标签:object 重要 先进先出 alt 数组实现 pop 扩容 join 顺序存储
集合在Java中的地位想必大家都知道,不用多BB了。无论是在我们现在的学习中还是在今后的工作中,集合这样一个大家族都无处不在,无处不用。在前面讲到的数组也是一个小的容器,但是数组不是面向对象对象的,它存在明显的缺陷,而集合恰好弥补了数组带来的缺陷。集合比数组更加灵活、更加实用。而且不同的集合框架可用于不同的场景。
我们简单来比较一下数组和集合区别:
为了清晰的认识Java集合大家族,下面是整个Java集合的框架图:
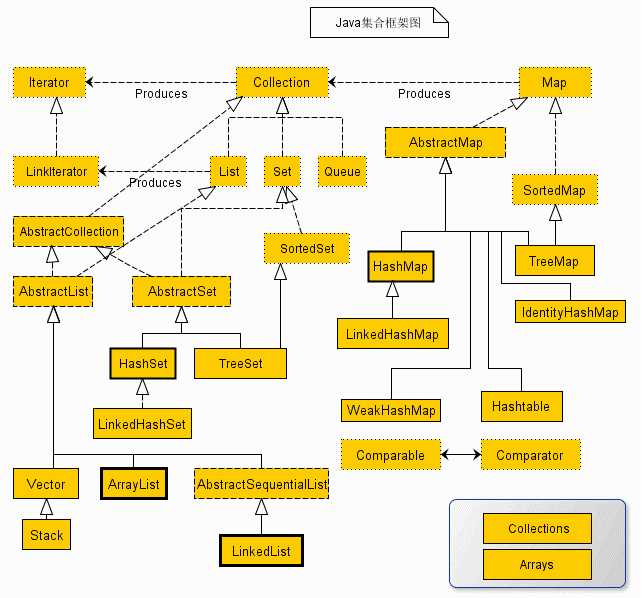
通过上面的图片可以看到集合大家族的成员以及他们之间的关系。发现这也太多了吧,不过不要太慌张。我们现在只需要抓住它们的主干即可,即Collection、Map和Iterator,额外的还有两个对集合操作的工具类Collections和Arrays。其中虚框表示的是接口或抽象类,实框是类,虚箭头是实现,实箭头是继承。然后把它们捋一捋给分个类就应该清楚了。
上面的Java集合框架图看起来比较的杂乱,所以我们对它们进行了分类处理,这样更加直观。
Collection接口:最基本的集合接口(单列数据)
├——-List接口:所有元素按照进入的先后顺序有序存储,可重复集合
│—————-├ ArrayList:接口实现类,用数组实现,随机访问,增删慢,查询快,没有同步,线程不安全
│—————-├ LinkedList:接口实现类,用双向链表实现, 插入删除快,查询慢, 没有同步,线程不安全
│—————-└ Vector:接口实现类,用数组实现,它和ArrayList几乎一样,但是它是同步, 线程安全的(Vector几乎已经不用了)
└———————-└ Stack:继承自Vector类,Stack具有后进先出的特点
└——-Set接口:不允许包含重复的值(可以有null,但是只有一个),无序,不可重复集合
├—————-└HashSet:使用hash表(数组)存储元素,无序,其底层是包装了一个HashMap去实现的,所以查询插入速度较快
│————————└ LinkedHashSet:继承HashSet类,它新增了一个重要特性,就是元素按照插入的顺序存储
├ —————-TreeSet:底层基于TreeMap实现的,它支持2种排序方式:自然排序(Comparable)和定制排序(Comparator)
└ ——-Queue接口:队列,它的特点是先进先出
Map接口:键值对的集合接口,不允许含有相同的key,有则输出一个key-value组合(双列数据)
├———Hashtable:接口实现类,用hash表实现,不可重复key,key不能为null,同步,效率稍低,线程安全
├———HashMap:接口实现类 ,用hash表实现,不可重复key,key可以为null,没有同步,效率稍高 ,线程不安全
│—————–├ LinkedHashMap:双向链表和hash表实现,按照key的插入顺序存放
│——— WeakHashMap:和HashMap一样,但它的键是“弱键”,垃圾收集器会自动的清除没有在其他任何地方被引用的键值对
├ ——–TreeMap:用红黑树算法实现,它默认按照所有的key进行排序
└———IdentifyHashMap:它是一个特殊的Map实现,它的内部判断key是否相等用的是 ==,而HashMap则更加复杂
简单完成分类之后我们就从集合的特点和区别来进行一 一讲解。
Collection是最基本的集合接口,它是单列数据集合。在JDK中不提供Collection接口的任何直接实现,它只提供了更具体的子接口(即继承自Collection接口),例如List列表,Set集合,Queue队列,然后再由具体的类来实现这些子接口。通过具体类实现接口之后它们的特征就得以凸显出来,有些集合中的元素是有序的,而其他的集合中的元素则是无序的;有些集合允许重复的元素,而其他的集合则不允许重复的元素;有些集合允许排序,而其他的集合则不允许排序。
既然Collection接口是集合的层次结构的根接口,那么必定有常用的方法,我们来看一下:
我们从上面Collection结构中可以看到其内部有一个iterator()方法,这个方法不是Collection中所特有的,而是重写了父类Iterable中的。因为Collection接口继承了java.lang.Iterable接口,而该接口中有一个iterator()方法。也就是说所有实现了Collection接口的集合类中都有iterator()方法,它用来返回实现了Iterator接口的迭代器对象。
Iterator接口的内部结构比较简单,其内部只定义的四个方法,它们分别是:
迭代器的简单举例:
public static void main(String[] args) { //hasNext()、next()测试 Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(‘A‘); coll.add(true); coll.add(new String("Collection...")); //创建迭代器对象 Iterator iterator = coll.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } System.out.println("----------------------"); //remove()测试。如果还未调用next()或在上次调用next()方法之后已经调用了remove()方法, //那么在再次用remove()方法会报错java.lang.IllegalStateException Iterator iterator1 = coll.iterator(); while (iterator1.hasNext()) { //iterator1.remove();不能在next()前先调用 Object next = iterator1.next(); if (next.equals(456)) { iterator1.remove(); //iterator1.remove();不能在next()后再次调 } } iterator1 = coll.iterator(); while (iterator1.hasNext()) { System.out.println(iterator1.next()); } } //运行结果: //123 //456 //A //true //Collection... //---------------------- //123 //A //true //Collection...
简易分析一下:当返回了Iterator对象之后可以理解为有一个指针,它指在第一个对象的上面(即123的上面,此时指针为空),当我们调用iterator.hasNext()的时候,判断是否还有下一个元素,如果有则返回true。然后调用iterator.next()使指针往下移并且返回下移以后集合位置上的元素,这样以此类推就输出了以上结果。
List接口直接继承了Collection接口,它对Collection进行了简单的扩充,从而让集合凸显出它们各自的特征。在List中所有元素的存储都是有序的,而且是可重复存储的。用户可以根据元素存储位置的索引来操作元素。实现了List接口的集合主要有以下几个:ArrayList、LinkedList、Vector和Stack。
注意:List集合它有一个特有的迭代器——ListIterator。Iterator的子接口ListIterator是专门给List集合提供的迭代元素的接口,它的内部对Iterator功能进行一些扩充。例如增加的方法有hasPrevious()、nextIndex()、previousIndex()等等。
既然List接口直接继承了Collection接口,而且List是有序存储结构,那么List除了从Collection中继承的方法之外,必定会自己添加一些根据索引来操作集合元素的方法,我们来看一下:
ArrayList应该是我们最常见的集合,同时也是List中最重要的一个。ArrayList的特点是:随机访问、查询快,增删慢,轻量级,线程不安全。它的底层是用Object数组实现的,我们可以把ArrayList看做是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其容量是动态增加的(初始化容量是10,增量是原来的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1);)。
LinkedList底层是通过双向链表实现的,所以它不能随机访问,而且需要查找元素必须要从开头或结尾(从靠近指定索引的一端)开始一个一个的找。使用双向链表则让增加、删除元素比较的方便,但查询变得困难。所以LinkedList的特点是:查询慢,增删快,线程不安全。
由于LinkedList是双向链表实现的,所以它除了有List中的基本操作方法外还额外提供了一些方法在LinkedList的首部或尾部进行操作的方法(其实是继承Deque中的),如addXXX()、getXXX()、removeXXX()等等。同时,LinkedList还实现了Queue接口的子接口Deque,所以他还提供了offer(), peek(), poll()、pop()、push()等方法。我们简单来看一下:
Vector和ArrayList几乎一样,它们都是通过Object数组来实现的。但是Vector是线程安全的,和ArrayList相比,Vector中很多方法是用synchronized关键字处理过来保证证数据安全,这就必然会影响其效率,所以你的程序如果不涉及到线程安全问题,那么推荐使用ArrayList集合。其实无论如何大家都会选择ArrayList的,因为Vector已经很少用了,几乎面临淘汰。
另外二者还有一个区别就是Vector和ArrayList的扩容策略不一样,Vector的扩容增量是原来容量的2倍,而ArrayList是原来的1.5倍。
Stack的名称是堆栈。它是继承自Vector这个类,这就意味着,Stack也是通过数组来实现的。Stack的特性是:先进后出(FILO, First In Last Out)。此外Stack中还提供5个额外的方法使得Vector得以被当作堆栈使用。我们来看一下这五个方法:
Set和List一样都是继承自Collection接口,但是Set和List的特点完全不一样。Set集合中的元素是无顺序的,且没有重复的元素。如果你试图将多个相同的对象添加到Set中,那么不好意思,它会立马阻止。Set中会用equals()和hashCode()方法来判断两个对象是否相同,只要该方法的结果是true,Set就不会再次接收这个对象了。实现了Set接口主要有一下几个:HashSet、LinkedHashSet、TreeSet、EnumSet。Set中没有增加任何新的方法,用的都是继承自中Collection中的。
HashSet是按照哈希算法(hashCode)来存储集合中的对象,所以它是无序的,同时也不能保证元素的排列顺序。其底层是包装了一个HashMap去实现的,所以其查询效率非常高。而且在增加和删除的时候由于运用hashCode的值来比较确定添加和删除元素的位置,所以不存在元素的偏移,效率也非常高。因此HashSet的查询、增加和删除元素的效率都是非常高的。但是HashSet增删的高效率是通过花费大量的空间换来的:因为空间越大,取余数相同的情况就越小。HashSet这种算法会建立许多无用的空间。使用HashSet接口时要注意,如果发生冲突,就会出现遍历整个数组的情况,这样就使得效率非常的低。HashSet使用简单举例:
public class HashSetTest { public static void main(String[] args) { //创建HashSet的实例 HashSet<String> hashSet = new HashSet<>(); //添加了两个AA元素 hashSet.add("AA"); hashSet.add("AA"); hashSet.add("BB"); //添加了两个CC元素 hashSet.add("CC"); hashSet.add("CC"); hashSet.add("DD"); hashSet.add("EE"); hashSet.add("FF"); hashSet.add("GG"); //遍历打印结果 for (String s : hashSet) { System.out.println(s+",hash值是:"+s.hashCode()); } } } //运行结果: //AA,hash值是:2080 //BB,hash值是:2112 //CC,hash值是:2144 //DD,hash值是:2176 //EE,hash值是:2208 //FF,hash值是:2240 //GG,hash值是:2272
LinkedHashSet继承自HashSet类,它不仅实现了哈希算法(hashCode),还实现了链表的数据结构,提供了插入和删除的功能。他有HashSet全部特性,但它新增了一个重要特性,就是元素按照插入的顺序存储。所以当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。正是因为多加了这样一种数据结构,所以它的效率较低,不建议使用,如果要求一个集合急要保证元素不重复,也需要记录元素的先后添加顺序,才选择使用LinkedHashSet。LinkedHashSet使用简单举例:
public class LinkedHashSetTest { public static void main(String[] args) { //创建LinkedHashSet实例 LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>(); //无序添加元素 linkedHashSet.add("DD"); linkedHashSet.add("BB"); linkedHashSet.add("AA"); linkedHashSet.add("GG"); linkedHashSet.add("EE"); linkedHashSet.add("FF"); linkedHashSet.add("CC"); //遍历打印值 for (String s : linkedHashSet) { System.out.println(s+",hash值:"+s.hashCode()); } //删除GG元素 boolean gg = linkedHashSet.remove("GG"); System.out.println(gg); } } //运行结果: //DD,hash值:2176 //BB,hash值:2112 //AA,hash值:2080 //GG,hash值:2272 //EE,hash值:2208 //FF,hash值:2240 //CC,hash值:2144 //true
TreeSet的底层是基于TreeMap中实现的。它不仅能保证元素的唯一性,还能对元素按照某种规则进行排序。它继承了AbstractSet抽象类,实现了NavigableSet <E>,Cloneable,可序列化接口。而NavigableSet <E>又继承了SortedSet接口,此接口主要用于排序操作,即实现此接口的子类都属于排序的子类,有可排序的功能。TreeSet中的元素支持2种排序方式:自然排序或者定制排序,使用方式具体取决于我们使用的构造方法(默认使用自然排序)。TreeSet使用简单举例:
public class TreeSetTest { public static void main(String[] args) { //创建TreeSet实例、使用Comparator定制排序 TreeSet<Integer> treeSet = new TreeSet<>(new Comparator<Integer>() { //排序方式为:降序 @Override public int compare(Integer o1, Integer o2) { if (o1>o2){ return -1; }else if(o1<o2){ return 1; }else { return 0; } } }); treeSet.add(2); treeSet.add(2); treeSet.add(4); treeSet.add(4); treeSet.add(1); treeSet.add(1); treeSet.add(3); treeSet.add(3); for (Integer integer : treeSet) { System.out.println(integer); } } } //输出结果: //4 //3 //2 //1
EnumSet是专门为枚举类而设计的有序集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,在创建EnumSet时必须显式或隐式指定它对应的枚举类。EnumSet使用简单举例:
//创建枚举类 public enum Season { SPRING,SUMMER,AUTUMN,WINNER; } class Test{ public static void main(String[] args) { //EnumSet的简单使用 EnumSet<Season> seasons = EnumSet.allOf(Season.class); //遍历 for (Season season : seasons) { System.out.println(season); } } } //输出结果: //SPRING //SUMMER //AUTUMN //WINNER
Queue接口与List、Set是同一级别的,都继承了Collection接口。Queue表示的是队列,它的特点是:先进先出(FIFO,First-in-First-Out) 。队列主要分为两大类:一类是BlockingDeque阻塞队列(Queue的子接口),它的主要实现类包括ArrayBlockQueue、PriorityBlockingQueue. LinkedBlockingQueue。另一类是Deque双端队列(也是Queue的子接口),支持在头部和尾部两端插入和移除元素,主要实现类包括:ArrayDeque、LinkedList。
Queue接口中包含的方法有:
对于BlockingDeque阻塞队列的详解可以参考这篇博客:BlockingQueue(阻塞队列)详解 ,写的非常不错。
Map接口与Collection接口是完全不同的。Map中保存的是具有“映射关系”的数据,即是由一系列键值对组成的集合,提供了key到value的映射,也就是说一个key对应一个value,其中key和value都可以是任何引用数据类型。但是Map中不能存在相同的key值,对于相同key值的Map对象会通过equals()方法来判断key值是否相等,只要该方法的结果是true,Map就不会再次接收这个对象了,当然value值可以相同。实现了Map接口的类主要的有以下几个:HashMap、Hashtable、LinkedHashMap、WeakHashMap、TreeMap、IdentifyHashMap、EnumMap。其中Map集合还和Set集合有着非常紧密的联系,因为很多Set集合中底层就是用Map来实现的。
我们来看一下Map键值对根接口中的方法:
遍历Map中的对象:Java中四种遍历Map对象的方法
Hashtable是一个古老的Map实现类,在JDK1.0就提供了,它继承自Dictionary类,底层基于hash表结构+数组+链表实现实现,内部所有方法都是同步的,即线程很安全,但是效率低。注意在Hashtable中key和value均不可为null。
HashMap是Map集合中使用最多的,它是Hashtable的一个轻量级版本,它是继承了Abstractmap类,底层也是基于hash表结构+链表(红黑树,链表长度大于8会将链表转化成红黑树)+数组实现的,内部所有方法是不同步的,即线程不安全,但是效率高。在HashtMap中key和value均均可为null。
LinkedHashMap基于双向链表和数组实现,内部结构和HashMap类似,就是多加了一个双向链表结构。根据key的插入顺序进行存储。(注意和TreeMap对所有的key-value进行排序进行区分)
WeakHashMap与HashMap的用法基本相似。区别在于,HashMap的key保留了对实际对象的"强引用",这意味着只要该HashMap对象不被销毁,该HashMap所引用的对象就不会被垃圾回收。但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,当垃圾回收了该key所对应的实际对象之后,WeakHashMap也可能自动删除这些key所对应的key-value对。
TreeMap底层是用红黑树算法实现,它实现SortMap接口,所以其内部元素默认按照所有的key进行排序。当然也支持2种排序方式:自然排序或者定制排序。其中TreeMap中的key不可null,而它非线程安全的。使用可以参考上面的TreeSet示例,使用方式差不多。
IdentityHashMap是一种可重复key的集合类。它和HashMap类似,所以我们一般都是拿IdentityHashMap和HashMap来进行比较,因为它们两者判断重复key的方式不一样。IdentifyHashMap中判断重复key相等的条件是:(k1==k2),也就是说它只比较普通值是否相等,不比较对象中的内容。而HashMap中类判断重复key相等的条件是: (k1==null?k2==null:k1.equals(k2))==true),它不仅比较普通值,而且比对象中的内容是否相等。简单举例:
public class MapTest { public static void main(String[] args) { //创建HashMap实例,添加Integer实例为key HashMap hashMap=new HashMap(); hashMap.put(1,"hello"); hashMap.put(1,"hello"); hashMap.put(new Integer(2),"hello"); hashMap.put(new Integer(2),"hello"); hashMap.put(new Integer(2),"hello"); System.out.println("HashMap:"+hashMap.toString()); //创建IdentityHashMap实例,添加Integer实例为key IdentityHashMap<Object, Object> identityHashMap = new IdentityHashMap<>(); identityHashMap.put(3,"world"); identityHashMap.put(3,"world"); identityHashMap.put(new Integer(4),"world"); identityHashMap.put(new Integer(5),"world"); identityHashMap.put(new Integer(4),"world"); System.out.println("IdentityHashMap:"+identityHashMap.toString()); } } //运行结果: //HashMap:{1=hello, 2=hello} //IdentityHashMap:{4=world, 4=world, 3=world, 5=world}
EnumMap这个类是专门为枚举类而设计的有键值对的集合类。集合中的所有键(key)都必须是单个同一个类型的枚举值,创建EnumMap时必须显式或隐式指定它对应的枚举类。当EnumMap创建后,其内部是以数组形式保存,所以这种实现形式非常紧凑高效。EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)来维护来维护key-value对的次序。可以通过keySet()、entrySet()、values()等方法来遍历EnumMap即可看到这种顺序。EnumMap不允许使用null作为key值,但允许使用null作为value。如果试图使用null作为key将抛出NullPointerException异常。如果仅仅只是查询是否包含值为null的key、或者仅仅只是使用删除值为null的key,都不会抛出异常。EnumMap的代码示例如下:
//创建枚举类 public enum Season { SPRING,SUMMER,AUTUMN,WINNER; } class Test{ public static void main(String[] args) { //EnumMap的简单使用 EnumMap<Season,String> map=new EnumMap<Season, String>(Season.class); map.put(Season.SPRING,"春暖花开"); map.put(Season.SUMMER,"夏日炎炎"); map.put(Season.AUTUMN,"秋高气爽"); map.put(Season.WINNER,"冬暖夏凉"); //遍历map有很多种方式,这里是map遍历的一种方式,这种方式是最快的 for (EnumMap.Entry<Season,String> entry:map.entrySet()){ System.out.println(entry.getKey()+","+entry.getValue()); } } } //输出结果: //SPRING,春暖花开 //SUMMER,夏日炎炎 //AUTUMN,秋高气爽 //WINNER,冬暖夏凉
Collections是集合的一个工具类或者帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
以上只是一些常见的方法,如果需要了解更多的方法可以自行去查看Collections的API。
Relevant Link:
标签:object 重要 先进先出 alt 数组实现 pop 扩容 join 顺序存储
原文地址:https://www.cnblogs.com/tang-hao-/p/11347133.html