标签:font board desktop read reverse cli int black for
近期开始学习python爬虫,熟悉了基本库、解析库之后,决定做个小Demo来实践下,检验学习成果。
目标站点为https://maoyan.com/board/4,打开之后就可以看到排行榜信息,如图所示
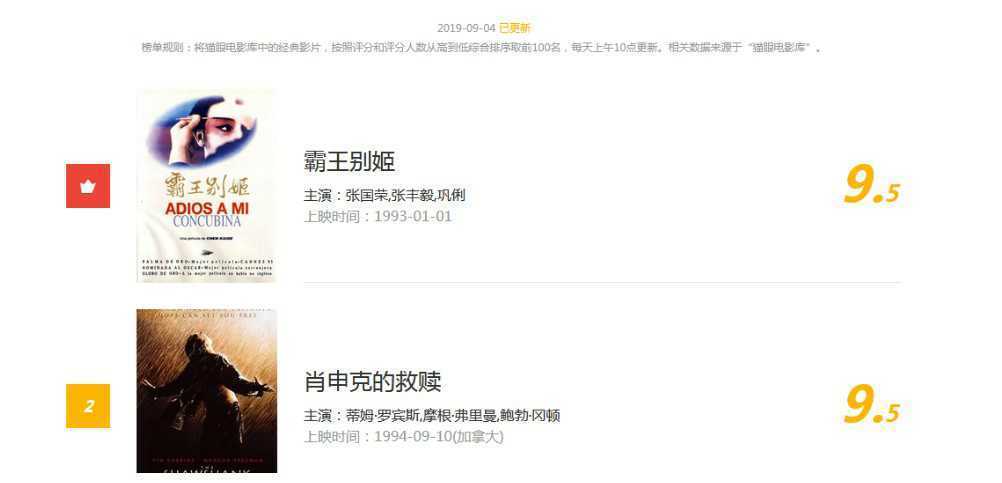
页面上显示10部电影,有名次、影片名称、演员信息等信息。当拉到最下面点击第二页的时候,发现url变成了https://maoyan.com/board/4?offset=10,对比原先多了个offset=10,第二页是显示排名11~20的电影,可以推断这是一个偏移量,所以第一页应该是offset=0,第二页是offset=10,依次类推。
url分析完之后,利用request模块,我们就可以试试抓取页面。
import requests
# 抓取一页电影信息
def get_one_page(page_index):
url = 'https://maoyan.com/board/4?offset=' + str(page_index)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'}
response = requests.get(url=url, headers=headers)页面成功抓取后需要解析提取信息,打开页面的开发者模式,在Network监听组件中查看源代码(注意:不在Elements选项中直接查看源码是因为该源码可能经过javascirpt渲染),如图:
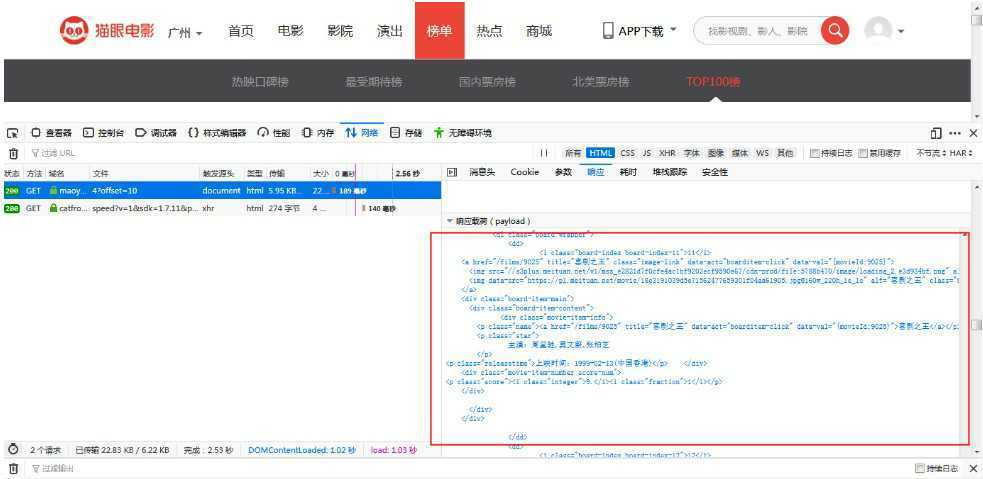
由图可知,一个影片所有信息是在一个<dd>标签里面,一页有10个。
其中名次信息位置是
<i class="board-index board-index-11">11</i>,电影名称信息位置是:
<p class="name">
<a href="/films/9025" title="喜剧之王" data-act="boarditem-click" data-val="{movieId:9025}">喜剧之王</a>
</p>演员信息位置是:
<p class="star">主演:周星驰,莫文蔚,张柏芝</p>知道了相关信息的位置,就可以利用Pyquery模块对资源进行定位和抓取。继续完善刚才的方法
import requests
from pyquery import PyQuery as pq
# 抓取一页电影信息
def get_one_page(page_index):
url = 'https://maoyan.com/board/4?offset=' + str(page_index)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'}
response = requests.get(url=url, headers=headers)
doc = pq(response.text)
page_info = ''
name_list = []
# 遍历<dd>标签,一页抓取10部电影
for i in doc('dd').items():
# 计算空格,用于美化格式
name_len = len(i('.name').children().text())
other_len = 15 - name_len
space = ''
for j in range(other_len):
space += ' '
# 按照‘排序 电影名称 主演’的方式返回文本
page_info += i('.board-index').text() + ' ' + i('.name').children().text() + space + i('.star').text() + '\n'
name_list += i('.star').text().split(':')[1].split(',')
# 返回一页电影信息和演员信息
return page_info, name_list在成功抓取一页信息之后,整合代码,将所有信息抓取并处理。
def info_handle():
# 存储电影信息
movie_info = ''
# 存储出现过的演员信息,有重复
name_info_list = []
for index in range(10):
movie_info += get_one_page(index * 10)[0]
name_info_list += get_one_page(index * 10)[1]
# 统计人名出现次数
name_count_list = []
for i in set(name_info_list):
dict_name_count = (i, name_info_list.count(i))
name_count_list.append(dict_name_count)
# 根据人名出现次数排行
name_count_list.sort(key=lambda k: k[1], reverse=True)
# 输出电影信息到文本
with open('C:\\Users\\d\\Desktop\\xxx.txt', 'w') as f:
f.write(movie_info)
# 打印演员出现次数
for k, v in name_count_list:
print(k, v)执行结果如下
txt文本内容:
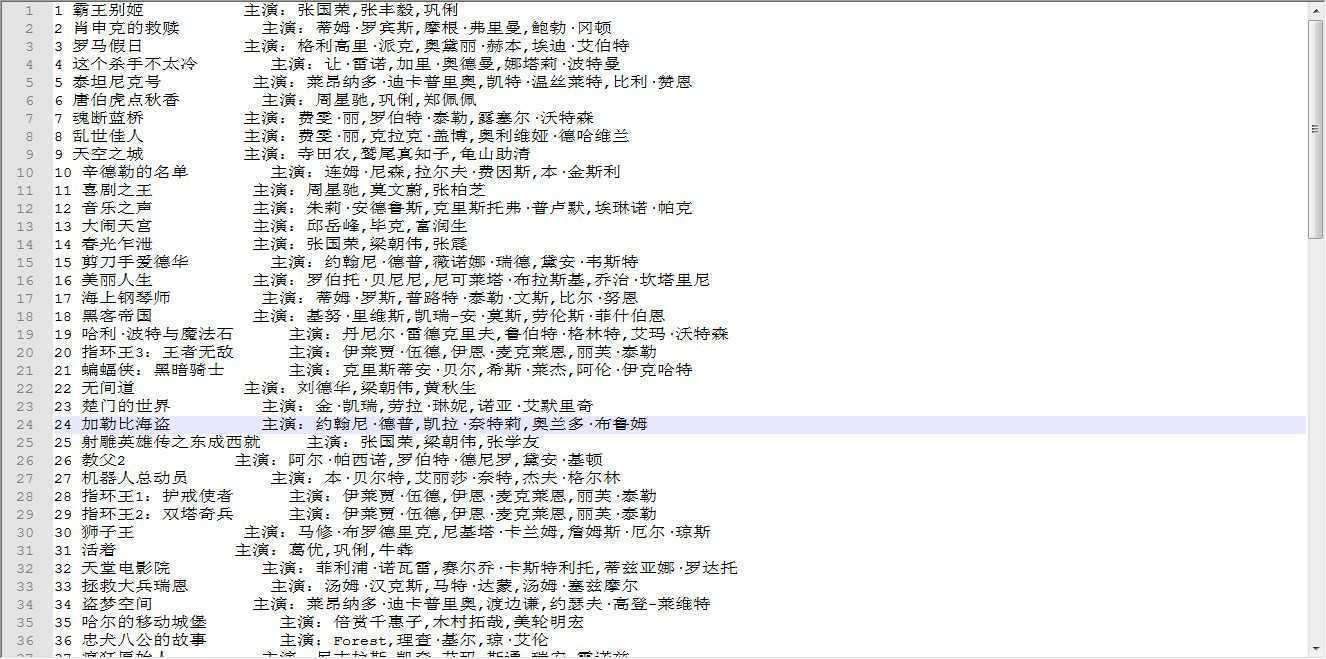
控制台打印的排名如下:

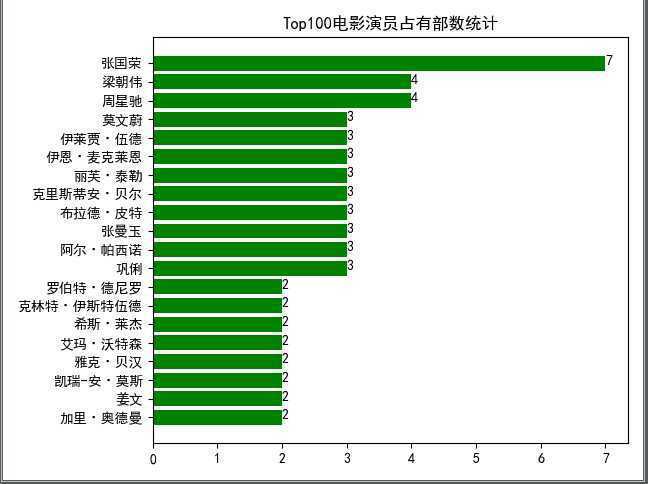
从结果可以看出,100部电影,张国荣一人就占了7部,排名第一。
从图片可以看出,演员排名其实不是很直观,最好是有一个图表的方式。python的matplotlib模块是一个数据可视化模块,拥有很强的功能。不过目前我只是初步学习基础模块,并没有深入了解matplotlib,所以只能从网上找到小demo,简单了解用法之后加以改造。具体用法和原理,待后续深入学习。
声明一个draw.py文件
import matplotlib.pyplot as plt
import numpy as np
class NameCount():
# 此函数用于垂直条形图
def show_name_bard(self, name_list_sort, name_list_count):
plt.rcdefaults()
fig, ax = plt.subplots()
y_pos = np.arange(len(name_list_sort))
ax.barh(y_pos, name_list_count, align='center',
color='green', ecolor='black')
plt.rcParams['font.sans-serif'] = ['SimHei']
ax.set_yticks(y_pos)
ax.set_yticklabels(name_list_sort)
ax.invert_yaxis() # labels read top-to-bottom
# ax.set_xlabel('')
ax.set_title('Top100电影演员占有部数统计')
# 在图画上显示数字
for x, y in enumerate(name_list_count):
plt.text(y, x + 0.1, '%s' % y)
plt.show()
def getNameTimesSort(self, name_list):
name_list.sort(key=lambda k: k[1], reverse=True)
# 按出现次数排序后的人名列表
name_list_sort = []
# 按出现次数排序后的人名次数列表,取前20名
name_list_count = []
for k, v in name_list[0:20]:
name_list_sort.append(k)
name_list_count.append(v)
# 绘制条形图
self.show_name_bard(name_list_sort, name_list_count)然后在info_handle方法中引入getNameTimesSort方法,讲原先用于打印的排好序的name_count_list传入
# 画出垂直条形图
statistics = draw.NameCount()
statistics.getNameTimesSort(name_count_list)这样就可以生成图像,一目了然:
《python3网络爬虫开发实战》
标签:font board desktop read reverse cli int black for
原文地址:https://www.cnblogs.com/yozar/p/11457799.html