标签:space oid 节点 程序 array 删除线 flavor crc jpg
我主要参考的文章是这一篇:
What is RCU, Fundamentally??lwn.net
当然,英文看起来还是比较慢的,我这里也并非纯粹地翻译这篇文章,只是作一个参考,同时加上个人的一些思考,希望能够帮助大家更好的理解RCU机制。
很明显,RCU是一种同步机制,是在2002年引入在Linux内核中的。大家应该都知道内核同步机制中的像各种锁机制、信号量、内存屏障啥的,但为啥会引入一个叫读复制更新这么个同步机制呢?它有啥优点,或者说它的应用场景是什么?
考虑一个问题,我们知道,在路由器上,会有很多线程去查找路由表数据,但是更新路由表数据的情况却不多。像这种情况下我们如何做多同步?上面说的几种同步机制都不是很好的选择,这时RCU就派上用场了,具体原因下文会解释。所以,RCU主要应用在那种,读线程多,而写线程唯一的情况,同时需要保证数据一致性。搞明白了这个道理,我们来分析一下RCU。
在RCU的实现过程中,我们主要解决以下问题:
1,在读取过程中,另外一个线程删除了一个节点。删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作。RCU中把这个过程称为宽限期(Grace period)。
2,在读取过程中,另外一个线程插入了一个新节点,而读线程读到了这个节点,那么需要保证读到的这个节点是完整的。这里涉及到了发布-订阅机制(Publish-Subscribe Mechanism)。
3, 保证读取链表的完整性。新增或者删除一个节点,不至于导致遍历一个链表从中间断开。但是RCU并不保证一定能读到新增的节点或者不读到要被删除的节点。
发布-订阅机制(Publish-Subscribe Mechanism)。
RCU的一个最关键的特性在于,它能够保证数据能安全的被读取(原文用的是scan这个词,我把它翻译成读取貌似比较好?),即便数据被并发地更新。为了能够并发地插入数据,RCU使用了发布-订阅机制。举个例子,全局指针gp,指向一段新的已分配的空间并初始化,如下:
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1; // 1
p->b = 2; // 2
p->c = 3; // 3
gp = p; // 4问题的关键再于,没有规定编译器在编译1,2,3,4步骤时一定需要按照对应的顺序来赋值,事实上,对于多CPU的机器来说,经常可能gp = p这个操作会发生在1,2或者3步之前,也就是说p还没被初始化完全就被赋值给了gp了,这种情况肯定不是我们想要的结果。
大家想必觉得内存屏障能够达到赋值顺序执行,但是相对来说内存屏障这操作是比较麻烦的事(原文用的是notoriously这个词,众所周知地、恶名昭彰地,声名狼藉地;看来作者对内存屏障是相当不感冒啊)。因此,我们压缩一下,提供一个发布语义的原生接口,rcu_assign_ pointer() 。变成下面这种形式:
p->a = 1; // 1
p->b = 2; // 2
p->c = 3; // 3
rcu_assign_pointer(gp, p);这个接口能够保证从编译器和CPU层面上gp被赋值前,p指向的字段能够赋值完成。我们看看这个接口函数的具体实现(Linux kernel 4.11.4):
#define rcu_assign_pointer(p, v) ({ uintptr_t _r_a_p__v = (uintptr_t)(v); if (__builtin_constant_p(v) && (_r_a_p__v) == (uintptr_t)NULL) WRITE_ONCE((p), (typeof(p))(_r_a_p__v)); else smp_store_release(&p, RCU_INITIALIZER((typeof(p))_r_a_p__v)); _r_a_p__v; })看起来比较复杂,但其实是做了两件事:一、在必要时插入一个内存屏障;二、关闭编译器在赋值时的非顺序编译优化,保证赋值时已经初始化了。
但是,这样还不够,我们还需要在读的时候保证其顺序性。不信请看下面这个例子:
p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}看起来,这段代码没有啥问题,但是在有些机器(文中举例:DEC Alpha CPU机器)上或者值预测编译优化的情况下,fp->a,fp->b,fp->c会在p = gp还没执行的时候就预先判断运行,当他和foo_update同时运行的时候,可能导致传入dosomething 的一部分属于旧的gbl_ foo,而另外的属于新的。这样导致运行结果的错误。
为了避免该类问题,RCU提供了原生接口rcu_dereference()来解决这个问题,所以上面的代码写成下面的形式就可以了:
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();从名字来看是解引用,可以看作是对特定指针订阅一个给定值,也就是订阅机制。我们可以看看它的具体实现:
#define rcu_dereference(p) rcu_dereference_check(p, 0)
#define rcu_dereference_check(p, c) __rcu_dereference_check((p), (c) || rcu_read_lock_held(), __rcu)
#define __rcu_dereference_check(p, c, space) ({ /* Dependency order vs. p above. */ typeof(*p) *________p1 = (typeof(*p) *__force)lockless_dereference(p); RCU_LOCKDEP_WARN(!(c), "suspicious rcu_dereference_check() usage"); rcu_dereference_sparse(p, space); ((typeof(*p) __force __kernel *)(________p1)); })
#ifdef __CHECKER__
#define rcu_dereference_sparse(p, space) ((void)(((typeof(*p) space *)p) == p))
#else /* #ifdef __CHECKER__ */
#define rcu_dereference_sparse(p, space)
#endif /* #else #ifdef __CHECKER__ */
#define lockless_dereference(p) ({ typeof(p) _________p1 = READ_ONCE(p); typeof(*(p)) *___typecheck_p __maybe_unused; smp_read_barrier_depends(); /* Dependency order vs. p above. */ (_________p1); })实现比较搞,最重要的还是smp_read_barrier_depends()这个函数,其实也就是加了优化屏障。
好了,现在我们就知道了,rcu_assign_pointer是发布,而rcu_dereference是订阅,合起来就是发布订阅机制。虽然,这两个函数理论上可以用在所有的可信的由RCU保护数据结构当中,但在实践中我们需要更为high-level的数据结构。所以,RCU还提供了一些更高级的API接口,如下表格所示:

具体的实现原理,我这里就不展开细讲了,大家有兴趣可以去看源码。
RCU中的宽限期
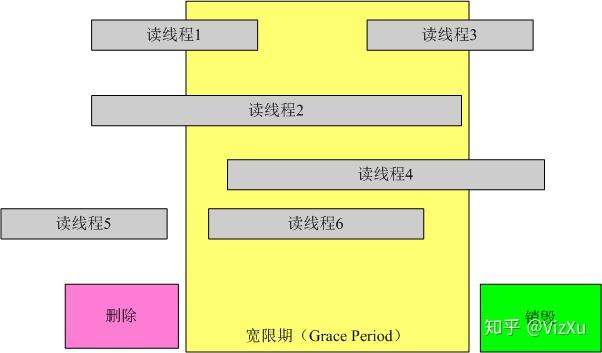
在RCU中,数据的删除和销毁需要一定的宽限期,主要是因为需要等待读线程的完成。如图所示:
我们再看看一个例子:
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo *gbl_foo;
void foo_read (void)
{
foo *fp = gbl_foo; // 如果发生了进程切换
if ( fp != NULL )
dosomething(fp->a, fp->b , fp->c );
}
void foo_update( foo* new_fp )
{
spin_lock(&foo_mutex);
foo *old_fp = gbl_foo;
gbl_foo = new_fp;
spin_unlock(&foo_mutex);
kfee(old_fp);
}有两个线程同时运行 foo_ read和foo_update的时候,当foo_ read执行完赋值操作后,线程发生切换;此时另一个线程开始执行foo_update并执行完成。当foo_ read运行的进程切换回来后,运行dosomething 的时候,fp已经被删除,这将对系统造成危害。
所以,写线程(删除和销毁数据的线程)在删除数据后不能立马销毁这个数据,一定要等待所有在宽限期开始前已经开始的读线程结束,才可以进行销毁操作。这样做的原因是这些线程有可能读到了要删除的元素。图中的宽限期必须等待1和2结束;而读线程5在宽限期开始前已经结束,不需要考虑;而3,4,6也不需要考虑,因为在宽限期结束后开始后的线程不可能读到已删除的元素。
因此,RCU提供了一个接口函数synchronize_rcu()来同步在宽限期的读线程。只有宽限期中没有读线程了,这个函数才返回,也就是说这是一个阻塞函数。所以foo_update需要写成下面的形式才是安全的。
void foo_update( foo* new_fp )
{
spin_lock(&foo_mutex);
foo *old_fp = gbl_foo;
gbl_foo = new_fp;
spin_unlock(&foo_mutex);
synchronize_rcu();
kfee(old_fp);
}我们来看看它的具体实现:
static inline void synchronize_rcu(void)
{
synchronize_sched();
}
void synchronize_sched(void)
{
RCU_LOCKDEP_WARN(lock_is_held(&rcu_bh_lock_map) ||
lock_is_held(&rcu_lock_map) ||
lock_is_held(&rcu_sched_lock_map),
"Illegal synchronize_sched() in RCU-sched read-side critical section");
if (rcu_blocking_is_gp())
return;
if (rcu_gp_is_expedited())
synchronize_sched_expedited();
else
wait_rcu_gp(call_rcu_sched);
}
...实现比较复杂,不过最重要的还是下面这个函数实现:
void __wait_rcu_gp(bool checktiny, int n, call_rcu_func_t *crcu_array,
struct rcu_synchronize *rs_array)
{
int i;
/* Initialize and register callbacks for each flavor specified. */
for (i = 0; i < n; i++) {
if (checktiny &&
(crcu_array[i] == call_rcu ||
crcu_array[i] == call_rcu_bh)) {
might_sleep();
continue;
}
init_rcu_head_on_stack(&rs_array[i].head);
init_completion(&rs_array[i].completion);
(crcu_array[i])(&rs_array[i].head, wakeme_after_rcu);
}
/* Wait for all callbacks to be invoked. */
for (i = 0; i < n; i++) {
if (checktiny &&
(crcu_array[i] == call_rcu ||
crcu_array[i] == call_rcu_bh))
continue;
wait_for_completion(&rs_array[i].completion);
destroy_rcu_head_on_stack(&rs_array[i].head);
}
}具体来说就是需要等待各线程的完成,然后返回。
RCU的数据完整性保证
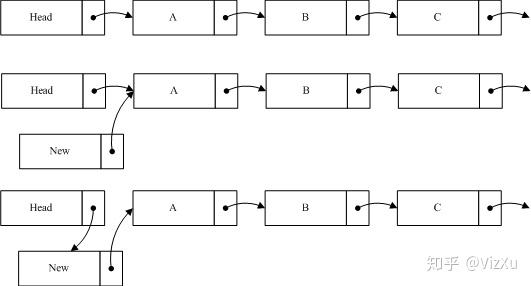
如图我们在原list中加入一个节点new到A之前,所要做的第一步是将new的指针指向A节点,第二步才是将Head的指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步的时候,读线程如果读到new节点,也可以继续遍历链表。如果把这个过程反过来,第一步head指向new,而这时一个线程读到new,由于new的指针指向的是Null,这样将导致读线程无法读取到A,B等后续节点。从上面的分析,我们可以知道RCU并不能保证在插入数据时读线程一定能够读到新数据。
2. 数据删除时,读取数据的保证,考虑下面的情况:
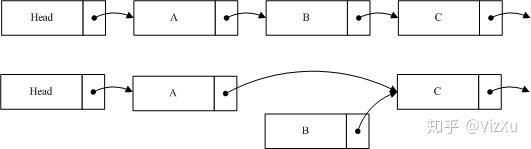
我们希望删除B,这时候要做的就是将A的指针指向C,保持B的指针,然后删除程序将进入宽限期检测。由于B的内容并没有变更,读到B的线程仍然可以继续读取B的后续节点。B不能立即销毁,它必须等待宽限期结束后,才能进行相应销毁操作。由于A的节点已经指向了C,当宽限期开始之后所有的后续读操作通过A找到的是C,而B已经隐藏了,后续的读线程都不会读到它。这样就确保宽限期过后,删除B并不对系统造成影响。
3. 数据更新时,读取数据的保证,考虑下面的情况:
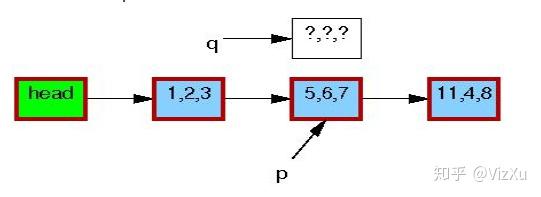 图1
图1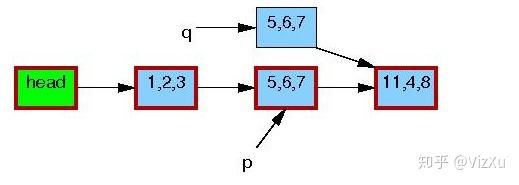 图2
图2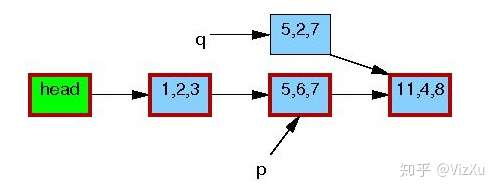 图3
图3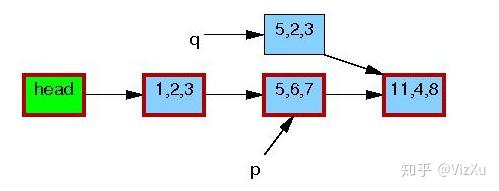 图4
图4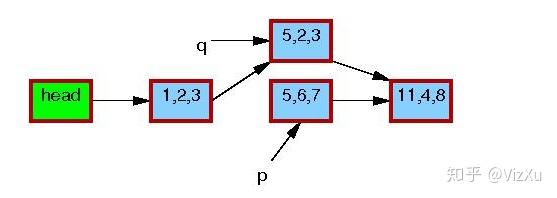 图5
图5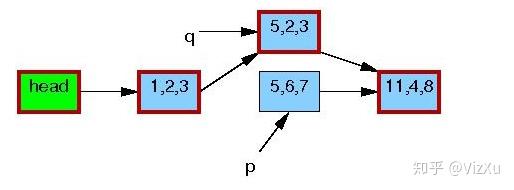 图6
图6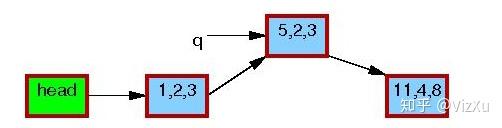 图7
图7
从图1到图7,我们可以清晰地看到RCU在更新数据时的具体操作。首先是从链表中复制某个数据,然后更新这个数据,再删除原本数据,最后让前节点指向新数据。在删除旧数据时,遵从宽限期检测,即上面说的第2点。
总结:
标签:space oid 节点 程序 array 删除线 flavor crc jpg
原文地址:https://www.cnblogs.com/sunsky303/p/11475137.html