标签:次数 参考 www 匹配 排序 alt enc ever python实例
本实例主要用到python的jieba库
首先当然是安装pip install jieba
这里比较关键的是如下几个步骤:
加载文本,分析文本
txt=open("C:\\Users\\Beckham\\Desktop\\python\\倚天屠龙记.txt","r", encoding=‘utf-8‘).read() #打开倚天屠龙记文本 words=jieba.lcut(txt) #jieba库分析文本
对数据进行筛选和处理
for word in words: #筛选分析后的词组 if len(word)==1: #因为词组中的汉字数大于1个即认为是一个词组,所以通过continue结束点读取的汉字书为1的内容 continue elif word=="教主": #书中教主也指张无忌,即循环读取到教主也认为是张无忌这个名字出现一次,后面类似 rword="张无忌" elif word=="无忌": rword="张无忌" elif word=="义父": rword="谢逊" else: rword=word counts[rword]=counts.get(rword,0)+1 #对rword出现的频率进行统计,当rword不在words时,返回值是0,当rword在words中时,返回+1,以此进行累计计数 for word in exculdes:#如果循环读取到的词组与exculdes字典内的内容匹配,那么过滤掉(不显示)这个词组 del(counts[word])
创建列表显示和排序
items=list(counts.items())#字典到列表 items.sort(key=lambda x:x[1],reverse=True)#lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序 for i in range(15):#显示前15位数据 word,count=items[i] print("{0:<10}{1:>10}".format(word,count)) #0:<10左对齐,宽度10,”>10"右对齐
具体脚本如下,每一步都有解析,就不分步解释了
# -*-coding:utf8-*- # encoding:utf-8 import jieba #倒入jieba库 txt=open("C:\\Users\\Beckham\\Desktop\\python\\倚天屠龙记.txt","r", encoding=‘utf-8‘).read() #打开倚天屠龙记文本 exculdes={"说道","甚么","自己","武功","咱们","一声","心中","少林","一个","弟子", "明教","便是","之中","如何","师父","只见","怎么","两个","没有","不是","不知","这个","不能","只是", "他们","突然","出来","如此","今日","知道","我们","心想","二人","两人","不敢","虽然","姑娘","这时","众人" ,"可是","原来","之下","当下","身子","你们","脸上","左手","手中","倘若","之后","起来","喝道","武当派","跟着" ,"武当","却是","登时","身上","说话","长剑","峨嵋派","性命","难道","丐帮","兄弟","见到","魔教","不可","心下" ,"之间","少林寺","伸手","高手","一招","这里","正是"} #创建字典,主要用于存储非人物名词,供后面剔除使用 words=jieba.lcut(txt) #jieba库分析文本 counts={} for word in words: #筛选分析后的名词 if len(word)==1: #因为词组中的汉字数大于1个即认为是一个词组,所以通过continue结束掉读取的汉字书为1的内容 continue elif word=="教主": #书中教主也指张无忌,即循环读取到教主也认为是张无忌这个名字出现一次,后面类似 rword="张无忌" elif word=="无忌": rword="张无忌" elif word=="义父": rword="谢逊" else: rword=word counts[rword]=counts.get(rword,0)+1 #对rword出现的频率进行统计,当rword不在words时,返回值是0,当rword在words中时,返回+1,以此进行累计计数 for word in exculdes:#如果循环读取到的词组与exculdes字典内的内容匹配,那么过滤掉(不显示)这个词组 del(counts[word]) items=list(counts.items())#字典到列表 items.sort(key=lambda x:x[1],reverse=True)#lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序 for i in range(15):#显示前15位数据 word,count=items[i] print("{0:<10}{1:>10}".format(word,count)) #0:<10左对齐,宽度10,”>10"右对齐
毫无疑问,张无忌妥妥的主角
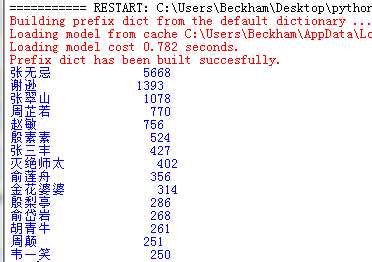
参考:
https://gitee.com/huangshenru/codes/clneriovm0sqxw5k89j2h98
https://www.cnblogs.com/0330lgs/p/10648168.html
python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序
标签:次数 参考 www 匹配 排序 alt enc ever python实例
原文地址:https://www.cnblogs.com/becks/p/11421214.html