时莫用
for k, v in info.items():
print(k, v)
# values
print(info.values()) # dict_values(['小红', '小明', '呵呵'])
# keys
print(info.keys()) # dict_keys(['n2', 'n1', 'n3'])
# setdefault
# D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D
info.setdefault('n10', 'alex')
print(info)
# update
b = {
1: 2,
3: 4,
'stu1101': 'tenglan wu'
}
info.update(b)
print(info)打开文件,得到文件句柄并赋值给一个变量
文件句柄=open(‘文件路径‘,‘模式’)
通过句柄对文件进行操作
read
readline
关闭文件
close
"+" 表示可以同时读写某个文件
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)b(rb,wb,ab)模式:不用加encoding:utf-8
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open("文件名","打开方式") as f:
操作文件修改
import os
with open('a.txt','r',encoding='utf-8') as read_f, open('a.txt.swap','w',encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')https://docs.pythontab.com/python/python3.4/index.html
https://www.cnblogs.com/haiyan123/p/8387770.html#lable2
https://www.cnblogs.com/alex3714/articles/5885096.html
标签:列表 html iterable 测试 map isp super python解释器 保存
原文地址:https://www.cnblogs.com/benjieqiang/p/11407919.html