标签:第一个 select 行合并 ali 定义变量 grid 功能 stat head
请先安装好R和RStudio
如果不干别的,控制台就是一个内置计算器
2 * 3 #=> 6 sqrt(36) #=> 6, square root log10(100) #=> 2, log base 10 10 / 3 #=> 3.3, 10 by 3 10 %/% 3 #=> 3, quotient of 10 by 3 10 %% 3 #=> 1, remainder of 10 by 3 余数
分配符
a <- 10 # assign 10 to ‘a‘ a = 10 # same as above 10 -> a # assign 10 to ‘a‘ 10 = a # Wrong!. This will try to assign `a` to 10.类
类或者数据类型
R语言基于变量被赋予的值的属性自行决定变量类型,而非刻意定义变量类型
![]()
更改变量类型

R语言中变量类型有无穷个,因为可以自由定义新的类,当然,一些常用的类有以下:
变量类型
R语言包及下载
R是一种开源语言,有很多包,实现不同的功能
install.packages("car") # install car package 下载离你所在地方最近的CRAN镜像的包
调用包之前,需要初始化
library(car) # initialize the pkg ‘car‘ 初始化 require(car) # another way to initialize 初始化 library() # see list of all installed packages 列出所有以及下载的包 library(help=car) # see info about ‘car‘ pkg 关于包的信息
获得帮助
help(merge) # get help page for ‘merge‘ ?merge # lookup ‘merge‘ from installed pkgs 从以及下载的包中查找 ??merge # vague search 模糊查询 example(merge) # show code examples 展示代码案例
工作目录
getwd() # gets the working directory 获取当前目录 setwd(dirname) # set the working directory to dir name 设置工作目录 名称只能用/或者\\分割
导入导出数据
R语言最常见最方便导入的数据格式是csv文件,也有其他包可以导入xlsx、数据库文件
myData <- read.table("c:/myInputData.txt", header = FALSE, sep="|", colClasses=c("integer","character","numeric") # import "|" separated .txt file
myData <- read.csv("c:/myInputData.csv", header=FALSE) # import csv file 可以用colClass来人为设定数据框中每列的数据类型,这样处理效率更高,否则是自动识别数据类型的。
write.csv(rDataFrame, "c:/output.csv") # export
如何浏览 删除控制台的对象
当创建新的变量时,默认在全局环境获得存储空间
a <- 10 b <- 20 ls() # list objects in global env 列出全局环境中所有对象 rm(a) # delete the object ‘a‘ rm(list = ls()) # caution: delete all objects in .GlobalEnv 删除全局环境中所有对象 gc() # free system memory 释放系统内存
也可以创建新的环境来存储变量,可以把环境想象成一个包含对象(变量)的容器,最外面的主要环境就是全局环境,而环境容器本身也是对象,所以说可以在全局环境中创建很多个新的环境对象,只是说如果想进入新创建的环境,必须明确告诉R你想看哪一个子环境。
rm(list=ls()) # remove all objects in work space
env1 <- new.env() # create a new environment
assign("a", 3, envir = env1) # store a=3 inside env1
ls() # returns objects in .GlobalEnv
ls(env1) # returns objects in env1
get(‘a‘, envir=env1) # retrieve value from env1
创建向量
使用函数 c(). 创建向量,向量中所有元素类型必须一致,如果不一致,会自动转换为统一类型元素
vec1 <- c(10, 20, 15, 40) # numeric vector
vec2 <- c("a", "b", "c", NA) # character vector
vec3 <- c(TRUE, FALSE, TRUE, TRUE) # logical vector
vec4 <- gl(4, 1, 4, label = c("l1", "l2", "l3", "l4")) # factor with 4 levels
length(vec1) # 4
print(vec1[1]) # 10 从1开始索引
print(vec1[1:3]) # 10, 20, 15
尽管可以随意增加向量中的元素,但是初始化向量的长度仍然很有必要,因为这样可以节约运行时间,只需要往索引的位置填补新元素,特别是当数据量很大的时候,如下所示
numericVector <- numeric(100) # length 100 elements
对向量进行操作
切片
logic1 <- vec1 < 15 # create a logical vector, TRUE if value < 15 vec1[logic1] # elements in TRUE positions will be included in subset 逻辑值为真的元素 vec1[1:2] # returns elements in 1 & 2 positions. vec1[c(1,3)] # returns elements in 1 & 3 positions 位置1 3处元素
排序
sort(vec1) # ascending sort 升序 sort(vec1, decreasing = TRUE) # Descending sort 降序
或者
vec1[order(vec1)] # ascending sort vec1[rev(order(vec1))] # descending sort
自定义向量排列
seq(1, 10, by = 2) # diff between adj elements is 2 相邻元素差为2 seq(1, 10, length=25) # length of the vector is 25 向量长度是25 rep(1, 5) # repeat 1, five times. 重复1 五次 rep(1:3, 5) # repeat 1:3, 5 times rep(1:3, each=5) # repeat 1 to 3, each 5 times.
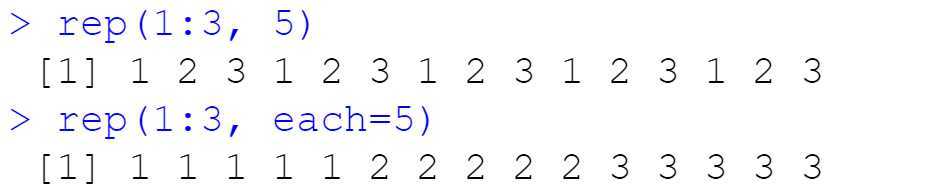
删除缺失值
vec2 <- c("a", "b", "c", NA) # character vector
is.na(vec2) # missing TRUE 返回一个缺失值处为真的逻辑向量
!is.na(vec2) # missing FALSE
vec2[!is.na(vec2)] # return non missing values from vec2 返回非缺失值
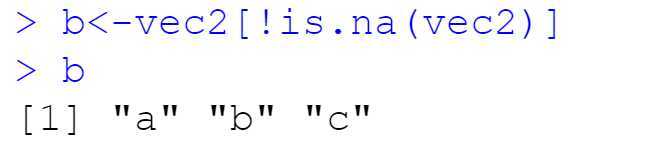
抽样
sample(x, size, replace = FALSE, prob = NULL)
set.seed(100) # optional. set it to get same random samples. 设置随机数
sample(vec1) # sample all elements randomly 把所有元素打乱顺序
sample(vec1, 3) # sample 3 elem without replacement 抽取三个元素 3是抽样后得到的样本数量
sample(vec1, 10, replace=T) # sample with replacement 意思是抽取的元素可以相同
#对数据框抽取
data=1:10
#抽取列
sample(x=data,size=1,replace=T)
#抽取行
data[sample(nrow(data),2,replace=F),]
#按比例抽取
set.seed(1234)
#按7:3的比例产生了1和2
index <- sample(x = 2,size = nrow(data),replace=TRUE,prob = c(0.7,0.3))
traindata <- data[index == 1,]
testdata <- data[index == 2,]
#按照某个字段分层抽取
result<-data.frame()
data<-data.frame(a=c(1,2,3,4,6,7,8,5,11,12),b=c(2,3,4,5,65,4,6,6,8,9),s=c(‘A‘,‘B‘,‘A‘,‘A‘,‘B‘,‘A‘,‘B‘,‘A‘,‘B‘,‘B‘))
subdata<-split(data,data$s) #按照s变量中的类型分类成列表
for(i in 1:length(subdata)){
sub<-subdata[[i]]
x<-sub[sample(nrow(sub),2,replace=F),] #每个列表元素中抽取两行
result<-rbind(result,x) #rbind函数 按照行叠加起来
}
result

数据框
数据框是一种很便于进行数据分析的数据对象,R读取csv文件时也是以数据框形式读取的,可用向量创建数据框,R语言也有很多内置的数据框格式数据集
myDf1 <- data.frame(vec1, vec2) # make data frame with 2 columns myDf2 <- data.frame(vec1, vec3, vec4) myDf3 < data.frame(vec1, vec2, vec3) library(datasets) # initialize library(help=datasets) # display the datasets #下面一些基本操作代码会经常用到 class(airquality) # get class sapply(airquality, class) # get class of all columns str(airquality) # structure summary(airquality) # summary of airquality head(airquality) # view the first 6 obs fix(airquality) # view spreadsheet like grid rownames(airquality) # row names colnames(airquality) # columns names nrow(airquality) # number of rows ncol(airquality) # number of columns # cbind rbind 为数据框添加行和列 cbind(myDf1, myDf2) # columns append DFs with same no. rows rbind(myDf1, myDf1) # row append DFs with same no. columns
对数据框进行切片操作
myDf1$vec1 # vec1 column myDf1[, 1] # df[row.num, col.num] myDf1[, c(1,2)] # columns 1 and 2 myDf1[c(1:5), c(2)] # first 5 rows in column 2 #也可以使用 subset() 和 which() 函数 which() 返回符合条件的行或列向量 subset(airquality, Day == 1, select = -Temp) # 选择 Day=1 剔除 ‘Temp‘ airquality[which(airquality$Day==1), -c(4)] # 作用同上
抽样
把数据分为训练数据集和验证数据集
set.seed(100) trainIndex <- sample(c(1:nrow(airquality)), size=nrow(airquality)*0.7, replace=F) # get test sample indices 0.7比例 灵活性 airquality[trainIndex, ] # training data airquality[-trainIndex, ] # test data
合并数据框
可以通过共同的列变量进行合并,merge()函数的不同参数可以实现内join,left join,right join以及完整join
merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...)
x: 第一个数据框
y: 第二个数据框
by,by.x,by.y:用于连接两个数据集的列,intersect(a,b)值向量a,b的交集,names(x)指提取数据集x的列名 by = intersect(names(x), names(y)) 是获取数据集x,y的列名后,提取其公共列名,作为两个数据集的连接列, 当有多个公共列时,需用下标指出公共列,如names(x)[1],指定x数据集的第1列作为公共列 也可以直接写为 by = ‘公共列名’ ,前提是两个数据集中都有该列名,并且大小写完全一致,R语言区分大小写
all, all.x, all.y: 指定合并类型的逻辑值。缺省为false,all=FALSE (仅返回匹配的行).
最后一组参数all, all.x, all.y需要进一步解释,决定合并类型。
内 join: 仅返回两数据框中匹配的数据框行,参数为:all=FALSE.
outer join: 返回两数据框中所有行, 参数为: all=TRUE.
Left outer join: 返回x数据框中所有行以及和y数据框中匹配的行,参数为: all.x=TRUE.
Right outer join: 返回y数据框中所有行以及和x数据框匹配的行,参数为: all.y=TRUE.
sort:by指定的列是否要排序.
suffixes:指定除by外相同列名的后缀.
incomparables:指定by中哪些单元不进行合并.
# 有多个公共列时,需指出使用哪一列作为连接列merge(x,y,by=intersect(names(x)[1],names(y)[1]))
# 当两个数据集连接列名称同时,直接用by.x,by.y 指定连接列merge(x,y,by.x =‘name‘,by.y =‘name‘)
# 当两个数据集均有连接列时,直接指定连接列的名称merge(x,y,by=‘name‘)
merge(x, y, all=TRUE, sort=TRUE)
# all = TRUE 表示选取x, y 数据集的所有行,sort = TRUE,表示按 by 列进行排序,默认升序
merge(x ,y,all.x=TRUE,sort=TRUE)
# 多个公共列 末指定连接列 ,左连接,设置 all.x = TRUE,结果只显示数据x的列及x在y数据集中没有的列
merge(x, y, by = ‘name‘,all.x = TRUE, sort = TRUE) # 多个公共列 指定连接列指, 左连接,设置 all.x = TRUE,结果只显示x所有names(x)[1]值
merge(x ,y ,by=‘name‘,all.y=TRUE,sort=TRUE)
# 多个公共列指定连接列# 左连接,设置all.y =TRUE,结果只显示y所有names(y) [1] 值的记录
paste 函数连接字符串,自定义字符串模式
paste("a", "b") # "a b"
paste0("a", "b") # concatenate without space, "ab"
paste("a", "b", sep="") # same as paste0
paste(c(1:4), c(5:8), sep="") # "15" "26" "37" "48"
paste(c(1:4), c(5:8), sep="", collapse="") # "15263748"
paste0(c("var"), c(1:5)) # "var1" "var2" "var3" "var4" "var5"
paste0(c("var", "pred"), c(1:3)) # "var1" "pred2" "var3"
paste0(c("var", "pred"), rep(1:3, each=2)) # "var1" "pred1" "var2" "pred2" "var3" "pred3
处理日期字符串
dateString <- "15/06/2014" myDate <- as.Date(dateString, format="%d/%m/%Y") class(myDate) # "Date" myPOSIXctDate <- as.POSIXct(myDate) # convert to POSIXct
![]()
查看R对象的内容
attributes(myPOSIXltDate) # best unclass(POSIXltDate) # works! names(myPOSIXltDate) # doesn‘t work on a POSIXlt object unlist(myPOSIXltDate) # works! object.size(myDate) # 216 bytes object.size(myPOSIXltDate) # 1816 bytes object.size(myPOSIXctDate) # 520 bytes
列联表
test <- c(1,2,3,2,1,1,5,6,4,5,1) test1 <- table(test) test1 test 1 2 3 4 5 6 #test中的元素 4 2 1 1 2 1 #各个元素出现的频率 #提取table()中的元素 names(test1) [1] "1" "2" "3" "4" "5" "6" #提取table()中的频率 as.numeric(test1) [1] 4 2 1 1 2 1 #3.进阶,提取table()中指定频率的数据,先用as.data.frame()转换 test2 <- as.data.frame(test1) test2 test Freq 1 1 4 2 2 2 3 3 1 4 4 1 5 5 2 6 6 1 test2[which(test2$Freq==1),] #提取出现频率为1的元素 test Freq 3 3 1 4 4 1 6 6 1
列表
列表是R语言中的对象,它包含不同类型的元素,比如 - 数字,字符串,向量和另一个列表等。一个列表还可以包含一个矩阵或一个函数作为它的元素。使用list()函数创建列表。
# Create a list containing strings, numbers, vectors and a logical values.
> list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
> print(list_data)
> print(list_data)
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1
命名列表元素
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
访问列表元素
print(list_data[1])#使用元素索引访问 print(list_data$A_Matrix)#使用名称访问
操控列表元素
list_data[3] <- "updated element"#更新
list_data[4] <- NULL #删除
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
转换列表为向量
# Convert the lists to vectors. v1 <- unlist(list1)
条件语句
if(checkConditionIfTrue) {
....statements..
....statements..
} else { # place the ‘else‘ in same line as ‘}‘
....statements..
....statements..
}
for(counterVar in c(1:n)){
.... statements..
}
tryCatch({1 <- 1; print("Lets create an error")}, # First block
error=function(err){print(err); print("Error Line")}, # Second Block(optional)
finally = {print("finally print this")})# Third Block(optional)
#=> [1] "Lets create an error"
#=> <simpleError in 1 <- 1: invalid(do_set) left-hand side to assignment>
#=> [1] "Error Line"
#=> [1] "finally print this"
参考:
http://r-statistics.co/R-Tutorial.html
https://www.jianshu.com/p/148a399b61d3
https://blog.csdn.net/neweastsun/article/details/79435271
https://blog.csdn.net/wlt9037/article/details/76570155
https://www.jianshu.com/p/9d52cd5aa6d9
标签:第一个 select 行合并 ali 定义变量 grid 功能 stat head
原文地址:https://www.cnblogs.com/icydengyw/p/11478109.html