标签:tin 添加 medium section art 自增 utf8 win bytes
查看文件编码 show variables like "%char%"
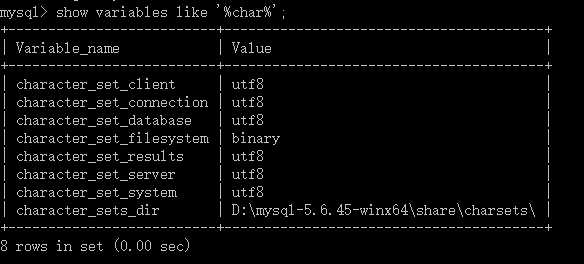
如果文件编码没有问题创建文件夹(库)时,例如: create database db1(文件名);
如果文件编码有问题创建文件夹(库)时, 例如 create database db1 charset utf8; (设置编码)
查看所有的库, show databases;
中间过程修改编码, alter databases db1 charset utf8(编码);
删除文件夹(删库), drop database db1;
如果有多个文件,先切到该文件所在文件夹下, use db1;
创建文件, create table t1(id int,name char(10)); ()中的数字是字符数,不是字节
查看当前库中有多少表, show tables;
修改文件,alter table t1 modify name char(3);
查看表结构: desc 表名 (describe 表名) 或者 show create table 表名;
删除表名, drop table 表名;
修改表名, alter table 表名 rename 新表名;
查看表中所有内容, select * from 表名; (select id,name from 表名)
向表中添加内容, insert into 表名 values(1,"太白") 与创建时设置一一对应
修改表中内容,update 表名 set name= "Barry";没设置条件,所有name都改变了
update 表名 set name="Barry" where id=1; 只修改id为1的名字
update 表名 set name="Barry" ,id = 2 where id=1; 修改id为1的id和名字
清空表中内容,delete from 表名; truncate from 表名,数据量大时,后者快
删除某一个内容, delete from 表名 where id=1,其他id不变
查看表的存储引擎, show engines;

memory
创建myisam类型存储引擎

创建memory类型存储引擎

select money from user where name=‘太白‘;
update user set money=800 where name="太白";
select money from user where name=‘alex‘;
update user set money=300 where name="alex";
创建表的完整结构:
create table 表名(字段名1 类型[(宽度) 约束条件],
字段名2[(宽度) 约束条件],
字段名3[(宽度) 约束条件]);
对于整型来说,数据类型后面的宽度并不是存储长度限制,而是显示限制,例如int,int无符号类型,那么默认的显示宽度就是int(10),有符号的就是int(11)(符号-占了一位),因为多了一个符号,所以我们没有必要指定整数类型的数据,没必要指定宽度,因为默认的就能够将你存的原始数据完全显示
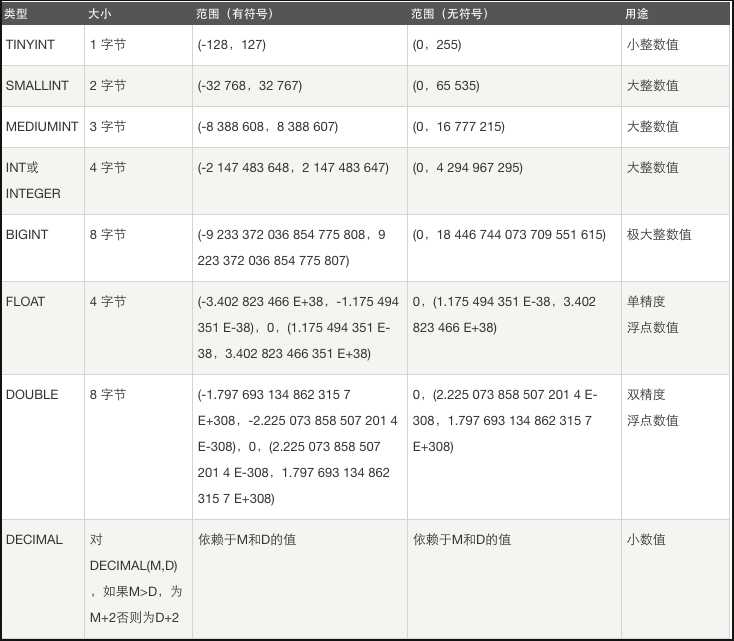
整数类型 (主要存储用于计算的数字,如年龄,等级,id,钱数) (默认有符号)
如上图,对于整数类型,都是有范围的,有符号时是多了一个负号,范围有正负
整数类型范围验证
1.tinyint默认为有符号
创建一个day41的数据库 create database day41;
切换到此数据库文件下 use day41;
创建一个小整形的文件t1 create table t1(money tinyint);
查看表结构 desc t1; (show create table t1)
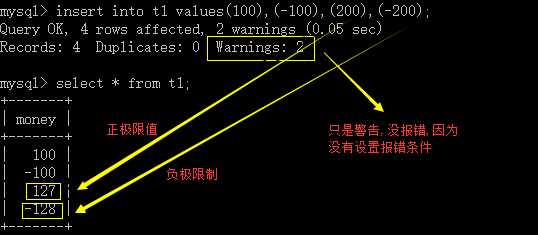
向表中传入数据 insert into t1 values(100),(-100),(200),(-200);
查看我们存入的数据 select * from t1;
结果如下图,我们发现,我们传的值超过范围时,存入的数据就成了极限值(-128,127)
2.设置无符号的 tinyint
接着上边写,创建无符号小整数类型
创建一个小整形的文件t2 create table t2(money tinyint unsigned);
查看表结构 desc t2; (show create table t2)
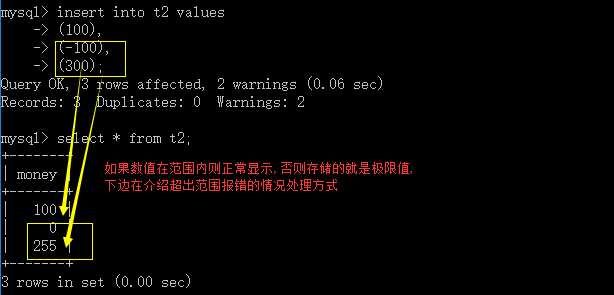
向表中传入数据 insert into t2 values
-> (100),
-> (-100),
-> (300);
查看我们存入的数据 select * from t2;
结果如下图,我们发现,我们传的值超过范围时,存入的数据就成了极限值(0,255)
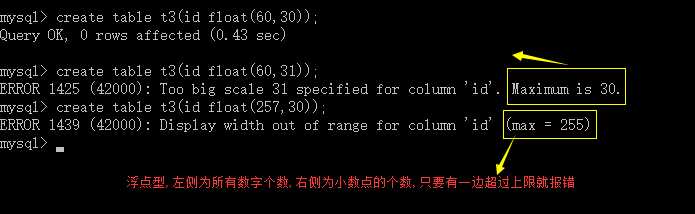
float 单精度浮点数(非准确小数值),随着小数的增多,精度变得不准确 (255,30)
double 双精度浮点数(非准确小数值),随着小数的增多,精度比float要高,但也不准确(255,30)
decimal 精确的小数值,随着小数的增多,精度始终准确 (65,30)
decimal能够存储精确值的原因在于其内部按照字符串存储
依次创建3个文件
create table t3(id float(60,30)); 范围(255,30) 255是30个小数加上整数的和
create table t4(id double(60,30)); 范围(255,30) 255是30个小数加上整数的和
create table t5(id decimal(60,30)); 范围(65,30) 65是30个小数加上整数的和
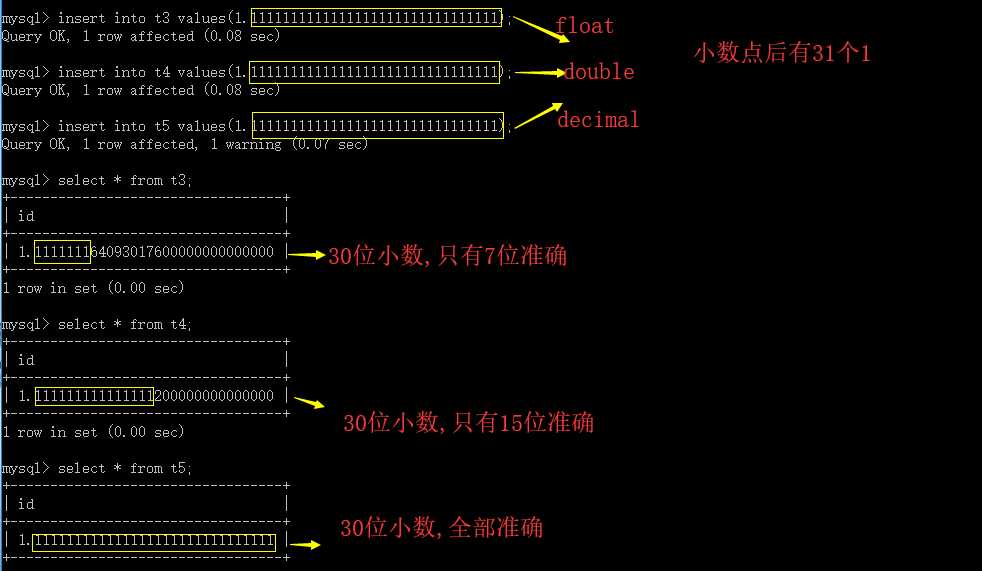
如上所示,精确度decimal > double > float
3.位类型
BIT(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1位。
注意:对于位字段需要使用函数读取
bin()显示为二进制
hex()显示为十六进制
mysql> create table t9(id bit);
mysql> desc t9; #bit默认宽度为1
+-------+--------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+-------+
| id | bit(1) | YES | | NULL | |
+-------+--------+------+-----+---------+-------+
mysql> insert into t9 values(8);
mysql> select * from t9; #直接查看是无法显示二进制位的
+------+
| id |
+------+
| |
+------+
mysql> select bin(id),hex(id) from t9; #需要转换才能看到
+---------+---------+
| bin(id) | hex(id) |
+---------+---------+
| 1 | 1 |
+---------+---------+
mysql> alter table t9 modify id bit(5);
mysql> insert into t9 values(8);
mysql> select bin(id),hex(id) from t9;
+---------+---------+
| bin(id) | hex(id) |
+---------+---------+
| 1 | 1 |
| 1000 | 8 |
+---------+---------+
1.日期类型分类
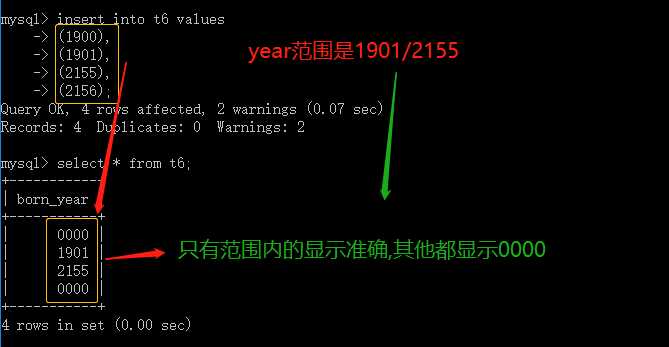
类型: YEAR:范围 (1901/2155)
? DATE:范围 (1000-01-01/9999-12-31)
? TIME: 范围 (‘‘-838:59:59‘‘/‘‘838:59:59‘‘)
? DARATIME: 范围 (1000-01-01 00:00:00/9999-12-31 23:59:59)
? TIMESTAMP: 范围 (1970-01-01 00:00:00/2037年某时)
作用:存储用户注册时间,文章发布时间,员工入职时间,出生日期,过期时间等
2.日期类型测试
create table t6(born_year year);
insert into t6 values(1900),(1901),(2155),(2156);
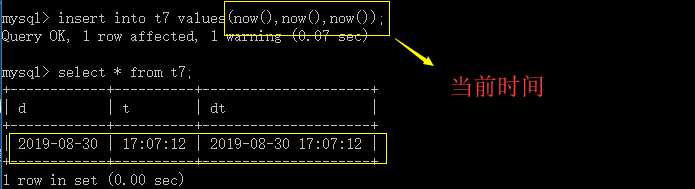
create table t7(d date,t time,dt datetime);
insert into t6 values(now(),now(),now()); #当前时间
select * from t7;
3.手动插入两位数时间
1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
2. 插入年份时,尽量使用4位值
3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
>=70,以19开头,比如71,结果1971
mysql> create table t12(y year);
mysql> insert into t12 values
-> (50),
-> (71);
mysql> select * from t12;
+------+
| y |
+------+
| 2050 |
| 1971 |
+------+
4.datetime 和 timestamp的区别
datetime 的默认值为null,timestamp的字段默认不为空(not null),默认当前时间
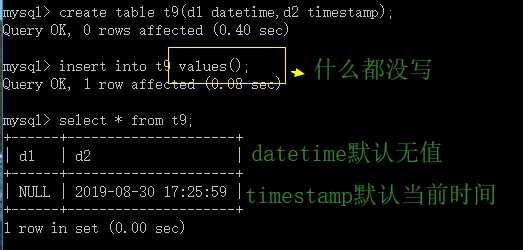
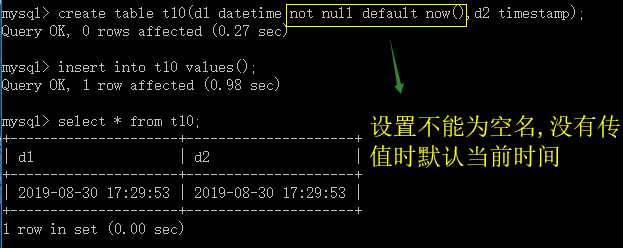
模式设置和修改(以解决上述问题为例):(数值超出范围只警告不报错问题)
方式一:先执行select @@sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set sql_mode = ‘修改后的值‘或者set session sql_mode=‘修改后的值‘;,例如:set session sql_mode=‘STRICT_TRANS_TABLES‘;改为严格模式 #session可以不用写
此方法只在当前会话中生效,关闭当前会话就不生效了。
方式二:先执行select @@global.sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set global sql_mode = ‘修改后的值‘。
此方法在当前服务中生效,重新MySQL服务后失效
方法三:在mysql的安装目录下,或my.cnf文件(windows系统是my.ini文件),新增 sql_mode = STRICT_TRANS_TABLES
添加my.cnf如下:
[mysqld] sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER
length(字段) : 查看该字段数据的字节长度
char_length(字段): 查看该字段数据的字符长度
如果我们想看它存储的真实长度,需要设置mysql的模式,如下
set sql_mode =‘PAD_CHAR_TO_FULL_LENGTH‘;
char 和 varchar
以char(5) 和 varchar(5)比较,加入三个人名,sb,dsb,sbdsb
char:
优点:简单粗暴,不管你是多长,我都按照规定的长度来存储,5个5个的存储,取的时候也是5个5个取,速度快
缺点:数据不满时浪费空间,将来存储的数据的长度可能会参参差不齐
varchar:
根据数据的长度存储数据,更为精简和节省空间(数据不饱和时),存储时会在每个数据前面加上一个头,1bytes+sb+1bytes+dsb+1bytes+sbdsb,导致存取比较麻烦
优点:数据不饱和时节省了一些空间,春出的数据范围更大
缺点:存取速度慢
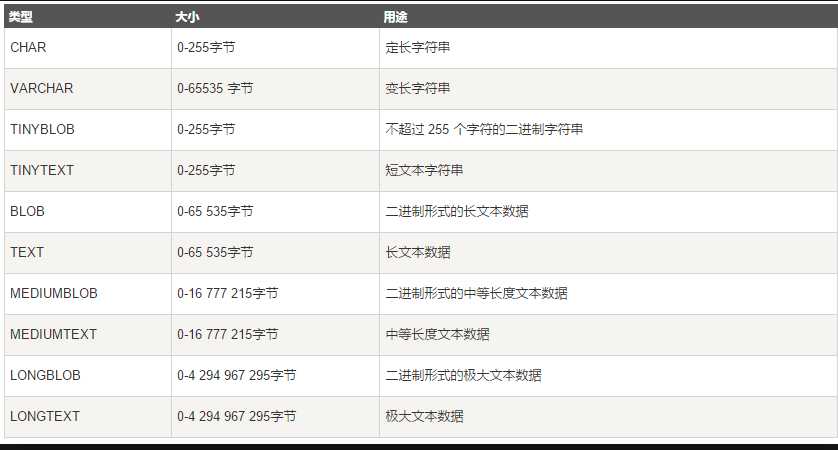
枚举类型(enum)
create table shirts(name varchar(20),size enum(‘x-small‘, ‘small‘, ‘medium‘, ‘large‘, ‘x-large‘));
insert into shirts values("alex","aaa"); #报错,aaa不在enum中
insert into shirts values(‘alex‘,"small");
select * from shirts;
集合类型(set) 去重
create table myset(col set(‘a‘,‘b‘,‘c‘,‘d‘));
insert into myset values(‘a,d‘),(‘d,a‘),(‘a,d,d‘),(‘b,c,c,d‘);
select * from myset;
mysql> select * from myset;
+-------+
| col |
+-------+
| a,d |
| a,d |
| a,d |
| b,c,d |
+-------+
去重了,两个时一定都在引号里,不能是(‘a‘,‘b‘)
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table t1(id int not null defalut 2,num int not null);
先说一点:在我们插入数据的时候,可以这么写insert into tb1(nid,num) values(1,‘chao’);就是在插入输入的时候,指定字段插入数据,如果我在只给num插入值,可以这样写insert into tb1(num) values(‘chao‘);
==================not null====================
mysql> create table t1(id int); #id字段默认可以插入空
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t1 values(); #可以插入空
mysql> create table t2(id int not null); #设置字段id不为空
mysql> desc t2;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t2 values(); #不能插入空
ERROR 1364 (HY000): Field ‘id‘ doesn‘t have a default value
==================default====================
#设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
mysql> create table t3(id int default 1);
mysql> alter table t3 modify id int not null default 1;
==================综合练习====================
mysql> create table student(
-> name varchar(20) not null,
-> age int(3) unsigned not null default 18,
-> sex enum(‘male‘,‘female‘) default ‘male‘,
-> hobby set(‘play‘,‘study‘,‘read‘,‘music‘) default ‘play,music‘
-> );
mysql> desc student;
+-------+------------------------------------+------+-----+------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------------------------+------+-----+------------+-------+
| name | varchar(20) | NO | | NULL | |
| age | int(3) unsigned | NO | | 18 | |
| sex | enum(‘male‘,‘female‘) | YES | | male | |
| hobby | set(‘play‘,‘study‘,‘read‘,‘music‘) | YES | | play,music | |
+-------+------------------------------------+------+-----+------------+-------+
mysql> insert into student(name) values(‘chao‘);
mysql> select * from student;
+------+-----+------+------------+
| name | age | sex | hobby |
+------+-----+------+------------+
| chao| 18 | male | play,music |
+------+-----+------+------------+
注意一点:如果是非严格模式,int类型不传值的话会默认为0,因为null不是int类型的,字段是int类型,所以他会自动将null变为0
============设置唯一约束 UNIQUE===============
方法一:
create table department1(id int,name varchar(20) unique,comment varchar(100));
方法二:
create table department2(id int,name varchar(20),comment varchar(100),constraint uk_name unique(name));
mysql> insert into department1 values(1,‘IT‘,‘技术‘);
Query OK, 1 row affected (0.00 sec)
mysql> insert into department1 values(1,‘IT‘,‘技术‘);
ERROR 1062 (23000): Duplicate entry ‘IT‘ for key ‘name‘
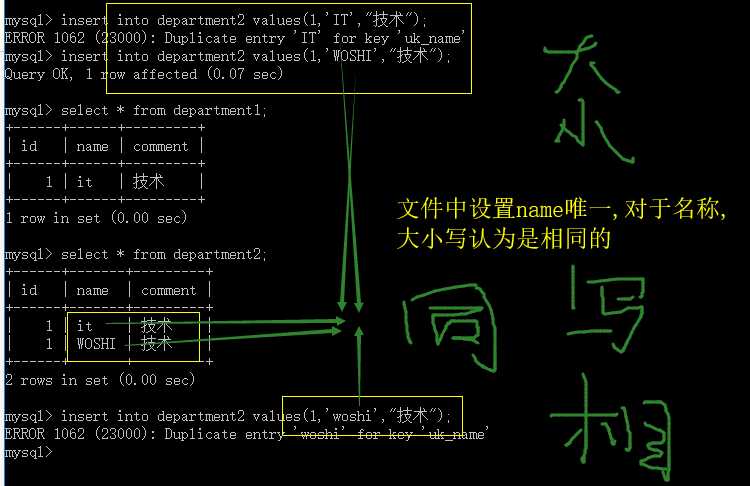
create table service(
id int primary key auto_increment,name varchar(20),
host varchar(15) not null,port int not null,unique(host,port) #联合唯一);
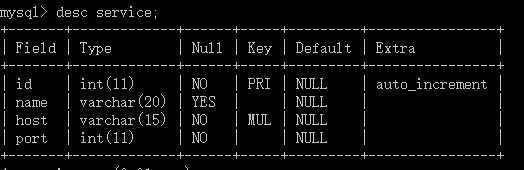 
#不指定id,则自动增长
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum(‘male‘,‘female‘) default ‘male‘
);
mysql> desc student;
+-------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum(‘male‘,‘female‘) | YES | | male | |
+-------+-----------------------+------+-----+---------+----------------+
mysql> insert into student(name) values
-> (‘egon‘),
-> (‘alex‘)
-> ;
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
| 2 | alex | male |
+----+------+------+
#也可以指定id
mysql> insert into student values(4,‘asb‘,‘female‘);
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(7,‘wsb‘,‘female‘);
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+--------+
| id | name | sex |
+----+------+--------+
| 1 | egon | male |
| 2 | alex | male |
| 4 | asb | female |
| 7 | wsb | female |
+----+------+--------+
#对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
mysql> delete from student;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> insert into student(name) values(‘ysb‘);
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 8 | ysb | male |
+----+------+------+
#应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(name) values(‘egon‘);
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
+----+------+------+
1 row in set (0.00 sec)
标签:tin 添加 medium section art 自增 utf8 win bytes
原文地址:https://www.cnblogs.com/lvweihe/p/11437236.html