标签:idt val 开头 span 注意 targe 数据 bash alt
#将old.sql文件中的符号“|”替换为“,”,并保存到test.sql文件中
sed "s/|/,/g" "old.sql"> test.sql
#将test.sql文件中的每一行最后的符号“,”删除
sed -i ‘s/,$//g‘ test.sql
#在test.sql文件中每行的开头添加左括号“(”
sed -i ‘s/^/(&/g‘ test.sql
#在test.sql文件中每一行的末尾添右括号“)”
sed -i ‘s/$/&)/g‘ test.sql
#统计文件old.sql的行数
c=`sed -n ‘$=‘ /home/work/BaikalDB/tpch/load/data_tbl/old.sql`
#在test.sql文件的第3行~3+99行的末尾添右括号“,”
sed -i "3,+99 s/$/&,/" test.sql
#在test.sql文件的第n行的开头添加“insert into table values”,这里的可以为具体的数字,也可以为变量的值,如j变量:${j}
sed -i "niinsert into table values " test.sql
#将test.sql文件的最后一行末尾的“,”换成“;”,这里的可以为具体的数字,也可以为变量的值,如j变量:${j}
sed -i "ns/,$/;/" test.sql
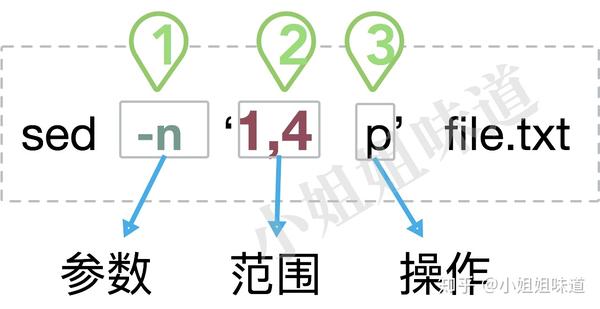
如图,一个简单的sed命令包含三个主要部分:参数、范围、操作。要操作的文件,可以直接挂在命令行的最后。除了命令行,sed也可以通过-f参数指定一个sed脚本,这个属于高级用法,不做过多描述。
有些示例命令我会重复多次,聪明如你一定能发现其中规律,有时连解释都用不着。
-n 这个参数是--quiet或者--silent的意思。表明忽略执行过程的输出,只输出我们的结果即可。
我们常用的还有另外一个参数 :-i。
使用此参数后,所有改动将在原文件上执行。你的输出将覆盖原文件。非常危险,一定要注意。
1,4 表示找到文件中1,2,3,4行的内容。
这个范围的指定很有灵性,请看以下示例(请自行替换图中的范围部分)。
5 选择第5行。
2,5 选择2到5行,共4行。
1~2 选择奇数行。
2~2 选择偶数行。
2,+3 和2,5的效果是一样的,共4行。
2,$ 从第二行到文件结尾。
范围的选择还可以使用正则匹配。请看下面示例。
/sys/,+3 选择出现sys字样的行,以及后面的三行。
/\^sys/,/mem/ 选择以sys开头的行,和出现mem字样行之间的数据。
为了直观,下面的命令一一对应上面的介绍,范围和操作之间是可以有空格的。
最常用的操作就是p,意思就是打印。比如,以下两个命令就是等同的:
除了打印,还有以下操作,我们来说常用的。
p 对匹配内容进行打印。
d 对匹配内容进行删除。这个时候就要去掉-n参数了,想想为什么。
w 将匹配内容写入到其他地方。
a,i,c等操作虽基本但使用少,不做介绍。我们依然拿一些命令来说明。
以上是sed命令的常用匹配模式,但它还有一个强大的替换模式,意思就是查找替换其中的某些值,并输出结果。使用替换模式很少使用-n参数。
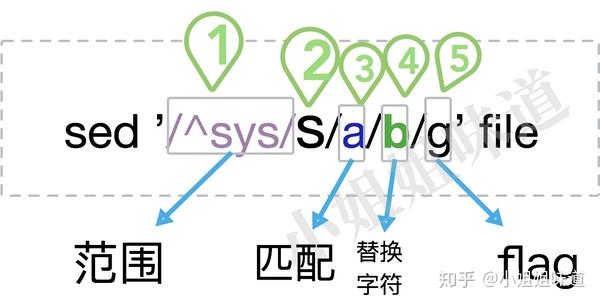
替换模式的参数有点多,但第一部分和第五部分都是可以省略的。替换后会将整个文本输出出来。
前半部分用来匹配一些范围,而后半部分执行替换的动作。
这个范围和上面的范围语法类似。看下面的例子。
/sys/,+3 选择出现sys字样的行,以及后面的三行。
/\^sys/,/mem/ 选择以sys开头的行,和出现mem字样行之间的数据。
具体命令为:
这里的命令是指s。也就是substitute的意思。
查找部分会找到要被替换的字符串。这部分可以接受纯粹的字符串,也可以接受正则表达式。看下面的例子。
a 查找范围行中的字符串a。
[a,b,c] 从范围行里查找字符串a或者b或者c。
命令类似:
是时候把找出的字符串给替换掉了。本部分的内容将替换查找匹配部分找到的内容。
可惜的是,这部分不能使用正则。常用的就是精确替换。比如把a替换成b。
但也有高级功能。和java或者python的正则api类似,sed的替换同样有Matched Pattern的含义,同样可以得到Group,不深究。常用的替位符,就是&。
&号,再重复一遍。当它用在替换字符串中的时候,代表的是原始的查找匹配数据。
[&] 表明将查找到的数据使用[]包围起来。
“&” 表明将查找的数据使用””包围起来。
下面这条命令,将会把文件中的每一行,使用引号包围起来。
这些参数可以单个使用,也可以使用多个,仅介绍最常用的。
g 默认只匹配行中第一次出现的内容,加上g,就可以全文替换了。常用。
p 当使用了-n参数,p将仅输出匹配行内容。
w 和上面的w模式类似,但是它仅仅输出有变换的行。
i 这个参数比较重要,表示忽略大小写。
e 表示将输出的每一行,执行一个命令。不建议使用,可以使用xargs配合完成这种功能。
看两个命令的语法:
由于正则的关系,很多字符需要转义。你会在脚本里做些很多\\,\*之类的处理。你可以使用|^@!四个字符来替换\。
比如,下面五个命令是一样的。
注意:前半部分的范围是不能使用这种方式的。我习惯使用符号@。
可以看到,正则表达式在命令行中无处不在。以下,紧做简要说明。
^ 行首
$ 行尾
. 单个字符
* 0个或者多个匹配
+ 1个或者多个匹配
? 0个或者1个匹配
{m} 前面的匹配重复m次
{m,n} 前面的匹配重复m到n次
\ 转义字符
[0-9] 匹配括号中的任何一个字符,or的作用
| or,或者
\b 匹配一个单词。比如\blucky\b 只匹配单词lucky
上面已经简单介绍了参数i,它的作用是让操作在原文件执行。无论你执行了啥,原始文件都将会被覆盖。这是非常危险的。
通过加入一个参数,可以将原文件做个备份。
以上命令会对原file文件生效,并生成一个file.bak文件。强烈建议使用i参数同时指定bak文件。
我们通过两个命令,来稍微看下sed和其他命令组合起来的威力。
输出长度不小于50个字符的行
统计文件中有每个单词出现了多少次
查找目录中的py文件,删掉所有行级注释
查看第5-7行和10-13行
仅输出ip地址
标签:idt val 开头 span 注意 targe 数据 bash alt
原文地址:https://www.cnblogs.com/yhlboke-1992/p/11413370.html