标签:范围 存储 reverse object ade 分割 集合 方式 运算符优先级
最近花时间整理了一下以前学过的python基础知识,语言最多的是使用。
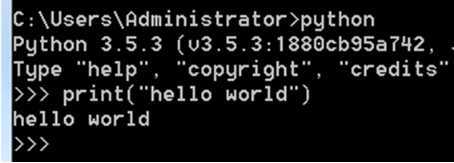
创建以.py结尾的python文件
在python文件中输入打印“hello world”的代码
运行编写完的python代码文件
格式:变量名 = 数值
module_name, package_name, ClassName, method_name, ExceptionName, function_name, GLOBAL_VAR_NAME, instance_var_name, function_parameter_name, local_var_name
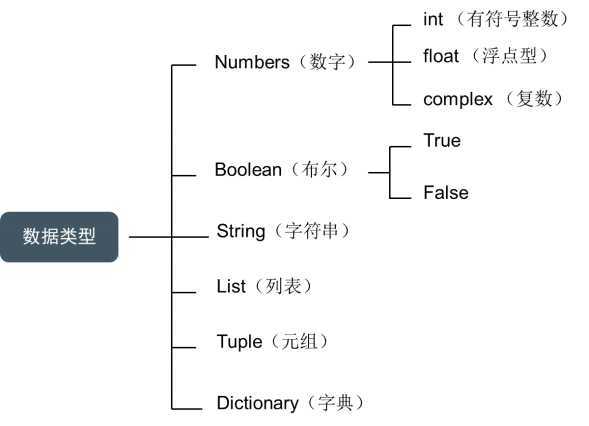

*** eval(str)根据str的值来自动判断转换为哪一种数据类型:
eval("123”) 转换为int
eval(“3.25”)转换为float
直接输出内容
输出单个和多个变量
格式化输出
格式化输出应用示例:
print("你输入的名字是:%s" %name)
print(“你输入的名字是:%s,你输入的年龄是:%d” %(name, age))
print(“你的身高是:%.2f” %height)
|
占位符 |
意义 |
占位符 |
意义 |
|
%c |
字符 |
%X |
十六进制整数 |
|
%s |
通过str()字符串转换来格式化 |
%x |
十六进制整数 |
|
%e |
索引符号 |
%o |
八进制整数 |
|
%E |
索引符号 |
%i |
有符号十进制整数 |
|
%f |
浮点实数,默认保留6位小数; 指定精度: %.<n>f, <n>代表保留的小数位数 |
%d |
有符号十进制整数 |
|
%g |
%f和%e的简写 |
%u |
无符号十进制整数 |
|
%G |
%f和%e的简写 |
|
|
print(“hello”, end=””)
print(“world”)
print(“你的名字是:{},你的年龄是{}”.format(name, age)
标识符:
命名规则:
module_name, package_name, ClassName, method_name, ExceptionName, function_name, GLOBAL_VAR_NAME, instance_var_name, function_parameter_name, local_var_name
关键字:
算术运算符:
|
符号 |
意义 |
|
+ |
加:两个对象相加 |
|
- |
减:得到负数或者一个数减去另外一个数 |
|
* |
乘:两个数相乘或是返回一个被重复若干次的字符串 |
|
/ |
除:x除以y |
|
% |
取模:返回除法的余数 |
|
** |
幂:返回x的y次幂 |
|
// |
取整除:返回商的整数部分 |
赋值运算符:
|
符号 |
意义 |
|
= |
简单的赋值运算符 |
|
+= |
加法赋值运算符 |
|
-= |
减法赋值运算符 |
|
*= |
乘法赋值运算符 |
|
/= |
除法赋值运算符 |
|
%= |
取模赋值运算符 |
|
**= |
幂赋值运算符 |
|
//= |
取整除赋值运算符 |
比较运算符:
|
符号 |
意义 |
|
== |
等于:比较对象是否相等 |
|
!= |
不等于:比较两个对象是否不相等 |
|
> |
大于:返回x是否大于y |
|
< |
小于:返回x是否小于y |
|
>= |
大于等于:返回x是否大于等于y |
|
<= |
小于等于:返回x是否小于等于y |
逻辑运算符:
|
符号 |
意义 |
|
and |
x and y:如果表达式x和y同时为True,则返回True,否则返回False |
|
or |
x or y:如果x或y中某一表达式为True,则返回True,否则返回False |
|
not |
not x:如果表达式x为True,则返回False,否则返回True |
运算符优先级:

if条件:
逻辑代码
else:
其他逻辑代码
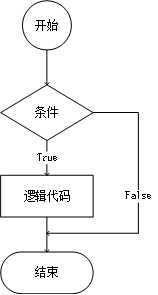
if 条件1:
逻辑代码1
elif 条件2:
逻辑代码2
elif 条件3:
逻辑代码3
else:
其他逻辑代码
if 条件1:
if 内部条件1:
内部逻辑代码1
elif 内部条件2:
内部逻辑代码2
else:
内部其他逻辑代码
elif 条件2:
逻辑代码2
else:
其他逻辑代码
while 判断条件:
条件满足,执行语句
首先对while条件判断,当条件为true时,执行循环体内语句块,然后再判断while条件,仍然为true则继续执行语句块,直到条件为false循环结束,执行循环后的代码
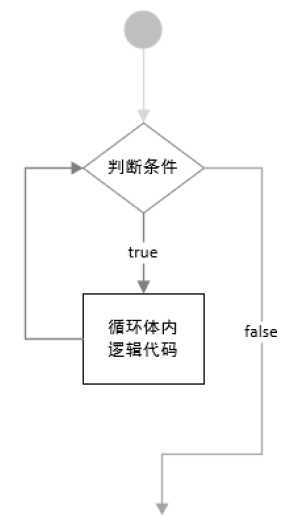
对于满足某种条件,重复调用实现相同功能的代码
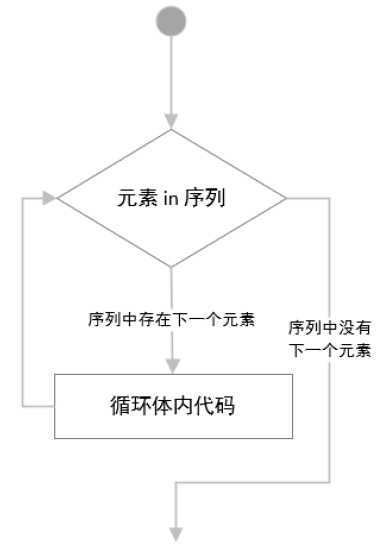
for 临时变量 in 序列:
序列中存在待处理元素则进入循环体执行代码
for i in range(0, 10, 1)
range(0,10): [0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
每次循环判断for中的条件,从序列的零脚标开始,将序列中的元素赋值给临时变量,进入循环体执行代码,执行完所有判断for中序列是否存在下一个元素,如果存在则继续进入循环体,依次类推,直到序列中最后一个位置的元素被处理完,循环结束。
while 条件:
break # 整个循环结束
while 条件:
代码
while条件:
break # 只结束内层整个循环
代码
for 变量 in 序列:
break #整个循环结束
for 变量in序列:
代码
For变量in序列:
break #只结束内层整个循环
代码
while 条件:
if条件:
continue #本次循环结束,后边的代码语句不执行
代码语句 #不会不执行
代码语句 #不会不执行
for变量in序列:
if条件:
continue #本次循环结束,后边的代码语句不执行
代码语句 #不会不执行
计算器功能:
小美奶茶馆盛大开业了!今天,门店前立出了以下招牌:
小美奶茶馆售卖宇宙无敌奶茶,奶茶虽好,可不要贪杯哦!每次限尝一种口味:
1)原味冰奶茶 3元 2)香蕉冰奶茶 5元 3)草莓冰奶茶 5元 4)芒果冰奶茶 7元
5)珍珠冰奶茶 7元
请您帮助小美奶茶馆的收银小妹设计一款价格结算系统,要求:
顾客可输入1-5来选择奶茶口味,输入其他数字则输出:‘Woops!我们只售卖以上五种奶茶哦!新口味敬请期待!’
顾客可输入购买数量,根据奶茶口味和数量计算总价。
顾客可输入是否为本馆会员,会员可以享受9折优惠。
输出顾客购买的详细信息,包括奶茶口味、购买数量、总价。若是会员输出会员价。
建议大家使用格式化输出。
S=”hello”或者’hello’
使用‘+’号将两个字符串连接成一个新的字符串
使用字符串格式化符号
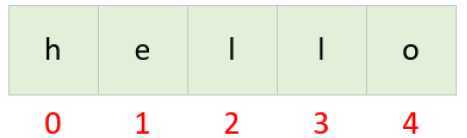
通过下标获取指定位置的字符:string_name[index]
语法:string_name[起始:结束:步长]
|
方法 |
说明 |
|
find(str[, start,end]) |
在字符串中查找制定的字符串是否存在,如果存在则返回第一个子字符串的起始下标,如果不存在则返回-1 start、end是可选参数,表示查找子字符串的起始和结束范围 |
|
count(str[, start, end]) |
在字符串中统计包含的子字符串的个数 |
|
replace(old, new[, count]) |
使用新的子字符串替换指定的旧子字符串,返回新的字符串 count是可选参数,可以指定替换的字符串个数,默认全部替换 |
|
split(sep[, maxsplit]) |
按照指定的分隔符分割字符串,返回分割之后所有元素的列表 maxsplit 是可选参数,指定对几个分隔符进行分割 |
|
startswith(prefix[, start, end]) |
判断字符串是否以指定前缀开头,返回值为True或False start、end是可选参数,表示查找前缀的起始和结束范围 |
|
endswith(suffix[, start, end]) |
判断字符串是否以制度后缀结束,返回值为True或False start、end是可选参数,表示查找后缀的起始和结束范围 |
|
upper() |
字符串所有字符大写 |
|
lower() |
字符串所有字符小写 |
name_list = ["zhangsan”, “lisi”, “wangwu”]
name_list[0]
name_list[1]
name_list[0] = “xiaobai”
|
方法 |
说明 |
例子 |
|
添加元素:append() insert() |
append()列表末尾条件元素 insert()在列表指定的下标位置添加元素 |
list.append(element) insert(index, element) |
|
组合列表: + extend() |
+组合两个列表生成新的列表 extend()向调用它的列表中添加另外一个列表的元素 |
list1 = list2 + list3 list1.extend(list2) |
|
删除元素: del pop() remove() |
del删除列表某下标位置的元素 remove删除某名称的元素 pop删除列表末尾元素 |
del list[index] list.remove(element) list.pop() |
|
判断元素在列表中是否存在: in not in |
可作为条件判断中的条件 |
|
|
排序: sort() |
列表内元素重排序: sort() 升序 sort(reverse=True)倒序 |
num_list.sort() num_list.sort(reverse=True) |
|
内容倒置: reverse |
将列表内容倒置 |
list.reverse() |
|
统计元素个数: count |
统计列表内指定元素个数 |
List.count(element) |
|
方法 |
说明 |
|
dic[key] = value |
添加/修改键值对 |
|
del dic[key] |
删除键值对 |
|
len(dic) |
键值对个数 |
|
dic.get(key) |
查找某键(不管是否存在) 若键存在于字典中,则返回该键对应值 若键不存在,则返回null |
|
dic.get(key, default_value) |
若键不存在,则添加键并设置默认值为default_value,并返回default_value |
|
for key in dic.keys() |
遍历字典所有键 |
|
for value in dic.values() |
遍历字典所有值 |
|
for item in dic.items() |
遍历字典所有键值对,返回元组,即type(item)为元组 |
|
for key,value in dic.items() |
遍历字典所有键值对,返回key和value |
|
dic.clear() |
清空字典 |
例如:name_set = set(list)
|
方法 |
说明 |
|
len(set) |
集合元素个数 |
|
set = set(list) set = set(str) |
将list的元素去重,并存储到set中 将字符串中的字符去重,并存储到set中 |
|
set.add(ele) |
添加元素至集合 |
|
set.update(序列) set.update([ele3, ele4], [ele5, ele6]) |
添加序列中的元素至集合,并且去重 |
|
set.remove(ele) |
删除集合中的元素 删除不存在的元素时会报错 |
|
set.discard(ele) |
删除集合中的元素 删除不存在的元素时不会报错 |
|
set.pop() |
随机删除集合中的某个元素,同时返回被删除的元素 |
|
set.clear() |
清空集合 |
|
交集intersection(&) |
set1 = {1,2,3,4} set2 = {2,6,7,8} set3 = set1 & set2 set3 = set1.intersection(set2) |
|
并集union(|) |
set1 = {1,2,3,4} set2 = {2,6,7,8} set3 = set1 | set2 set3 = set.union(set2) |
|
差集difference(-) |
set1 = {1,2,3,4} set2 = {2,6,7,8} set3 = set1 - set2 set3 = set1.difference(set2) |
|
对称差集(^) |
set1 = {1,2,3,4} set2 = {2,6,7,8} set3 = set1 ^ set2 |
def 函数名称(参数):
函数体代码
return 返回值
带参函数注意:调用函数时传入的参数个数与函数定义参数个数相同;
参数顺序要相同
形参:定义函数时设置的参数
实参:调用函数时传入的参数
***返回多个值时用逗号”,”隔开

函数内部定义的变量
不同函数内的局部变量可以定义相同的名字,互不影响
作用范围:函数体内有效,其他函数不能直接使用
函数外部定义的变量
作用范围:可以在不同函数中使用
在函数内使用global关键字实现修改全局变量的值(字典、列表除外,全局变量的字典 / 列表可在任意函数直接修改,不需使用global关键字)
全局变量命名建议以g_开头,如:g_name






|
字段 |
属性 |
值 |
|
年 |
tm_year |
2018 |
|
月 |
tm_mon |
1到12 |
|
日 |
tm_mday |
1到31 |
|
时 |
tm_hour |
0到23 |
|
分 |
tm_min |
0到59 |
|
秒 |
tm_sec |
0到61(60或61是润秒) |
|
一周的第几日 |
tm_wday |
0到6(0是周一) |
|
一年的第几日 |
tm_yday |
1到366,一年中的第几天 |
|
夏令时 |
tm_isdst |
是否为夏令时,值为1时是夏令时,值为0 时不是夏令时 |


|
格式化符号 |
说明 |
|
%y |
两位数的年份表示(00-99) |
|
%Y |
四位数的年份表示(000-9999) |
|
%m |
月份(01-12) |
|
%d |
月份中的一天(0-31) |
|
%H |
24小时制小时数(0-23) |
|
%I |
12小时制小时数(01-12) |
|
%M |
分钟数(00=59) |
|
%s |
秒(00-59) |
|
%a |
本地简化星期名称 |
|
%A |
本地完整星期名称 |
|
%b |
本地简化的月份名称 |
|
%B |
本地完整的月份名称 |
|
%c |
本地相应的日期表示和时间表示 |
|
%j |
年内的一天(001-366) |
|
%p |
本地A.M.或者P.M.的等价符 |
|
%U |
一年中的星期数(00-53)星期天为星期的开始 |
|
%w |
星期(0-6),星期天为星期的开始 |
|
%W |
一年中的星期数(00-53)星期一为星期的开始 |
|
%x |
本地相应的日期表示 |
|
%X |
本地相应的时间表示 |
|
%Z |
当前时区的名称 |
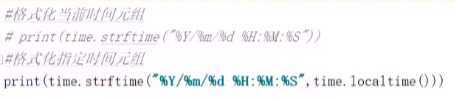

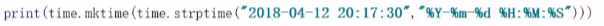




|
open(文件路径,访问模式,encoding=编码格式) r:只读模式 w:只写模式 a:追加模式 |
打开一个已存在的文件,或者创建新的文件 r模式打开不存在的文件会报错 w模式代开不存在的文件会创建新的文件 |
|
close() |
关闭已打开的文件 |
|
write(data) |
向文件中写入字符串 |
|
read() |
读取文件全部内容 |
|
readlines() |
读取文件全部内容,返回一个列表,每行数据是列表中的一个元素 |
|
readline() |
按行读取文件数据 |
|
writelines(字符串序列) |
将一个字符串序列(如字符串列表等)的元素写入到文件中 |
|
os.rename(oldname, newname) |
文件重命名 |
|
os.remove(filepath) |
删除文件 |
|
with open(文件路径,访问模式) as f: f.write(“hello python”) |
自动调用close方法 |
read和readlines一次性读取,并将内容保存在内存中

readline逐行读取

|
os.mkdir(path) |
创建文件夹 |
|
os.getcwd() |
获取程序运行的当前目录 |
|
os.listdir(path) |
获取指定目录下的文件列表 |
|
os.rmdir(path) |
删除文件夹 |
|
shutil.rmtree(path) |
删除非空文件夹 |
|
os.chdir(path) |
切换目录 |

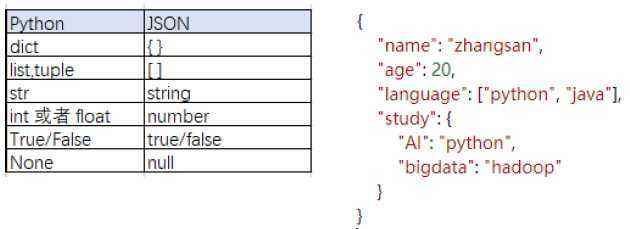


可以使用next(reader)遍历reader对象,获取每一行数据



标签:范围 存储 reverse object ade 分割 集合 方式 运算符优先级
原文地址:https://www.cnblogs.com/wendyw/p/10131169.html