标签:json 领域 first div evo 效率 生态 问题 post
一、Python的历史
1. 1989年圣诞节:Guido von Rossum开始写Python语言的编译器。
2. 1991年2月:第一个Python编译器(同时也是解释器)诞生,它是用C语言实现的(后面又出现了Java和C#实现的版本Jython和IronPython,以及PyPy、Brython、Pyston等其他实现),可以调用C语言的库函数。在最早的版本中,Python已经提供了对“类”,“函数”,“异常处理”等构造块的支持,同时提供了“列表”和“字典”等核心数据类型,同时支持以模块为基础的拓展系统。
3. 1994年1月:Python 1.0正式发布。
4. 2000年10月16日:Python 2.0发布,增加了实现完整的[垃圾回收]
5. 2008年12月3日:Python 3.0发布,它并不完全兼容之前的Python代码,不过因为目前还有不少公司在项目和运维中使用Python 2.x版本,所以Python 3.x的很多新特性后来也被移植到Python 2.6/2.7版本中。
目前我们使用的Python 3.7.x的版本是在2018年发布的,Python的版本号分为三段,形如A.B.C。其中A表示大版本号,一般当整体重写,或出现不向后兼容的改变时,增加A;B表示功能更新,出现新功能时增加B;C表示小的改动(如修复了某个Bug),只要有修改就增加C。如果对Python的历史感兴趣,可以查看一篇名为[《Python简史》
二、Python的优缺点
Python的优点很多,简单的可以总结为以下几点。
1. 简单和明确,做一件事只有一种方法。
2. 学习曲线低,跟其他很多语言相比,Python更容易上手。
3. 开放源代码,拥有强大的社区和生态圈。
4. 解释型语言,天生具有平台可移植性。
5. 支持两种主流的编程范式(面向对象编程和函数式编程)都提供了支持。
6. 可扩展性和可嵌入性,可以调用C/C++代码,也可以在C/C++中调用Python。
7. 代码规范程度高,可读性强,适合有代码洁癖和强迫症的人群。
Python的缺点主要集中在以下几点。
1. 执行效率稍低,因此计算密集型任务可以由C/C++编写。
2. 代码无法加密,但是现在的公司很多都不是卖软件而是卖服务,这个问题会被淡化。
3. 在开发时可以选择的框架太多(如Web框架就有100多个),有选择的地方就有错误。
三、Python的应用领域
目前Python在云基础设施、DevOps、网络爬虫开发、数据分析挖掘、机器学习等领域都有着广泛的应用,因此也产生了Web后端开发、数据接口开发、自动化运维、自动化测试、科学计算和可视化、数据分析、量化交易、机器人开发、图像识别和处理等一系列的职位。
四、搭建编程环境
python3.7.0搭建成功:

五、拉勾网对Python相关的职位要求,薪资待遇。
此处,我使用了简单爬虫来进行爬取拉勾网的数据
源代码如下:
import requests import json header = { ‘Accept‘: ‘application/json, text/javascript, */*; q=0.01‘, ‘Referer‘: ‘https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB/p-city_184?&cl=false&fromSearch=true&labelWords=sug&suginput=python‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘ } data = { ‘first‘: ‘true‘, ‘pn‘: ‘1‘, ‘kd‘: ‘python‘ } url1 = ‘https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=‘ #主url
url = ‘https://www.lagou.com/jobs/positionAjax.json?city=%E6%AD%A6%E6%B1%89&needAddtionalResult=false‘ #ajax请求 s = requests.Session() #因为需要post和相关cookies,所以得创建session来帮忙获取cookies s.get(url = url1 ,headers =header) cookie = s.cookies respon = s.post(url = url, headers = header, data = data, cookies = cookie) res_json = json.loads(respon.text) ret = res_json[‘content‘][‘positionResult‘][‘result‘] for i in ret: salary = i[‘salary‘] name = i[‘positionName‘] print(name,salary)
输出结果如下:
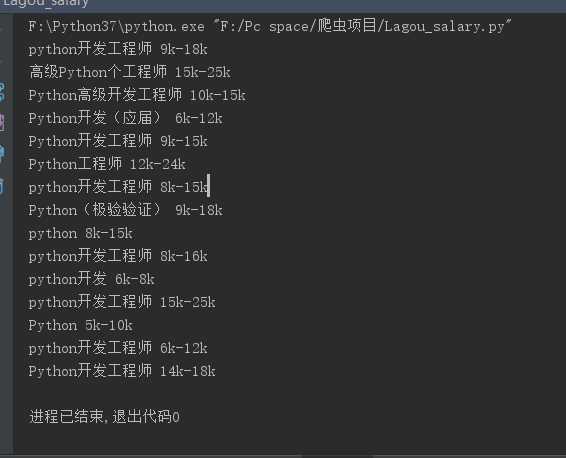
在爬取过程中,因为在使用requests模拟浏览器访问数据的时候,出现了访问频繁的问题。
拉钩的网页加载的时候有一个url专门返回除了招聘信息以外的其它东西,加载招聘信息的时候会产生另外一个ajax请求,请求返回的正是我们想要的内容,只需要在先发送主请求,之后用
requests.Session()建立Session,建立完成session之后通过session来获取cookie,拿到cookie就可以直接用了。该方法的缺点在于每次的获取,都相当于重新打开一次浏览器。
最后通过一系列的取key来获取我们想要的值:Python职位+职位对应的薪水
最后,大家一起努力学习Python吧~
标签:json 领域 first div evo 效率 生态 问题 post
原文地址:https://www.cnblogs.com/lesliechan/p/11470342.html