注意!在做conditional gan的时候,G的输入是noise和condition,但是D不能只看G的输出,如果那样的话generator只会学着去产生真实的图片,而无视条件。
条件生成这件事能不能做到unsupervised?
比如什么风格转换之类的。问题就是怎么建立c和x之间的联系,手里只有两种数据而已。
方法1. 直接转换
D是输入带风格的图片和生成数据,训练去能够判断输入图片是不是属于目标的输出domain
G就是输入原始图片,训练去让D无效,并且要让G的输入和输出还是保持一定的联系。
比如cycleGAN,starGAN
方法2. 如果输入和输出差距很大,比如真人转换为动漫图像
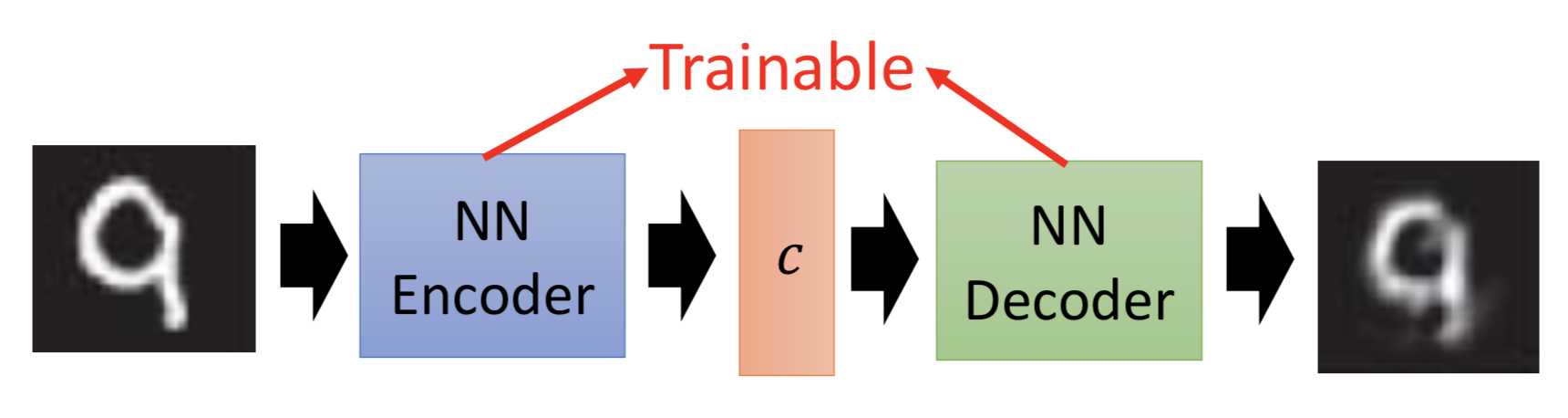
用encoder投到common space(latent space)上去做
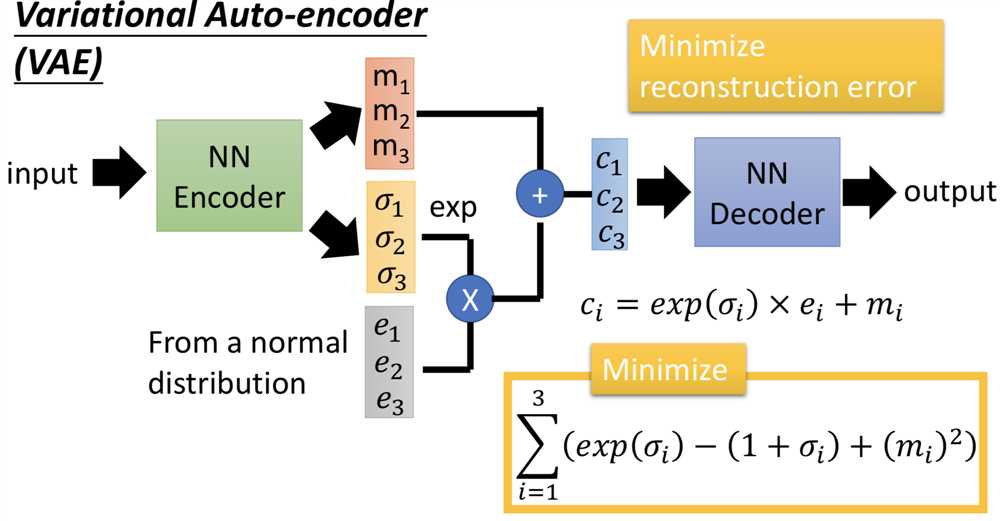
VAEGAN
encoder -> decoder -> discriminator,两部分损失,ae的重构损失,和gan的对抗损失
还可以在encoding vector 后面加一个domain discriminator,强制不同domain的输入经过encoder之后都投到一个latent space里面
gan部分的理论,最开始的版本。这里面其实有一些问题
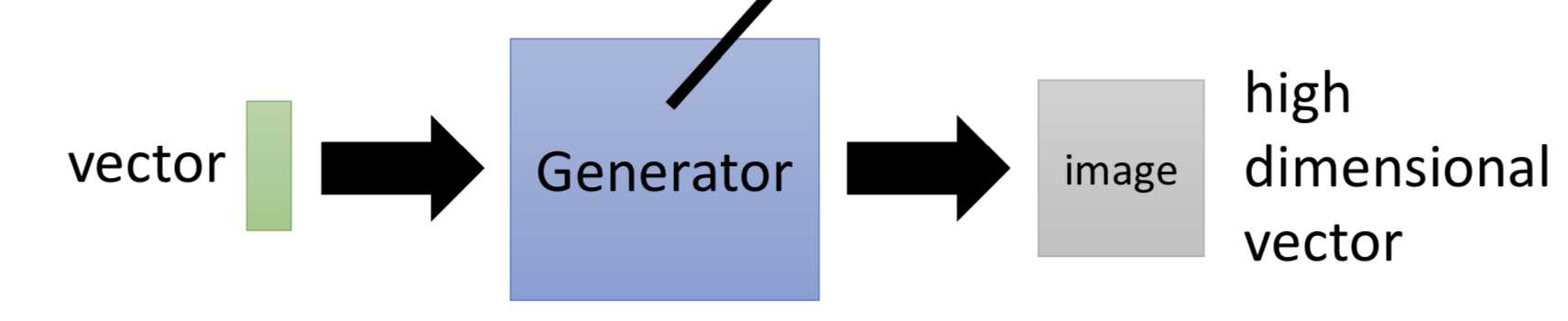
我们想要找到一个高维空间中的分布 P_data(x),在目标类别的区域,probability是高的,在那个区域之外,probability是低的。但这个P_data(x)分布的具体形式是不知道的
没有gan怎么做生成?
maximum likelihood estimation!
1.从P_data(x)中sample一些数据作为训练数据
2.我们有一个含有未知参数theta的分布P_G(x; theta),想做的事情就是找出能够让P_G和P_data最接近的参数theta。比如我们有一个混合高斯分布GMM作为P_G(x; theta),theta就是Gaussians的means和variances
3.由训练数据{x1, x2, ..., xm}计算P_G(xi; theta)
4.likelihood就定义为所有可能的i,P_G(xi; theta)的连乘
5.就用gradient ascent 让这个likelihood最大
maximum likelihood estimation 等价于 minimize KL Divergence
原因在于,可以对概率取对数
然后可以把连乘号拿出来,变成求和:
这个式子就是对期望的估计
然后计算这个期望,就是对x求积分
然后加一个和P_G完全无关的项,也就是不含theta的项
而这样的话,就得到KL散度了
====================================
那问题就来了,怎么才能定义一个general的P_G呢,因为如果很复杂、不知道明确的形式的话,怎么计算P_G(xi; theta)?
定一个generator作为生成P_G的方式,从一个很简单的distribution,project成一个复杂的distribution
那么我们的目标就比较清楚了,就是要找一个generator,让这个P_G和P_data越接近越好,也就是让这两个分布之间的某种divergence。
但是没法直接做,因为P_G和P_data的定义式我们都是不知道的,就没法计算divergence
虽然不知道P_G和P_data的定义式,但是我们可以从这两个分布中sample data出来
从P_G里面做sample,就是获得了训练数据
P_data里面做sample,就是从normal里面sample数据然后经过generator,得到G(z)
然后怎么计算这两个分布的divergence呢 —> 通过discriminator,先放结论!
也就是说,D* = argmaxV(G, D),(这其实就是去训练一个binary classifier?)
这个结果其实是最小化P_G和P_data的JS divergence,为什么呢?
下面上推导:
=====================
所以最后,训练gan就是在做
举个例子:对每一个可能的G,先找到让V(G,D)最大的D,然后再从这些G-D对里面找到令V(G,D)最小的G,这个例子里就是G3-D红点!
所以要怎么去训练呢?就是要解这个minmax问题
找到一个最好的G 去minimize L(G) = maxV(G, D)
那么问题就是L(G)里面的max函数能够微分吗?可以!
所以
1.给G0
2.找到D0*去maximize V(G0, D)
3.
4.找到D1*去maximize V(G1, D)
5. ...
问题就是,更新G那一步会改变V,从V(Gt, Dt*) 到 V(Gt+1, Dt*),而这个时候L(G)可能已经不再是
V(Gt+1, Dt*),而是V(Gt+1, Dt+1*), Dt*不一定等于Dt+1*,而我们的做法就是假设这两个值是近似的。
所以说!不要update G 太多。而应该尽量要把discriminator训练到底,至少要找到一个local maxima。因为确实要找到最大的V
实作的时候就是用sample近似算期望。
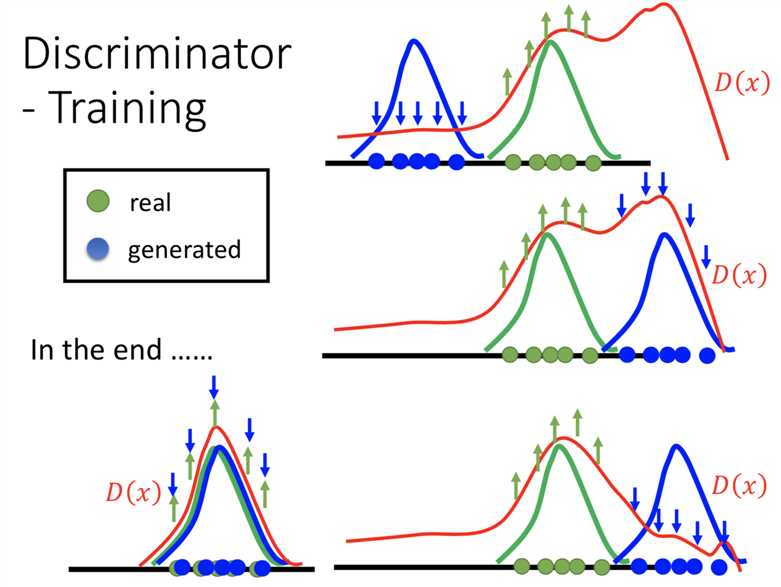
这就是训练一个binary classifier,把从Pdata(x)中sample出来的real data作为positive examples,把生成数据也就是从P_G(x)中sample出来的数据当作negative examples
但是对于训练G来说,还是有问题的。minimize下面这个式子的时候,在开始的时候往往D(x)是很小的,log(1-D(x))在这个区间是很平缓的,更新的就很慢。
所以做一个替换,log(1-D(x))和-log(D(x))在变化趋势上是一致的,但是D(x)很小的时候-log(D(x))的变化就比较快!
别问为什么可以,大佬说这样就是可以!
而且这样连代码都不用改,就把两类的label换掉就好了。。。
但其实像一开始那样子做也是可以的,叫MinimaxGAN,MMGAN
改了之后的叫做Non-saturating GAN
理论完毕
=================
直观的东西。
那到底到最后discriminator会不会烂掉?
另一个trick是不只把上一个generator产生的数据拿来,也把再在此之前的generator产生的generated data 拿来一起训练D, 效果会更好。虽然理论上讲没什么意义。