标签:upper 版本 find 函数式编程 out 项目应用 private foreach 初始
前言
Java8(又称为 Jdk1.8)是 Java 语言开发的一个主要版本。Oracle 公司于 2014 年 3 月 18 日发布 Java8,它支持函数式编程,新的 JavaScript 引擎,新的日期 API,新的 Stream API 等。Java8 API 添加了一个新的抽象称为流 Stream,可以让你以一种声明的方式处理数据。Stream API 可以极大提高 Java 进程员的生产力,让进程员写出高效率、干净、简洁的代码。
Java8 新特性
- Lambda 表达式 ? Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中。
- 方法引用 ? 方法引用提供了非常有用的语法,可以直接引用已有 Java 类或对象(实例)的方法或构造器。与 lambda 联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 默认方法 ? 默认方法就是一个在接口里面有了一个实现的方法。
- 新工具 ? 新的编译工具,如:Nashorn 引擎 jjs、类依赖分析器 jdeps。
- Stream API ? 新添加的 Stream API(java.util.stream)把真正的函数式编程风格引入到 Java 中。
- Date Time API ? 加强对日期与时间的处理。
- Optional 类 ? Optional 类已经成为 Java8 类库的一部分,用来解决空指针异常。
- Nashorn JavaScript 引擎 ? Java8 提供了一个新的 Nashorn javascript 引擎,它允许我们在 JVM 上运行特定的 javascript 应用。
为什么需要 Steam?
Java8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作,或者大批量数据操作。
StreamAPI 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和进程可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。
流的操作种类
中间操作
当数据源中的数据上了流水线后,这个过程对数据进行的所有操作都称为“中间操作”。
中间操作仍然会返回一个流对象,因此多个中间操作可以串连起来形成一个流水线。
终端操作
当所有的中间操作完成后,若要将数据从流水线上拿下来,则需要执行终端操作。
终端操作将返回一个执行结果,这就是你想要的数据。
java.util.Stream 使用示例
定义一个简单的学生实体类,用于后面的例子演示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
public class {
private long id;
private String name;
private int age;
private int grade;
private String major;
private String school;
}
List<Student> students = new ArrayList<Student>() {
{
add(new Student(20160001, "孔明", 20, 1, "土木工程", "武汉大学"));
add(new Student(20160002, "伯约", 21, 2, "信息安全", "武汉大学"));
add(new Student(20160003, "玄德", 22, 3, "经济管理", "武汉大学"));
add(new Student(20160004, "云长", 21, 2, "信息安全", "武汉大学"));
add(new Student(20161001, "翼德", 21, 2, "机械与自动化", "华中科技大学"));
add(new Student(20161002, "元直", 23, 4, "土木工程", "华中科技大学"));
add(new Student(20161003, "奉孝", 23, 4, "计算机科学", "华中科技大学"));
add(new Student(20162001, "仲谋", 22, 3, "土木工程", "浙江大学"));
add(new Student(20162002, "鲁肃", 23, 4, "计算机科学", "浙江大学"));
add(new Student(20163001, "丁奉", 24, 5, "土木工程", "南京大学"));
}
};
|
forEach
Stream 提供了新的方法’forEach’来迭代流中的每个数据。ForEach 接受一个 function 接口类型的变量,用来执行对每一个元素的操作。ForEach 是一个中止操作,它不返回流,所以我们不能再调用其他的流操作。
以下代码片段使用 forEach 输出了 10 个随机数:
1
2
3
4
5
|
new Random()
.ints(0, 100)
.limit(10)
.forEach(System.out::println);
|
从集合 students 中筛选出所有武汉大学的学生:
1
2
3
4
|
List<Student> whuStudents = students
()
.filter(student -> "武汉大学".equals(student.getSchool()))
.collect(Collectors.toList())
|
filter/distinct[过滤操作]
filter 方法用于通过设置的条件过滤出元素。Filter 接受一个 predicate 接口类型的变量,并将所有流对象中的元素进行过滤。该操作是一个中间操作,因此它允许我们在返回结果的基础上再进行其他的流操作。
以下代码片段使用 filter 方法过滤出空字符串:
1
2
3
4
5
6
|
Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.filter(string -> string.isEmpty())
.count();
|
distinct 方法用于去除重复元素。
1
2
3
4
|
Arrays.asList("a", "c", "ac", "c", "a", "b")
.stream()
.distinct()
.forEach(System.out::println);
|
anyMatch/allMatch/noneMatch
匹配操作有多种不同的类型,都是用来判断某一种规则是否与流对象相互吻合的。所有的匹配操作都是终结操作,只返回一个 boolean 类型的结果。
anyMatch 方法用于判断集合中是否有任一元素满足条件。
1
2
3
4
|
boolean result = Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.anyMatch(s -> s.startsWith("a"));
|
allMatch 方法用于判断集合中是否所有元素满足条件。
1
2
3
4
|
boolean result = Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.allMatch(s -> s.startsWith("a"));
|
noneMatch 方法用于判断集合中是否所有元素不满足条件。
1
2
3
4
|
boolean result = Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.noneMatch(s -> s.startsWith("a"));
|
limit/skip
limit 方法用于返回前面 n 个元素。
1
2
3
4
5
|
Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.filter(string -> !string.isEmpty())
.limit(3)
.forEach(System.out::println);
|
skip 方法用于舍弃前 n 个元素。
1
2
3
4
5
|
Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.filter(string -> !string.isEmpty())
.skip(1)
.forEach(System.out::println);
|
sorted[排序操作]
sorted 方法用于对流进行排序。Sorted 是一个中间操作,能够返回一个排过序的流对象的视图。流对象中的元素会默认按照自然顺序进行排序,除非你自己指定一个 Comparator 接口来改变排序规则。
以下代码片段使用 filter 方法过滤掉空字符串,并对其进行自然顺序排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
List<String> strings = Arrays.asList("abc", "","bc","efg","abcd","", "jkl");
strings
.stream()
.filter(string -> !string.isEmpty())
.sorted()
.forEach(System.out::println);
strings
.stream()
.forEach(System.out::println);
strings
.stream()
.filter(string -> !string.isEmpty())
.sorted(Comparator.comparing(String::length).reversed().thenComparing(String::compareTo))
.forEach(System.out::println);
|
以下代码片段根据 Person 姓名倒序排序,然后利用 Collectors 返回列表新列表:
1
2
3
4
5
6
7
8
9
10
11
12
|
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList = persons
.stream()
.sorted(Comparator.comparing(Person::getName).reversed())
.collect(Collectors.toList());
|
parallel
流操作可以是顺序的,也可以是并行的。顺序操作通过单线程执行,而并行操作则通过多线程执行。可使用并行流进行操作来提高运行效率 parallelStream 是流并行处理进程的代替方法。
parallelStream()本质上基于 Java7 的 Fork-Join 框架实现,其默认的线程数为宿主机的内核数。
以下实例我们使用 parallelStream 来输出空字符串的数量:
1
2
3
4
5
6
|
Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.parallelStream()
.filter(string -> string.isEmpty())
.count();
|
parallelStream 中 forEachOrdered 与 forEach 区别:
1
2
3
4
5
|
List<String> strings = Arrays.asList("a", "b", "c");
strings.stream().forEachOrdered(System.out::print);
strings.stream().forEach(System.out::print);
strings.parallelStream().forEachOrdered(System.out::print);
strings.parallelStream().forEach(System.out::print);
|
map[变换操作]
map 方法用于映射每个元素到对应的结果。map 是一个对于流对象的中间操作,通过给定的方法,它能够把流对象中的每一个元素对应到另外一个对象上。
以下代码片段使用 map 将集合元素转为大写 (每个元素映射到大写)-> 降序排序 ->迭代输出:
1
2
3
4
5
6
7
8
9
10
11
|
Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.filter(string -> !string.isEmpty())
.map(String::toUpperCase)
.sorted(Comparator.reverseOrder())
.forEach(System.out::println);
|
筛选出所有专业为计算机科学的学生姓名:
1
2
3
4
|
List<String> names = students
.stream()
.filter(student -> "计算机科学".equals(student.getMajor()))
.map(Student::getName).collect(Collectors.toList());
|
计算所有专业为计算机科学学生的年龄之和:
1
2
3
4
|
int totalAge = students
.stream()
.filter(student -> "计算机科学".equals(student.getMajor()))
.mapToInt(Student::getAge).sum()
|
findFirst/findAny()
findAny 能够从流中随便选一个元素出来,它返回一个 Optional 类型的元素。
1
2
3
|
Optional<String> optional = Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.findAny();
|
findFirst 能够从流中选第一个元素出来,它返回一个 Optional 类型的元素。
1
2
3
|
Optional<String> optional = Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
.stream()
.findFirst();
|
collect
collect 方法是一个终端操作,它接收的参数是将流中的元素累积到汇总结果的各种方式(称为收集器)。
Collectors 工具类提供了许多静态工具方法来为大多数常用的用户用例创建收集器,比如将元素装进一个集合中、将元素分组、根据不同标准对元素进行汇总等。
Collectors.joining()
Collectors.joining()方法以遭遇元素的顺序拼接元素。我们可以传递可选的拼接字符串、前缀和后缀。
1
2
3
4
5
6
7
8
9
10
11
12
|
List<String> strings = Arrays.asList("abc", "","bc","efg","abcd","", "jkl")
// 筛选列表
List<String> filtered = strings
.stream()
.filter(string -> !string.isEmpty())
.collect(Collectors.toList())
// 合并字符串
String mergedString = strings
.stream()
.filter(string -> !string.isEmpty())
.collect(Collectors.joining(","))
|
Collectors.groupingBy
Collectors.groupingBy 方法根据项目的一个属性的值对流中的项目作问组,并将属性值作为结果 Map 的键。
- List 里面的对象元素,以某个属性来分组。
1
2
3
4
5
6
7
8
9
10
11
|
Map<String, List<Student>> groups = students
.stream()
.collect(Collectors.groupingBy(Student::getSchool));
Map<String, Map<String, List<Student>>> groups2 = students
.stream()
.collect(
Collectors.groupingBy(Student::getSchool,
Collectors.groupingBy(Student::getMajor)));
|
- 统计 List 集合重复元素出现次数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
List<String> items = Arrays.asList("apple", "apple", "banana", "apple", "orange", "banana", "papaya");
Map<String, Long> result = items
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
Map<String, Long> result2 = items
.stream()
.collect(Collectors.groupingBy(String::toString, Collectors.counting()));
|
统计每个组的个数:
1
2
3
|
Map<String, Long> groups = students
.stream()
.collect(Collectors.groupingBy(Student::getSchool, Collectors.counting()));
|
- 累加求和
1
2
3
4
5
|
Map<String, Integer> sumMap = persons
.stream()
.collect(Collectors.groupingBy(Person::getName, Collectors.summingInt(Person::getAge)));
|
Collectors.toMap
Collectors.toMap 方法将 List 转 Map。
1
2
3
4
5
6
7
8
9
|
Map<Integer, Person> personMap = persons
.stream()
.collect(Collectors.toMap(Person::getAge, person -> person));
Map<Integer, Person> personMap = persons
.stream()
.collect(Collectors.toMap(Person::getAge, Function.identity()));
|
当 key 重复时,会抛出异常:java.lang.IllegalStateException: Duplicate key **
1
2
3
4
|
Map<Integer, Person> personMap = persons
.stream()
.collect(Collectors.toMap(Person::getAge, Function.identity(), (person, person2) -> person2));
|
指定具体收集的 map:
1
2
3
4
|
Map<Integer, Person> personMap = persons
.stream()
.collect(Collectors.toMap(Person::getAge, Function.identity(), (person, person2) -> person2, LinkedHashMap::new));
|
当 value 为 null 时,会抛出异常:java.lang.NullPointerException[Collectors.toMap 底层是基于 Map.merge 方法来实现的,而 merge 中 value 是不能为 null 的,如果为 null,就会抛出空指针异常。
1
2
3
|
Map<Integer, String> personMap = persons
.stream()
.collect(Collectors.toMap(Person::getAge, Person::getName, (person, person2) -> person2));
|
1
2
3
4
5
6
7
8
9
|
Map<Integer, String> personMap = new HashMap<>();
for (Person person : persons) {
personMap.put(person.getAge(), person.getName());
}
Map<Integer, String> personMap = persons
.stream()
.collect(HashMap::new, (m, v) -> m.put(v.getAge(), v.getName()), HashMap::putAll);
|
Collectors.collectingAndThen
Collectors.collectingAndThen 方法主要用于转换函数返回的类型。
List 里面的对象元素,以某个属性去除重复元素。
1
2
3
|
List<Person> unique = persons
.stream()
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparingInt(Person::getAge))), ArrayList::new));
|
Collectors.partitioningBy
Collectors.partitioningBy 方法主要用于根据对流中每个项目应用谓词的结果来对项目进行分区。
“年龄小于 18”进行分组后可以看到,不到 18 岁的未成年人是一组,成年人是另外一组。
1
2
3
|
Map<Boolean, List<Person>> groupBy = persons
.stream()
.collect(Collectors.partitioningBy(o -> o.getAge() >= 18));
|
Collectors 收集器静态方法:


数值流的使用
在 Stream 里元素都是对象,那么,当我们操作一个数字流的时候就不得不考虑一个问题,拆箱和装箱。虽然自动拆箱不需要我们处理,但依旧有隐含的成本在里面。Java8 引入了 3 个原始类型特化流接口来解决这个问题:IntStream、DoubleStream、LongStream,分别将流中的元素特化为 int、long、double,从而避免了暗含的装箱成本。
将对象流映射为数值流
1
2
3
4
|
// 将对象流映射为数值流
IntStream intStream = persons
.stream()
.mapToInt(Person::getAge);
|
默认值 OptinalInt
由于数值流经常会有默认值,比如默认为 0。数值特化流的终端操作会返回一个 OptinalXXX 对象而不是数值。
1
2
3
4
5
6
7
|
// 每种数值流都提供了数值计算函数, 如 max、min、sum 等
OptionalInt optionalInt = persons
.stream()
.mapToInt(Person::getAge)
.max();
int max = optionalInt.orElse(1);
|
生成一个数值范围流
1
2
3
4
|
IntStream intStream = IntStream.rangeClosed(1, 10);
IntStream range = IntStream.range(1, 9);
|
将数值流转回对象流
1
2
|
Stream<Integer> boxed = intStream.boxed();
|
流的扁平化
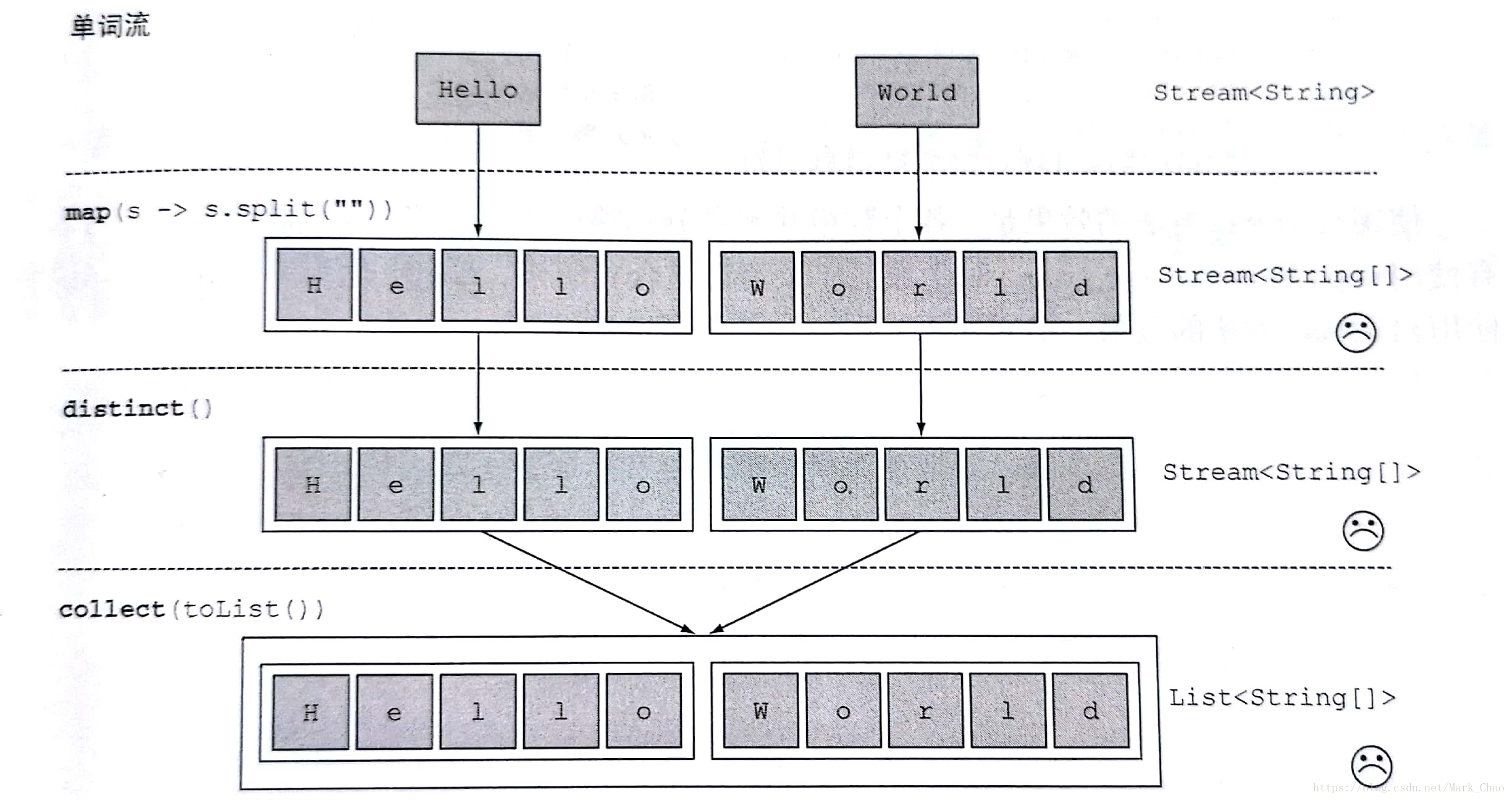
案例:对给定单词列表 [“Hello”,”World”],你想返回列表[“H”,”e”,”l”,”o”,”W”,”r”,”d”]
方法一:错误方式
1
2
3
4
5
6
7
8
9
|
String[] words = new String[]{"Hello", "World"};
List<String[]> a = Arrays.stream(words)
.map(word -> word.split(""))
.distinct()
.collect(Collectors.toList());
a.forEach(System.out::print);
|
返回一个包含两个 String[]的 list,传递给 map 方法的 lambda 为每个单词生成了一个 String[]。因此,map 返回的流实际上是 Stream<String[]>类型的。
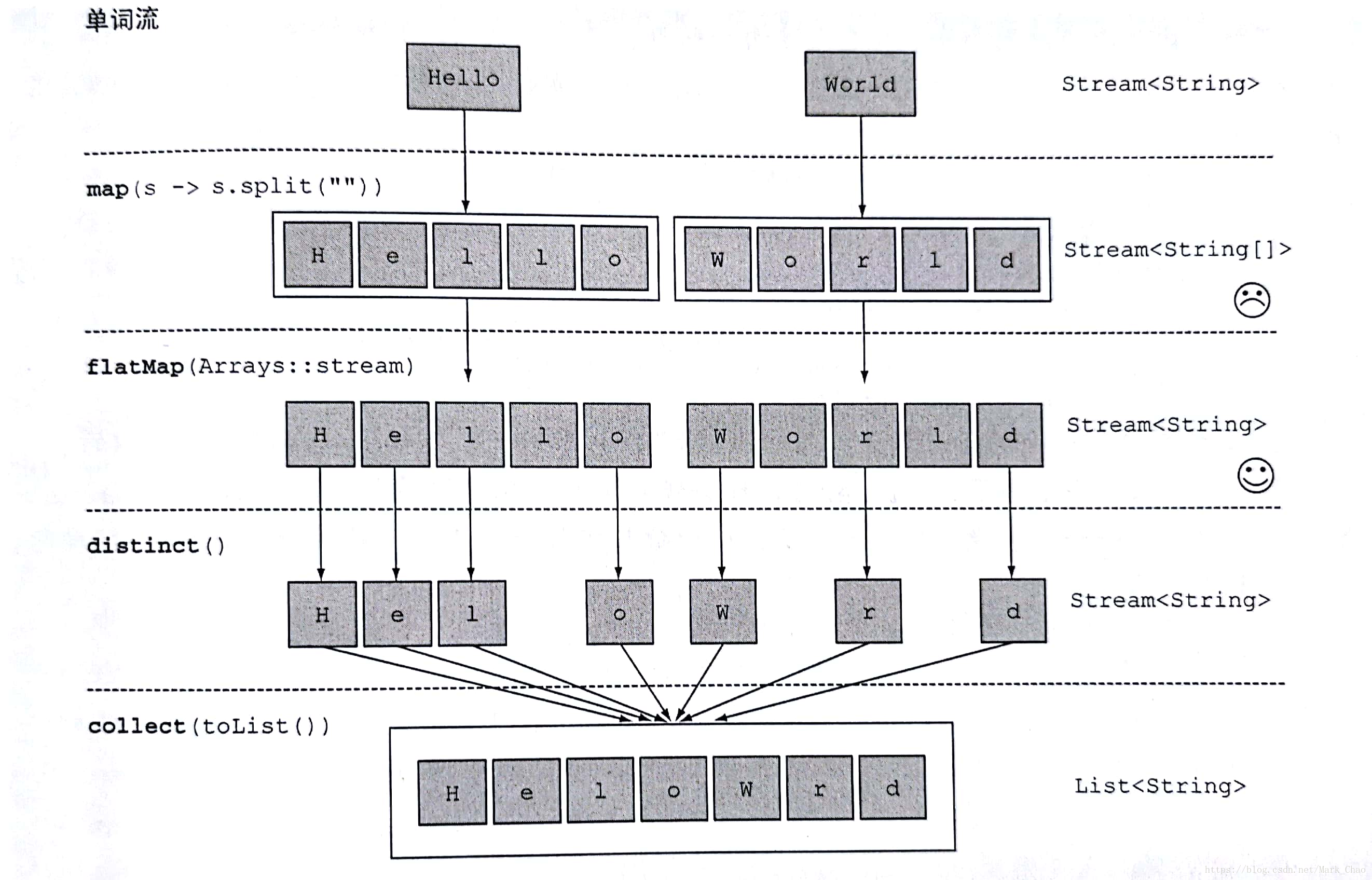
方法二:正确方式
1
2
3
4
5
6
7
8
9
10
|
String[] words = new String[]{"Hello", "World"};
List<String> a = Arrays.stream(words)
.map(word -> word.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
a.forEach(System.out::print);
|
使用 flatMap 方法的效果是,各个数组并不是分别映射一个流,而是映射成流的内容,所有使用 map(Array::stream)时生成的单个流被合并起来,即扁平化为一个流。
参考博文
[1]. Java 8 中的 Streams API 详解
[2]. java8 快速实现 List 转 map 、分组、过滤等操作
Java8 那些事儿系列
原文:大专栏 Java8 那些事儿(一):Stream 函数式编程
Java8 那些事儿(一):Stream 函数式编程
标签:upper 版本 find 函数式编程 out 项目应用 private foreach 初始
原文地址:https://www.cnblogs.com/petewell/p/11445403.html
