标签:数据类型 without lis stat 线程同步 运行 sharp 异步刷新 建立
一、Innodb体系架构
1.1、后台线程
后台任务主要负责刷新内存中的数据,保证缓冲池的数据是最近的数据,此外还将修改的数据刷新到文件磁盘,保证在数据库发生异常的情况下Innodb能恢复到正常的运行状态。
1、Master Thread
主要负责缓冲池的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲undo页的回收等。
2、IO Thread
主要负责IO请求的回调(call back)(有如下四种io线程)
write IO :innodb_write_io_threads=8
read IO :innodb_read_io_threads=8
insert buffer IO
log IO
查看:show engine innodb status\G (注意:该命令显示不是当前innodb的状态,而是过去一段时间的状态)
-------- I/O thread 0 state: waiting for completed aio requests (insert buffer thread) I/O thread 1 state: waiting for completed aio requests (log thread) I/O thread 2 state: waiting for completed aio requests (read thread) I/O thread 3 state: waiting for completed aio requests (read thread) I/O thread 4 state: waiting for completed aio requests (read thread) I/O thread 5 state: waiting for completed aio requests (read thread) I/O thread 6 state: waiting for completed aio requests (read thread) I/O thread 7 state: waiting for completed aio requests (read thread) I/O thread 8 state: waiting for completed aio requests (read thread) I/O thread 9 state: waiting for completed aio requests (read thread) I/O thread 10 state: waiting for completed aio requests (write thread) I/O thread 11 state: waiting for completed aio requests (write thread) I/O thread 12 state: waiting for completed aio requests (write thread) I/O thread 13 state: waiting for completed aio requests (write thread) I/O thread 14 state: waiting for completed aio requests (write thread) I/O thread 15 state: waiting for completed aio requests (write thread) I/O thread 16 state: waiting for completed aio requests (write thread) I/O thread 17 state: waiting for completed aio requests (write thread)
从上可以看到IO thread 0为insert buffer thread,IO thread 1 为log thread,之后的就是根据innodb_write_io_threads=8,innodb_read_io_threads=8设置的读写线程,并且读线程的ID总是小于写线程的ID。
3、Purge Thread
用来回收已经使用并分配的undo页(需要随机读取undo页)
innodb_purge_threads=2 #值相对大点可提高undo页的回收速度,也能更进一步利用磁盘的随机读写性能
查看值的设置:show variables like ‘innodb_purge_threads‘\G;
4、Page Cleaner Thread
将之前版本脏页的刷新操作都放入单独的线程中完成,减轻master thread的负担和用户查询的阻塞
1.2、内存
Innodb内存结构图
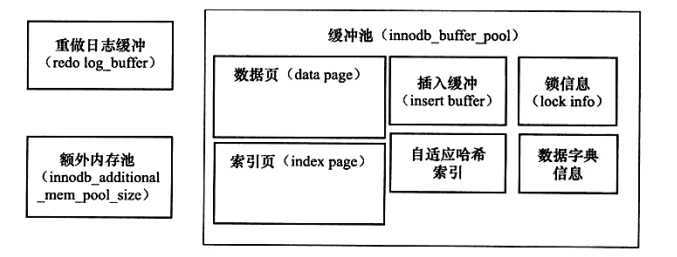
innodb内存数据对象
1、缓冲池
innodb基于磁盘存储,由于cpu和磁盘之间的速度差距太大,所以通过内存作为一个缓冲,所以缓冲是为了解决磁盘和cpu的速度上差距的问题,提高数据库性能。将磁盘读到的页存放在缓冲中,称为FIX在缓冲池中,从缓冲中读取数据,称为该页在缓冲池被命中。
数据读:先从缓冲池中读取,如果页被命中就返回,否则从磁盘读取
数据写:先修改缓冲池中页的数据,然后以一定的频率(checkpoint机制)刷新到磁盘,不是实时刷新
缓冲池的大小参数:innodb_buffer_pool_size=32G #该值直接影响数据库的整体性能
多个缓冲池实例:innodb_buffer_pool_instances=4 #减少数据内部资源竞争。
sql查看:select POOL_ID,POOL_SIZE,FREE_BUFFERS,DATABASE_PAGES from information_schema.INNODB_BUFFER_POOL_STATS;
查看:show engine innodb status\G
INDIVIDUAL BUFFER POOL INFO ---------------------- ---BUFFER POOL 0 #实例1 Buffer pool size 1548287 #页的个数 Buffer pool size, bytes 25367134208 Free buffers 1024 #Free List中页的数量 Database pages 1502522 #LRU List中页的数量 Old database pages 375610 Modified db pages 48677 Percent of dirty pages(LRU & free pages): 3.237 Max dirty pages percent: 50.000 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 422595788, not young 41434529403 #pages made young显示LRU中移动到前端次数,not young表示没能移动到前端次数 0.60 youngs/s, 0.00 non-youngs/s Pages read 2001192602, created 104217673, written 638270606 0.60 reads/s, 0.00 creates/s, 3.60 writes/s Buffer pool hit rate 999 / 1000, young-making rate 1 / 1000 not 0 / 1000 #缓冲命中率,越高越好,如果低于95%,则该考虑是否有扫描,数据备份等操作污染了LRU List Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 1502522, unzip_LRU len: 0 I/O sum[1744]:cur[25], unzip sum[0]:cur[0] ---BUFFER POOL 1 #实例2 Buffer pool size 1548287 Buffer pool size, bytes 25367134208 Free buffers 1024 Database pages 1502549
.........
从Innodb的内存对象图看,缓冲数据类型:索引页,数据页,undo页,插入缓冲(insert buffer),自适应哈希索引,数据字典信息等。缓冲池不仅仅只有缓存索引页和数据页,它们只是占缓冲池中很大一部分。
2、LRU List、Free List、Flush List
数据库中的缓冲池是通过LRU(Lastet Recent Used) 最近很少使用算法进行管理。原理:最频繁使用的页放在LRU列前端,不经常使用的放在LUR的后端。
innodb引擎中,缓冲池中的页默认大小16k,虽然使用了LRU管理,但是在其中间加入了midpoint点(可以理解为把LRU列分为两段),一段为频繁使用,一段为很少使用,通过参数:innodb_old_blocks_pct=30,(意思为30%)控制比例。
加midpoint的优点:像扫描类的操作很容易将其他常用的页刷新出去,导致效率下降,midpoint可以解决这个问题。另外innodb_old_blocks_time控制列进去LRU进去热端的时间,这样可以保证热端的页的访问频率比较高。
LRU列是用来管理已读取到的页,当服务刚启动的时候,LRU为空,页都在Free列中,从Free中读取空闲页到LRU中,并删除Free中的页LRU中页从old到new端称为page made young,因innodb_old_blocks_time而没能从old到new端称为page not made young。查看:show engine innodb status\G(如上代码框中)
Flush列管理脏页(modified db pages),管理将页刷回磁盘,与LRU不影响,LRU用于管理缓冲池中可用的列
3、重做日志缓冲
innodb先将重做日志信息存放在这个缓冲中,然后按照一定的频率将其刷新到重做日志文件中
参数控制:innodb_log_buffer_size=8M (一般不需要很大,因为每秒会刷缓存到日志文件中)
重做日志缓冲刷新条件:
1.master Thread每一秒将缓冲刷入重做日志文件中
2.每个事务提交会将重做日志缓冲刷入重做日志文件
3.当重做日志缓冲剩下不到1/2时,会刷入重做日志文件
4、额外内存池
在innodb的引擎中,对内存的管理是通过一种为内存堆的方式进行管理,对一些数据的内存分配时,需要从额外的内存池中申请,如果额外内存池资源不够,就会从缓冲池中申请。
二、checkpoint
为了防止数据丢失:采用Write Ahead Log策略,提交事务时,先写重做日志,然后再修改页,就算在从缓冲池中刷新到磁盘过程中宕机,也可以从日志中恢复数据,防止数据丢失。
checkpoint技术特点:
1.缩短数据库的恢复时间(把日志生成数据到磁盘,直接加载磁盘数据,而不是通过日志重新恢复数据)
2.缓冲池不够用,将脏页写入磁盘
3.重做日志不可用,刷新脏页
checkpoint种类:
sharp checkpoint:发生在数据库关闭时将所有数据刷回磁盘(默认工作方式,innodb_fast_shutdown=1)
fuzzy checkpoint:只刷新部分脏页,而不是所有脏页到磁盘
fuzzy checkpoint发生条件:
master Thread checkpoint :主线程定时checkpoint
FLUSH_LRU_LIST checkpoint :LRU列不够存
Async/Sync Flush checkpoint :重做日志不可用,保证重做日志的循环利用
Dirty page too much checkpoint :脏页数量过多 innodb_max_dirty_pages_pct
三、Innodb关键特性
3.1 插入缓冲
insert buffer
聚集索引:也叫聚簇索引。数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
非聚集索引(辅助索引):该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
innodb对于非聚集索引的插入和更新操作,不是每一次插入到索引页中,而是先判断非聚集索引页是否在缓冲池中,如在,则直接插入,若不在,则先放入一个insert buffer中,然后再以一定的频率和情况进行insert buffer 和辅助索引页子节点的合并,这是通常能将多个插入操作合并成一个操作。这就大大提高了非聚集索引的效率
insert buffer发生必须满足两个条件:
1、所以必须是辅助索引
2、索引不是唯一的
存在的问题:当遇到大量的写入时,插入缓冲会占用太多的缓冲池内存,最大默认为1/2,
change buffer(插入缓冲升级版)
这个版本的的插入缓冲可以对DML操作--insert、delete、update进行缓冲,分别是insert buffer, delete buffer , purge buffer
innodb_change_buffer_max_size #该参数用来控制changer buffer的最大值,默认为25,也就是1/4,最大可为50
查看:show engine innodb status\G
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 948959, seg size 948961, 870033008 merges merged operations: insert 4536471183, delete mark 24386361779, delete 4019249458 discarded operations: insert 11214, delete mark 0, delete 0 449.91 hash searches/s, 426.91 non-hash searches/s
如上包括了merged operation和discarded operation。其中的数字表示次数,insert表示insert buffer,delete mark 表示delete buffer,delete 表示purge buffer。discarded opreation的操作表示merge时删除了,无需再合并到索引中。
change insert底层实现:B+tree (不详述)
merge insert buffer发生情况:
1.辅助索引页被读取到缓冲池时
2.master thread
3.辅助索引页无可用空间
3.2 两次写
InnoDB的Page Size一般是16KB,其数据校验也是针对这16KB来计算的,将数据写入到磁盘是以Page为单位进行操作的。我们知道,由于文件系统对一次大数据页(例如InnoDB的16KB)大多数情况下不是原子操作,这意味着如果服务器宕机了,可能只做了部分写入。16K的数据,写入4K时,发生了系统断电/os crash ,只有一部分写是成功的,这种情况下就是partial page write问题。
double write基本思路:就是在写数据页之前,先把这个数据页写到一块独立的物理文件位置(ibdata),然后再写到数据页。这样在宕机重启时,如果出现数据页损坏,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做。
double write组成:一部分是InnoDB内存中的double write buffer,大小为2M,另一部分是物理磁盘上ibdata系统表空间中大小为2MB,共128个连续的Page,既2个分区。其中120个用于批量写脏,另外8个用于Single Page Flush。做区分的原因是批量刷脏是后台线程做的,不影响前台线程。而Single page flush是用户线程发起的,需要尽快的刷脏并替换出一个空闲页出来。
double write工作流程:当一系列机制(main函数触发、checkpoint等)触发数据缓冲池中的脏页进行刷新到data file的时候,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的double write buffer,之后通过double write buffer再分两次、每次1MB顺序写入共享表空间的物理磁盘上(ibdata)。然后马上调用fsync函数,同步脏页进磁盘上。由于在这个过程中,double write页的存储时连续的,因此写入磁盘为顺序写,性能很高;完成double write后,再将脏页写入实际的各个表空间文件,这时写入就是离散的了。如图所示:
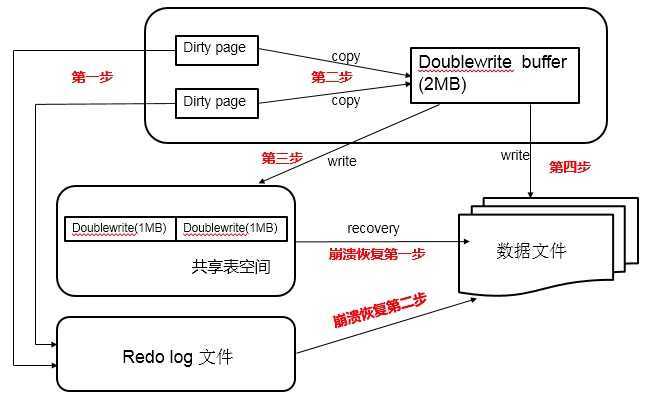
查看:show GLOBAL STATUS like ‘%innodb_dblwr%‘

Innodb_dblwr_pages_written :5166155016 #表示double write一共写了页的数量,可以用来数据的写入量
Innodb_dblwr_writes :87244238 #实际写入的次数
skip_innodb_doublewrite:用来禁用double write
3.3 自适应哈希索引
定义:Innodb存储引擎会监控对表上各个索引页的查询,如果觉得建立哈希索引能够带来性能的提升,则建立哈希索引,称为自适应哈希索引(AHI)。
AHI是通过B+树构造而来,因此建立的速度很快,而且不需要对整个表构建哈希索引,Innodb会自动根据访问的频率和模式来自动地为某些热点建立哈希索引。
AHI要求:对一个页的访问模式必须是一样的,访问模式一样,指的是查询条件一样。
注意:AHI只用来搜索等值查询,例如where a=1
查看:show engine innodb status\G
INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 948959, seg size 948961, 870033008 merges merged operations: insert 4536471183, delete mark 24386361779, delete 4019249458 discarded operations: insert 11214, delete mark 0, delete 0 449.91 hash searches/s, 426.91 non-hash searches/s --- LOG
3.4 异步IO
异步IO(AIO):允许用户在发出一个IO请求后立即发送第二个IO请求,当全部的IO请求发送完毕后,等待所有的IO操作的完成。
优势:可以合并多个IO,提高IPIOPS性能
控制参数:innodb_use_native_aio
3.5 刷新邻接页
工作原理:当刷新一个脏页时,Innodb会检测到该页所在区的所有页,如果是脏页,则一起刷新
四、Innodb启动与关闭
4.1启动
innobase_start_or_create_for_mysql函数用来控制innodb的启动,基本启动流程如下:
1、初始化:
同步控制系统,内存管理系统,日志恢复变量,后台线程同步控制系统
根据innodb_buffer_pool_size和innodb_buffer_pool_instances初始化Buffer pool
初始化日志系统,包括日志的写入,LSN的管理,检查点,日志刷盘以及日志恢复等
IO异步线程,创建innodb_read_io_threads+innodb_write_io_threads个IO线程
初始化日志恢复系统
2、打开或者创建系统数据文件(ibdata)
open_or_create_data_files函数控制,如果存在,则读取信息并打开,如果不存在,则创建,相当于初始化一个新的数据库实例。
。。。。。。
4.2关闭
参考:《msyql技术内幕,Innodb存储引擎》
标签:数据类型 without lis stat 线程同步 运行 sharp 异步刷新 建立
原文地址:https://www.cnblogs.com/zsql/p/11461342.html