标签:ima 通过 ODB char sel 百度 运算符 字段 建表
一、谈谈left join 、right join 、inner join的理解
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行
举个栗子说明:
------------------------------------------------------------------ 表A记录如下: 表B记录如下: aID aNum bID bName 1 a20050111 1 2006032401 2 a20050112 2 2006032402 3 a20050113 3 2006032403 4 a20050114 4 2006032404 5 a20050115 8 2006032408 -----------------------------------------------------------------
1、left join: left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.
换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID).
B表记录不足的地方均为NULL.
sql语句如下:
select * from A left join B on A.aID = B.bID
结果如下:
aID aNum bID bName 1 a20050111 1 2006032401 2 a20050112 2 2006032402 3 a20050113 3 2006032403 4 a20050114 4 2006032404 5 a20050115 NULL NULL
2、right join:和left join的结果刚好相反,这次是以右表(B)为基础的,A表不足的地方用NULL填充
sql语句如下:
select * from A right join B on A.aID = B.bID
结果如下:
aID aNum bID bName 1 a20050111 1 2006032401 2 a20050112 2 2006032402 3 a20050113 3 2006032403 4 a20050114 4 2006032404 NULL NULL 8 2006032408
3、inner join:结果很明显,这里只显示出了 A.aID = B.bID的记录.这说明inner join并不以谁为基础,它只显示符合条件的记录.
sql语句如下:
select * from A inner join B on A.aID = B.bID
结果如下:
aID aNum bID bName 1 a20050111 1 2006032401 2 a20050112 2 2006032402 3 a20050113 3 2006032403 4 a20050114 4 2006032404
注: 语法(left join)::FROM table1 LEFT JOIN table2 ON table1.field1 compopr table2.field2
说明:table1, table2参数用于指定要将记录组合的表的名称。
field1, field2参数指定被联接的字段的名称。且这些字段必须有相同的数据类型及包含相同类型的数据,但它们不需要有相同的名称。
compopr参数指定关系比较运算符:"=", "<", ">", "<=", ">=" 或 "<>"。
如果在INNER JOIN操作中要联接包含Memo 数据类型或 OLE Object 数据类型数据的字段,将会发生错误.
二、行转列
下面我们来谈谈项目中经常出现的行转列问题。
什么是行转列呢?
我的理解是:将原本同一列下多行的不同内容作为多个字段,输出对应内容
还是举个栗子吧。
-- 建表语句
DROP TABLE IF EXISTS tb_score; CREATE TABLE tb_score( id INT(11) NOT NULL auto_increment, userid VARCHAR(20) NOT NULL COMMENT ‘用户id‘, subject VARCHAR(20) COMMENT ‘科目‘, score DOUBLE COMMENT ‘成绩‘, PRIMARY KEY(id) )ENGINE = INNODB DEFAULT CHARSET = utf8; -- 插入数据 INSERT INTO tb_score(userid,subject,score) VALUES (‘001‘,‘语文‘,90); INSERT INTO tb_score(userid,subject,score) VALUES (‘001‘,‘数学‘,92); INSERT INTO tb_score(userid,subject,score) VALUES (‘001‘,‘英语‘,80); INSERT INTO tb_score(userid,subject,score) VALUES (‘002‘,‘语文‘,88); INSERT INTO tb_score(userid,subject,score) VALUES (‘002‘,‘数学‘,90); INSERT INTO tb_score(userid,subject,score) VALUES (‘002‘,‘英语‘,75.5); INSERT INTO tb_score(userid,subject,score) VALUES (‘003‘,‘语文‘,70); INSERT INTO tb_score(userid,subject,score) VALUES (‘003‘,‘数学‘,85); INSERT INTO tb_score(userid,subject,score) VALUES (‘003‘,‘英语‘,90); INSERT INTO tb_score(userid,subject,score) VALUES (‘003‘,‘政治‘,82);
-- 查询一下
SELECT * FROM tb_score;
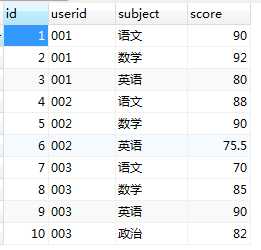
你会发现userid重复了好多行。那有什么方法将他一行显示全呢?
这里就可以用到行转列。来看看我们想要的效果吧
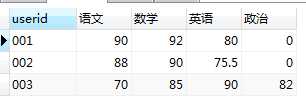
思路:将原来的subject字段的多行内容选出来,作为结果集中的不同列,并根据userid进行分组显示对应的score。
下面来看看这几种实现方法:
1、使用case...when....then 进行行转列
SELECT userid, SUM(CASE `subject` WHEN ‘语文‘ THEN score ELSE 0 END) as ‘语文‘, SUM(CASE `subject` WHEN ‘数学‘ THEN score ELSE 0 END) as ‘数学‘, SUM(CASE `subject` WHEN ‘英语‘ THEN score ELSE 0 END) as ‘英语‘, SUM(CASE `subject` WHEN ‘政治‘ THEN score ELSE 0 END) as ‘政治‘ FROM tb_score GROUP BY userid
看看效果:
对case...when...then...else...end不熟悉的同学自行百度。
2、使用IF() 进行行转列:
SELECT userid, SUM(IF(`subject`=‘语文‘,score,0)) as ‘语文‘, SUM(IF(`subject`=‘数学‘,score,0)) as ‘数学‘, SUM(IF(`subject`=‘英语‘,score,0)) as ‘英语‘, SUM(IF(`subject`=‘政治‘,score,0)) as ‘政治‘ FROM tb_score GROUP BY userid
注:
①SUM() 是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM() 的值就等于对应那一条记录的score的值。
假如userid =‘001‘ and subject=‘语文‘ 的记录有两条,则此时SUM() 的值将会是这两条记录的和,同理,使用Max()的值将会是这两条记录里面值最大的一个。但是正常情况下,一个user对应一个subject只有一个分数,因此可以使用SUM()、MAX()、MIN()、AVG()等聚合函数都可以达到行转列的效果。
②IF(`subject`=‘语文‘,score,0) 作为条件,即对所有subject=‘语文‘的记录的score字段进行SUM()、MAX()、MIN()、AVG()操作,如果score没有值则默认为0。
如果行转列还不够,还要进行汇总呢?
tip:(group by...with rollup)是对分组数据进行统计。
3、利用SUM(IF()) 生成列 + WITH ROLLUP 生成汇总行,并利用 IFNULL将汇总行标题显示为total(复杂,看5)
SELECT IFNULL(userid,‘total‘) AS userid, SUM(IF(`subject`=‘语文‘,score,0)) AS 语文, SUM(IF(`subject`=‘数学‘,score,0)) AS 数学, SUM(IF(`subject`=‘英语‘,score,0)) AS 英语, SUM(IF(`subject`=‘政治‘,score,0)) AS 政治, SUM(IF(`subject`=‘total‘,score,0)) AS total FROM( SELECT userid,IFNULL(`subject`,‘total‘) AS `subject`,SUM(score) AS score FROM tb_score GROUP BY userid,`subject` WITH ROLLUP HAVING userid IS NOT NULL )AS A GROUP BY userid WITH ROLLUP;
运行结果:(3、4、5效果一样)
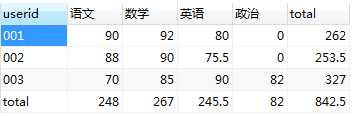
4、合并汇总(复杂,看5)
SELECT userid, SUM(IF(`subject`=‘语文‘,score,0)) AS 语文, SUM(IF(`subject`=‘数学‘,score,0)) AS 数学, SUM(IF(`subject`=‘英语‘,score,0)) AS 英语, SUM(IF(`subject`=‘政治‘,score,0)) AS 政治, SUM(score) AS total FROM tb_score GROUP BY userid UNION SELECT ‘total‘,SUM(IF(`subject`=‘语文‘,score,0)) AS 语文, SUM(IF(`subject`=‘数学‘,score,0)) AS 数学, SUM(IF(`subject`=‘英语‘,score,0)) AS 英语, SUM(IF(`subject`=‘政治‘,score,0)) AS 政治, SUM(score) FROM tb_score
解释下这个SQL:
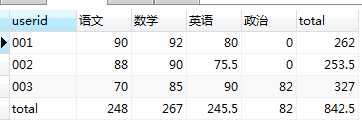
将上下两个结果集合并了。3和4都比较麻烦
5、利用SUM(IF()) 生成列,直接生成结果不再利用子查询
SELECT IFNULL(userid,‘total‘) AS userid, SUM(IF(`subject`=‘语文‘,score,0)) AS 语文, SUM(IF(`subject`=‘数学‘,score,0)) AS 数学, SUM(IF(`subject`=‘英语‘,score,0)) AS 英语, SUM(IF(`subject`=‘政治‘,score,0)) AS 政治, SUM(score) AS total FROM tb_score GROUP BY userid WITH ROLLUP;
WITH ROLLUP:在group分组字段的基础上再进行统计数据。
6、动态,适用于列不确定情况
SET @EE=‘‘; select @EE :=CONCAT(@EE,‘sum(if(subject= \‘‘,subject,‘\‘,score,0)) as ‘,subject, ‘,‘) AS aa FROM (SELECT DISTINCT subject FROM tb_score) A ; SET @QQ = CONCAT(‘select ifnull(userid,\‘total\‘)as userid,‘,@EE,‘ sum(score) as totalfrom tb_score group by userid WITH ROLLUP‘); -- SELECT @QQ; PREPARE stmt FROM @QQ; EXECUTE stmt; DEALLOCATE PREPARE stmt;
运行结果:

7、合并字段显示:利用group_concat()
SELECT userid,GROUP_CONCAT(`subject`,":",score)AS 成绩 FROM tb_score GROUP BY userid
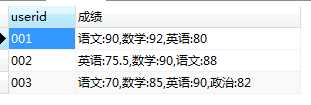
三、列转行
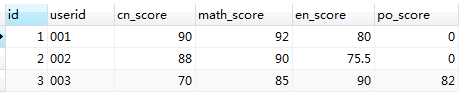
-- 建表语句 CREATE TABLE tb_score1( id INT(11) NOT NULL auto_increment, userid VARCHAR(20) NOT NULL COMMENT ‘用户id‘, cn_score DOUBLE COMMENT ‘语文成绩‘, math_score DOUBLE COMMENT ‘数学成绩‘, en_score DOUBLE COMMENT ‘英语成绩‘, po_score DOUBLE COMMENT ‘政治成绩‘, PRIMARY KEY(id) )ENGINE = INNODB DEFAULT CHARSET = utf8; -- 插入数据 INSERT INTO tb_score1(userid,cn_score,math_score,en_score,po_score) VALUES (‘001‘,90,92,80,0); INSERT INTO tb_score1(userid,cn_score,math_score,en_score,po_score) VALUES (‘002‘,88,90,75.5,0); INSERT INTO tb_score1(userid,cn_score,math_score,en_score,po_score) VALUES (‘003‘,70,85,90,82); -- 查询表中的内容 SELECT * FROM tb_score1;
运行结果:(也就是转换前的效果)
列转行后:
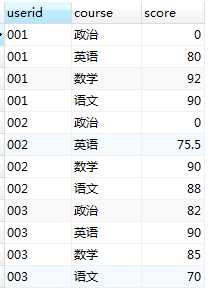
本质是将userid的每个科目分数分散成一条记录显示出来。
直接上SQL:
SELECT userid,‘语文‘ AS course,cn_score AS score FROM tb_score1 UNION ALL SELECT userid,‘数学‘ AS course,math_score AS score FROM tb_score1 UNION ALL SELECT userid,‘英语‘ AS course,en_score AS score FROM tb_score1 UNION ALL SELECT userid,‘政治‘ AS course,po_score AS score FROM tb_score1 ORDER BY userid
这里将每个userid对应的多个科目的成绩查出来,通过UNION ALL将结果集加起来,达到上图的效果。
附:UNION与UNION ALL的区别:
1.对重复结果的处理:UNION会去掉重复记录,UNION ALL不会;
2.对排序的处理:UNION会排序,UNION ALL只是简单地将两个结果集合并;
3.效率方面的区别:因为UNION 会做去重和排序处理,因此效率比UNION ALL慢很多;
标签:ima 通过 ODB char sel 百度 运算符 字段 建表
原文地址:https://www.cnblogs.com/chen8023miss/p/11423076.html