标签:必须 完全 聚集 practice href 十分 命名 执行 字典
模块
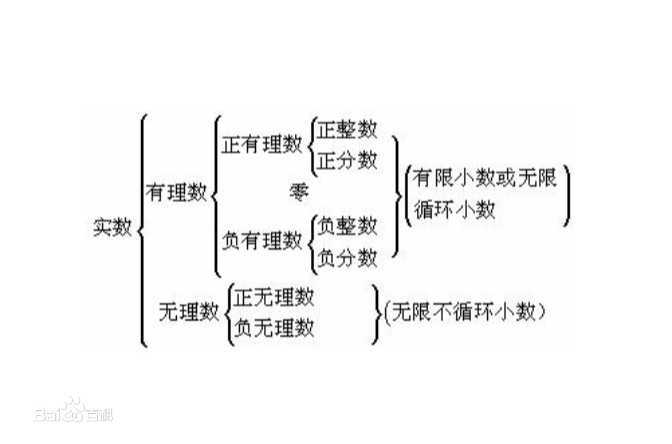
数据类型
数据运算
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持。
sys
|
1
2
3
4
5
6
7
8
9
10
11
|
#!/usr/bin/env python# -*- coding: utf-8 -*-import sysprint(sys.path)
print(sys.argv)#输出$ python test.py helo world[‘test.py‘, ‘helo‘, ‘world‘] #把执行脚本时传递的参数获取到了 |
os
|
1
2
3
4
5
6
|
#!/usr/bin/env python# -*- coding: utf-8 -*-import oscmd_res2=os.popen(‘dir‘).read()
#print(cmd_res)
print(cmd_res2)
|
完全结合一下
|
1
2
3
|
import os,sysos.system(‘‘.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行 |
自己写个模块
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# info.py
name = input(‘name:‘)
age = int(input(‘age:‘))#integer
print(type(age),type(str(age)))
job = input(‘job:‘)
salary = int(input(‘salary:‘))
info = ‘‘‘
------------ info of %s -----------
Name: %s
Age: %d
Job: %s
salary: %d
‘‘‘ % (name,name,age,job,salary)
print(info)
info2 = ‘‘‘
-------- info of {_name} --------
Name:{_name}
Age:{_age}
Job:{_job}
Salary:{_salary}
‘‘‘.format(_name=name,_age=age,_job=job,_salary=salary)
print(info2)
info3 =‘‘‘
--------- info of {0} ---------
Name:{0}
Age:{1}
Job:{2}
Salary:{3}
‘‘‘.format(name,age,job,salary)
print(info3)
然后在python的sys.path路径下就可以导入。python文件也是模块。
1、数字
1 是一个整数。它是一个字面意义上的常量,因为不能改变它的值。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
2、布尔值
True或False
1 或 0
3、字符串(不可变)
字符串是 字符的序列 。字符串基本上就是一组单词。单词可以是英语或其 它由 Unicode 标准支持的语言。
"hello world"
● 使用单引号(‘)
你可以用单引号指示字符串,就如同‘Quote me on this‘这样。所有的空白,即空格和制 表符都照原样保留。
● 使用双引号(")
在双引号中的字符串与单引号中的字符串的使用完全相同,例如"What‘s your name?"。
● 使用三引号(‘‘‘或""")
利用三引号,你可以指示一个多行的字符串。你可以在三引号中自由的使用单引号和双 引号。
字符串格式化输出
|
1
2
3
4
|
name = "alex"print "i am %s " % name #输出: i am alex |
PS: 字符串是%s;整数%d;浮点数%f。
format 方法
#!/usr/bin/python
# Filename: str_format.py
age = 25
name = ‘Swaroop‘
print(‘{0} is {1} years old‘.format(name, age))
print(‘Why is {0} playing with that python?‘.format(name))
$ python str_format.py
Swaroop is 25 years old
Why is Swaroop playing with that python?
操作实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: lvlibing
name = ‘biLlYLV‘
print(name.isidentifier()) #检测一段字符串可否被当作标志符,即是否符合变量命名规则
print(name.capitalize()) #首字母大写,后面的其它字母都小写
print(name.casefold()) #大写全部变小写
print(name.center(80,‘-‘)) #以biLlYLV为中心生成80个字符,不够的以-来补全。
print(name.count(‘l‘)) #统计l出现次数
print(name.startswith(‘b‘))
print(name.endswith(‘V‘)) #判断字符串是否以V结尾
print(name.find(‘i‘)) #返回在其中找到子字符串的最低索引
print(name.index(‘i‘)) #返回i所在字符串的索引
print(name.lower()) #所有小写
print(name.upper()) #所有大写
print(name.swapcase())#大小写互换
print(‘HI,‘+name) #字符串拼接
message = ‘my name is {0} , city is {1}‘
print(message.format(‘lv‘,‘wh‘))
joins = "|".join([‘alex‘,‘jack‘,‘rain‘])
print(joins)
查看帮助:
4、列表
list 是处理一组有序项目的数据结构,即你可以在一个列表中存储一个序列的项 目。
列表中的项目应该包括在方括号中,这样 Python 就知道你是在指明一个列表。 一旦你创建了一个列表,你可以添加、删除或是搜索列表中的项目。由于你可以增加 或删除项目,我们说列表是可变的数据类型,即这种类型是可以被改变的。
|
1
2
3
|
name_list = [‘alex‘, ‘seven‘, ‘eric‘]或name_list = list([‘alex‘, ‘seven‘, ‘eric‘]) |
基本操作:
操作实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: lvlibing
import copy
names = [‘0‘,‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘]
names.append([‘a‘,‘b‘,‘c‘])
#names3 = names.copy() #浅拷贝
names3 = copy.deepcopy(names) #深拷贝
print(‘names3‘,names3)
#print(names[-1][0])
names[1]=‘10‘ #改值
names[-1][0]=‘aa‘
print(names)
print(names3)
print(names[1:]) #切片,取出从索引1开始的所有的值
print(names[1:8:2]) #切片,后面的2是代表,每隔一个元素,就取一个
names.append(‘100‘) #追加
names.insert(4,‘4‘) #往索引4的位置插入4
names.pop(-2) #删除,不加索引,默认删除列表最后一个值
names.remove(‘4‘) #删除
names.remove(‘4‘)
names[2]=‘200‘
names2 = [‘100‘,‘200‘]
names.extend(names2) #把names2扩展合并到names列表
print(names)
del names2 #删除
print(names.count("0")) #统计0的个数
print(names.sort()) #排序
print(names.reverse()) #反转
print(names.index(‘100‘)) #获取(索引)下标,只返回找到的第一个下标
names.clear() #清空列表
print(names) #打印列表
|
1
2
3
|
ages = (11, 22, 33, 44, 55)或ages = tuple((11, 22, 33, 44, 55)) |
|
1
2
3
|
person = {"name": "mr.wu", ‘age‘: 18}或person = dict({"name": "mr.wu", ‘age‘: 18}) |
常用操作:
操作实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: lvlibing
dicts = {‘bj‘:‘王府井‘,‘sh‘:‘陆家嘴‘,‘gz‘:‘小蛮腰‘,‘sz‘:‘南山‘,‘zj‘:‘杭州‘}
print(dicts)
print(dicts.keys()) #获取字典的所有key
print(dicts.values()) #获取字典的所有值
print(dicts.items())#获取字典的键值对
dicts[‘wh‘]=‘光谷‘#增加
dicts[‘gz‘]=‘广州塔‘#修改
dicts.pop(‘gz‘)#删除
del dicts[‘sz‘]#删除
dicts.popitem()#随机删除一个
print(dicts.get(‘sh‘))#获取键sh的值
dicts.setdefault(‘sc‘,‘成都‘) #有就不改,没有加添加
dicts.pop(‘bj‘)
info = { 0:‘香港‘,1:‘澳门‘,2:‘台湾‘} #定义字典
dicts.update(info)#字典更新合并
print(dicts)
dicts2 = dict.fromkeys([1,2,3,4,5],‘城市‘)#通过一个列表生成默认dict
print(dicts2)
for i in dicts:
print(i,dicts[i])
# print(‘---------‘)
# for k,v in dicts.items(): #会先把dict转成list,数据量大费时莫用
# print(k,v)
7、集合
集合是没有顺序的不重复的简单对象的聚集。当在聚集中一个对象的存在比其顺序或者出现的次数重要时使用集合。
主要作用如下:
操作实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: lvlibing
# __doc__ practice
set1 = set([1,2,3]) #定义一个集合
set2 = set([2,3,4]) #定义一个集合
set1.add(5)
set1.update({7,8,9})
set1.pop()
set1.remove(7)
set2.add(6)
set2.update([8,9,10])
set2.pop()
set2.remove(10)
print(set1,type(set1))
print(set2,type(set2))
print(set1 & set2)
print(set1.intersection(set2)) #交集
print(set1 | set2)
print(set1.union(set2)) #并集
print(‘----‘)
print(set1.difference(set2)) #差集
print(set1 - set2)
print(set1.symmetric_difference(set2)) #对称差集
print(set1 ^ set2)
print(set1 >= set2)
print(set1.issuperset(set2)) #超集
print(set1 <= set2)
print(set1.issubset(set2)) #子集
print(set1 in set2)
print(set2 not in set1)
s3 = set1.copy()
print(s3,type(s3))
print(len(s3),len(set1)) #集合长度
不可变类型有:数字、字符串、元组。
技巧
你可以交互地使用解释器来计算例子中给出的表达式。例如,为了测试表达式2 + 3,使 用交互式的带提示符的Python解释器:
>>> 2 + 3
5
>>> 3 * 5
15
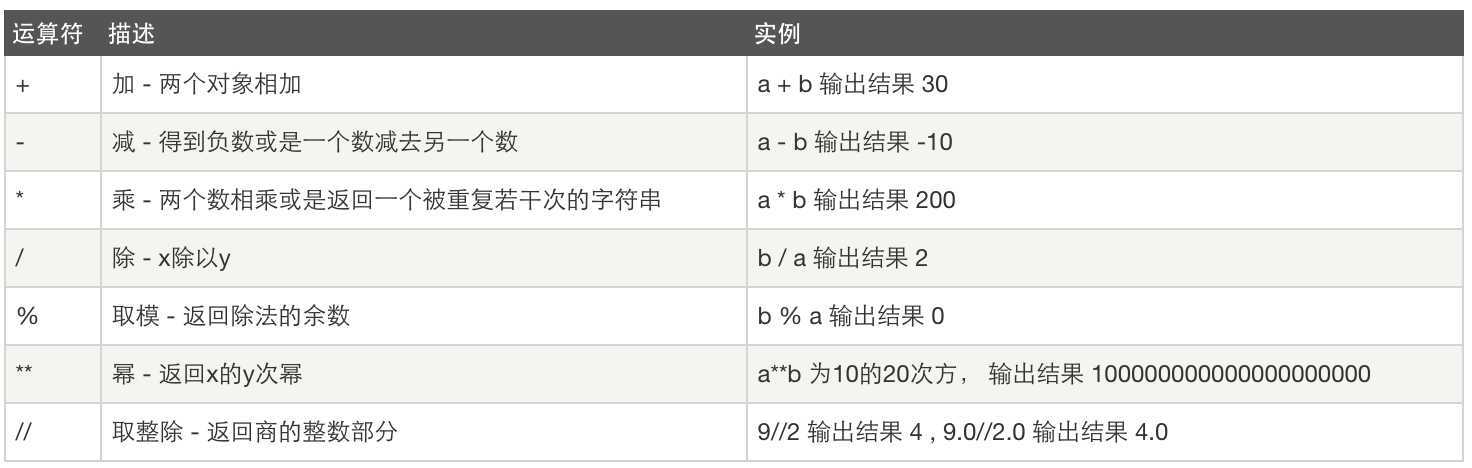
算数运算:
比较运算:

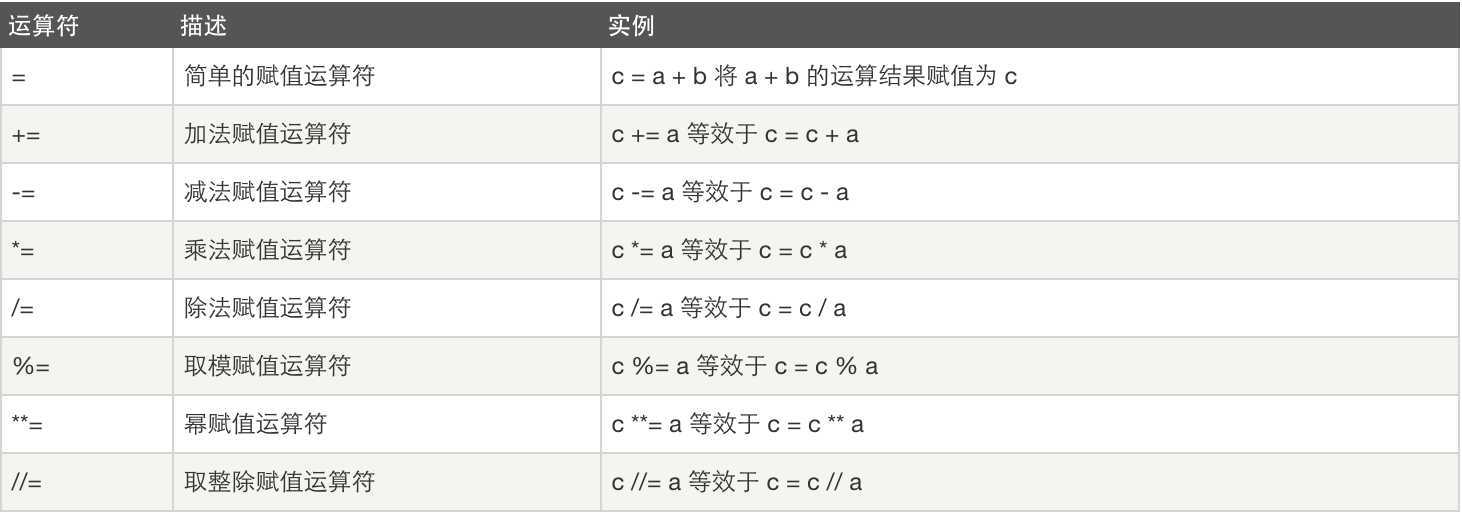
赋值运算:
逻辑运算:

成员运算:

身份运算:

位运算:
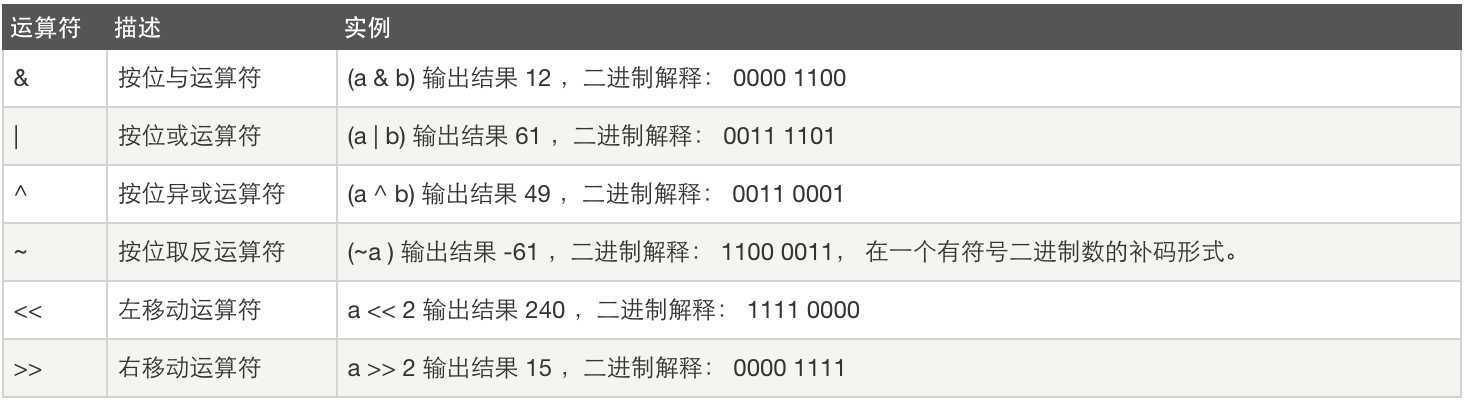
#!/usr/bin/python a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = 0 c = a & b; # 12 = 0000 1100 print "Line 1 - Value of c is ", c
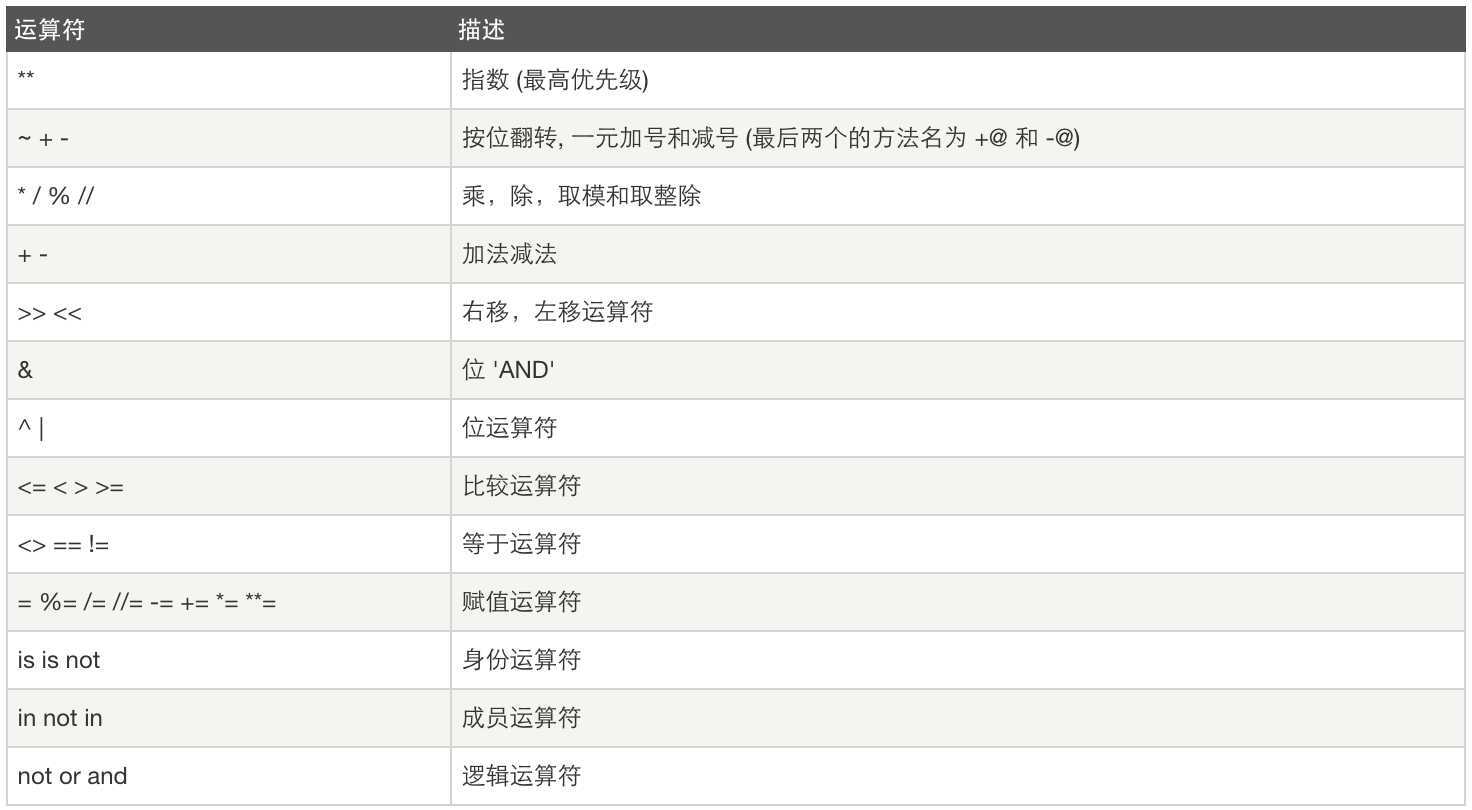
运算符优先级:
三元运算
|
1
|
result = 值1 if 条件 else 值2 |
如果条件为真:result = 值1
如果条件为假:result = 值2
字典和字符串转换 eval()和str()函数
myDict = eval(myStr)
myStr = str(myDict)

参考:
http://www.cnblogs.com/alex3714
internet&python books
PS:如侵权,联我删。
标签:必须 完全 聚集 practice href 十分 命名 执行 字典
原文地址:https://www.cnblogs.com/BillyLV/p/6941117.html