标签:cdn 思考 output for 元素 get sample 研究 字典序
Tom最近在研究一个有趣的排序问题。如图所示,通过2个栈S1和S2,Tom希望借助以下4种操作实现将输入序列升序排序。
操作a
如果输入序列不为空,将第一个元素压入栈S1
操作b
如果栈S1不为空,将S1栈顶元素弹出至输出序列
操作c
如果输入序列不为空,将第一个元素压入栈S2?
操作d
如果栈S2?不为空,将S2栈顶元素弹出至输出序列
如果一个1−n的排列P可以通过一系列操作使得输出序列为1,2,…,(n−1),Tom就称P是一个“可双栈排序排列”。例如(1,3,2,4)就是一个“可双栈排序序列”,而(2,3,4,1)不是。下图描述了一个将(1,3,2,4)排序的操作序列:<a,c,c,b,a,d,d,b>
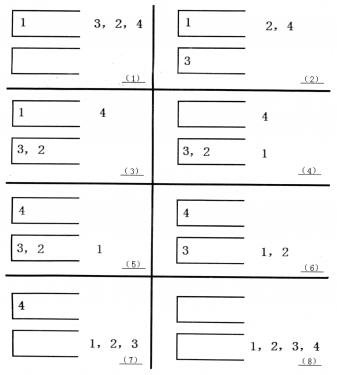
当然,这样的操作序列有可能有几个,对于上例(1,3,2,4),<a,c,c,b,a,d,d,b>是另外一个可行的操作序列。Tom希望知道其中字典序最小的操作序列是什么。
第一行是一个整数n。
第二行有n个用空格隔开的正整数,构成一个1−n的排列。
共一行,如果输入的排列不是“可双栈排序排列”,输出数字0;否则输出字典序最小的操作序列,每两个操作之间用空格隔开,行尾没有空格。
4 1 3 2 4
a b a a b b a b
4 2 3 4 1
0
3 2 3 1
a c a b b d
30%的数据满足: n≤10
50%的数据满足:n≤50
100%的数据满足: n≤1000
一个简单的递推算法。
这个题目其实不需要二分图,也不需要搜索。
只要思考如果能够排序,元素需要满足什么性质,然后贪心地向A栈添加即可。
代码
#include<cmath>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int N=1010;
char ans[2*N];
int in[N],a[N],b[N];
int ad,bd,k,n,cnt,asd;
bool check(int k) {
if(!bd)
return 1;
int i,j;
for(i=k+1; i<=n; i++)
if(in[i]>in[k]&&in[i]>b[bd])
break;
for(j=i+1; j<=n; j++)
if(in[j]<in[k])
return false;
return true;
}
int main () {
bool able=1;
int at=1;
scanf("%d",&n);
a[0]=b[0]=1e4,asd=1;
for(int i=1; i<=n; i++)
scanf("%d",&in[i]);
for(int i=1; i<=(n<<1); i++) {
if(a[ad]==asd) {
ad--;
asd++;
ans[++cnt]=‘b‘;
continue;
}
if(b[bd]==asd) {
bd--;
asd++;
ans[++cnt]=‘d‘;
continue;
}
if(at<=n&&in[at]<a[ad]&&check(at)) {
a[++ad]=in[at];
ans[++cnt]=‘a‘;
at++;
continue;
}
if(at<=n&&in[at]<b[bd]) {
b[++bd]=in[at];
ans[++cnt]=‘c‘;
at++;
continue;
}
able=0;
break;
}
if(able)
for(int i=1; i<=cnt; i++)
putchar(ans[i]),putchar(‘ ‘);
else
printf("0");
printf("\n");
return 0;
}
标签:cdn 思考 output for 元素 get sample 研究 字典序
原文地址:https://www.cnblogs.com/mysh/p/11449468.html