标签:字符 支持 http enter cape const details base64编码 ons
详细参考本篇博文https://blog.csdn.net/qq_25243451/article/details/88658864
后台传来经过 base64 编码的字符串(原始字符串含有中文), 需要在前端进行解码, 但 js 中的 atob 解码方法不支持 unicode 字符集( btoa 也是), 换言之, 中文被解码出来是会乱码的。
网上流传的多是使用encodeURIComponent 和 decodeURIComponent,原理是对中文进行百分号编码,转换为%xxx这种样式,但是这样使用之后会使编码变长,如下
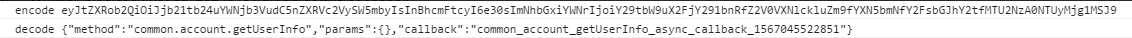
图1(期望的编码值)

图2(使用百分号编码之后)
同样的元字符,使用encodeURIComponent之后字符更长,原因是没有对百分号编码的字符的进行编码,导致编码后的字符串变长
因此在这里调用escape和unescape方法:
const Base64 = { encode: (str) => { return window.btoa(unescape(encodeURIComponent(str))) }, decode: (str) => { return decodeURIComponent(escape(window.atob(str))) } }
具体的详解可以参考开头提到的那篇博文
标签:字符 支持 http enter cape const details base64编码 ons
原文地址:https://www.cnblogs.com/sue7/p/11428429.html