标签:计数 bec 读取txt 统计 python实例 结果 end 返回 code
思路:
1、打开书本“更多”短评,复制链接
2、脚本分析链接,通过获取短评数,计算出页码数
3、通过页码数,循环爬取当页短评
4、短评写入到txt文本
5、读取txt文本,处理文本,输出出现频率最高的词组(前X)----通过分析得到其他结果可自由发散
用到的库:
lxml 、re、jieba、time
整个脚本如下
# -*-coding:utf8-*- # encoding:utf-8 #豆瓣每页20条评论 import requests from lxml import etree import re import jieba import time firstlink = "https://book.douban.com/subject/30193594/comments/" def stepc(firstlink):#获取评论条数 url=firstlink response = requests.get(url=url) wb_data = response.text html = etree.HTML(wb_data) a = html.xpath(‘//*[@id="total-comments"]/text()‘) return(a) a=stepc(firstlink) c=re.sub(r‘\D‘, "", a[0])#返回评论数筛选数字 d=int(int(c)/20+1)#通过评论数计算出页码数,评论数/20+1 print("当前评论有"+ str(d) +"页,请耐心等待") def stepa (firstlink,d):#读取评论内容 content=[] for page in range(1,d): url=firstlink+"hot?p"+str(page) response = requests.get(url=url) wb_data = response.text html = etree.HTML(wb_data) a = html.xpath(‘//*[@id="comments"]//div[2]/p/span/text()‘) content.append(a) return(content) a=stepa (firstlink,d) def stepb(a):#写入txt for b in a: for c in b: with open(‘C:/Users/Beckham/Desktop/python/2.txt‘, ‘a‘,encoding=‘utf-8‘) as w: w.write(‘\n‘+c) w.close() stepb(a) print("完成评论爬取,接下来分析关键字") time.sleep(5) def stepd():#分析评论 txt=open("C:\\Users\\Beckham\\Desktop\\python\\2.txt","r", encoding=‘utf-8‘).read() #打开倚天屠龙记文本 exculdes={} #创建字典,主要用于存储非人物名次,供后面剔除使用 words=jieba.lcut(txt) #jieba库分析文本 counts={} for word in words: #筛选分析后的词组 if len(word)==1: #因为词组中的汉字数大于1个即认为是一个词组,所以通过continue结束点读取的汉字书为1的内容 continue else: word=word counts[word]=counts.get(word,0)+1 #对word出现的频率进行统计,当word不在words时,返回值是0,当rword在words中时,返回+1,以此进行累计计数 for word in exculdes:#如果循环读取到的词组与exculdes字典内的内容匹配,那么过滤掉(不显示)这个词组 del(counts[word]) items=list(counts.items())#字典到列表 items.sort(key=lambda x:x[1],reverse=True)#lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序 for i in range(15):#显示前15位数据 word,count=items[i] print("{0:<10}{1:>10}".format(word,count)) #0:<10左对齐,宽度10,”>10"右对齐 stepd() print("分析完成")
执行结果
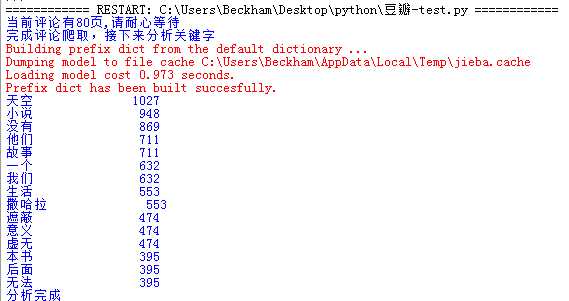
需要注意的是,如果频繁执行这个脚本,豆瓣会认为ip访问过多,弹出需要登录的页面
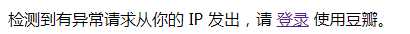
其他解析,在脚本内有注释
标签:计数 bec 读取txt 统计 python实例 结果 end 返回 code
原文地址:https://www.cnblogs.com/becks/p/11440333.html