标签:style blog http color io os ar 使用 for
发出标题这样的感慨的原因是这两天做的两个小算法题,从我狠狠被打脸的经历中感受到了编程的确是一门需要演算与实践的科学,单凭直觉与经验根本无法判定一个算法的优劣。废话不多说了,今天就先写一下这两个题中的第一个吧。
题目:
输入一个数字N,求小于等于N的所有质数。(真的是非常非常基础的题)
这道题我总共写了三种方法五种形式(第二三四个是同一种方法),前两种方法是自己想的,最后一种是参照的网上的思路,代码在分析的最后面(我用的C++,求不吐槽,C用的实在不好。因为数据量较大,所以没有显示部分,只打印一下素数的数量来进行核对)。
分别说一下这三种方法的思路:
① 最粗暴简单法:是从2遍历到n,每个数字从2到√n求一遍余数,如果有任意一次整除,就直接进行下一个数字的计算,若遍历到最后还未有整除,则计入素数表。
② 除素数法:准备一个数组用于存放素数,从2开始每个数字a除以素数数组中的不大于√a的每个素数,一旦出现整除就直接跳到下一个数,如果没有能整除的数,就将a加入素数数组。
③ 标志位法:准备一个n大小的bool型数组,全部标志为true。进入i的循环(i的范围从2到n),循环中有另一个j的循环(j的范围从2到n/i),每次循环都将数组的i*j位置上的值置为false。整个程序运行完后,只需要统计值为true的元素的下标即可。
① 粗暴简单法:公式是1+√2+√3+……√n,估计应该在O(nlog2n)附近,这已经很高了。
② 除素数法:因为质数数组大小的变化没有规律,因而没有准确的公式,但也应该在O(nlog2n)附近,而且绝对比①要小。
③ 标志位法:应该是n(1/1+1/2+1/3+……+1/n)是一个数项级数,表示完全不知道该怎么求了,而且公式输入到mathematics里面之后直接算不出东西来,凭直觉觉得应该会比第二种方法时间复杂度高,而且还有频繁的赋值操作,速度肯定慢。(就是在这里逗比的)
代码自带计时功能。

1 #include <iostream> 2 #include <ctime> 3 #include <vector> 4 #include <memory.h> 5 #include <cmath> 6 7 #define TOP_NUM 1500000 8 #define ARRAY_SIZE 150000 9 10 using namespace std; 11 12 int find_by_normal_loop() 13 { 14 int prime_count = 0; 15 bool isPrime = true; 16 17 for(int i=2; i<TOP_NUM; ++i) 18 { 19 isPrime = true; 20 21 for(int j=2; j<=sqrt(i); ++j) 22 { 23 if(0 == i%j) 24 { 25 isPrime = false; 26 break; 27 } 28 } 29 30 if(isPrime) 31 { 32 ++prime_count; 33 } 34 } 35 36 return prime_count; 37 } 38 39 int find_by_division_vector() 40 { 41 vector<int> res_vec; 42 bool isPrime = true; 43 44 for(int i=2; i<TOP_NUM; ++i) 45 { 46 isPrime = true; 47 48 for(unsigned int j=0; j<res_vec.size()&&res_vec[j]<=sqrt(i); ++j) 49 { 50 if(0 == i%res_vec[j]) 51 { 52 isPrime = false; 53 break; 54 } 55 } 56 57 if(isPrime) 58 { 59 res_vec.push_back(i); 60 } 61 } 62 63 return res_vec.size(); 64 } 65 66 int find_by_division_vector_iterator() 67 { 68 vector<int> res_vec; 69 vector<int>::iterator itor; 70 bool isPrime = true; 71 72 for(int i=2; i<TOP_NUM; ++i) 73 { 74 isPrime = true; 75 76 for(itor=res_vec.begin(); res_vec.end()!=itor&&(*itor)<=sqrt(i); ++itor) 77 { 78 if(0 == i%(*itor)) 79 { 80 isPrime = false; 81 break; 82 } 83 } 84 85 if(isPrime) 86 { 87 res_vec.push_back(i); 88 } 89 } 90 91 return res_vec.size(); 92 } 93 94 int find_by_division_array() 95 { 96 int res_vec[ARRAY_SIZE] = {0}; 97 bool isPrime = true; 98 int current_prime_count = 0; 99 100 for(int i=2; i<TOP_NUM; ++i) 101 { 102 isPrime = true; 103 104 for(int j=0; j<current_prime_count&&res_vec[j]<=sqrt(i); ++j) 105 { 106 if(0 == i%res_vec[j]) 107 { 108 isPrime = false; 109 break; 110 } 111 } 112 113 if(isPrime) 114 { 115 res_vec[current_prime_count] = i; 116 ++current_prime_count; 117 } 118 } 119 120 return current_prime_count; 121 } 122 123 int find_by_signal_array() 124 { 125 bool numArray[TOP_NUM]; 126 int prime_count = 0; 127 memset(numArray, true, sizeof(numArray)); 128 129 numArray[0] = false; 130 numArray[1] = false; 131 132 for(int i=2; i<TOP_NUM; ++i) 133 { 134 for(int j=2; i*j<TOP_NUM; ++j) 135 { 136 numArray[i*j] = false; 137 } 138 } 139 140 for(int i=0; i<TOP_NUM; ++i) 141 { 142 if(numArray[i]) 143 { 144 ++prime_count; 145 } 146 } 147 148 return prime_count; 149 } 150 151 int main() 152 { 153 cout << "Hello world!" << endl; 154 155 int result_count = 0; 156 clock_t t_begin,t_end; 157 158 t_begin = clock(); 159 result_count = find_by_normal_loop(); 160 t_end = clock(); 161 162 cout << "粗暴法:" << endl << "All count : " << result_count << endl << "Time : " << ( double)( ( t_end-t_begin)/1000.0) << endl; 163 164 t_begin = clock(); 165 result_count = find_by_division_vector(); 166 t_end = clock(); 167 168 cout << "除素数法:" << endl << "All count : " << result_count << endl << "Time : " << ( double)( ( t_end-t_begin)/1000.0) << endl; 169 170 t_begin = clock(); 171 result_count = find_by_division_vector_iterator(); 172 t_end = clock(); 173 174 cout << "除素数法(with iterator):" << endl << "All count : " << result_count << endl << "Time : " << ( double)( ( t_end-t_begin)/1000.0) << endl; 175 176 177 t_begin = clock(); 178 result_count = find_by_division_array(); 179 t_end = clock(); 180 181 cout << "除素数法(with array):" << endl << "All count : " << result_count << endl << "Time : " << ( double)( ( t_end-t_begin)/1000.0) << endl; 182 183 t_begin = clock(); 184 result_count = find_by_signal_array(); 185 t_end = clock(); 186 187 cout << "标志位法:" << endl << "All count : " << result_count << endl << "Time : " << ( double)( ( t_end-t_begin)/1000.0) << endl; 188 189 return 0; 190 }
实验环境是Code::Blocks + GCC。
在这里再解释一下三四这两种方法。方法三将遍历vector的方法由下标变成了迭代器iterator。而方法四则是抛弃了vector,直接使用一个数组来存放素数(数组大小图方便直接随手定了个当前数据环境下不会溢出的大小)。
下面就是喜闻乐见的被打脸过程了。
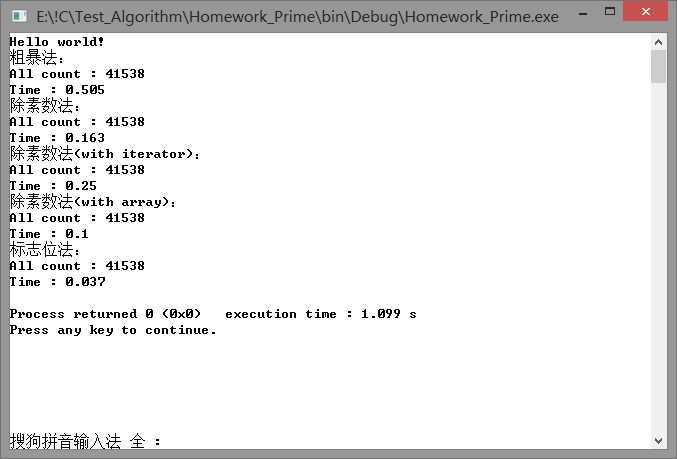
数字上限为500000时:
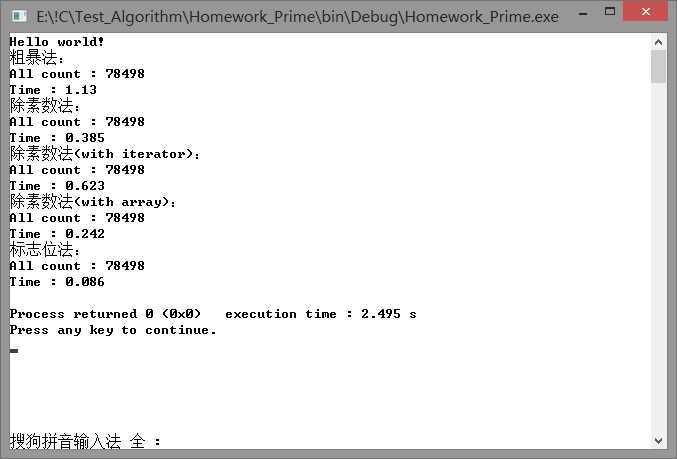
数字上限为1000000时:
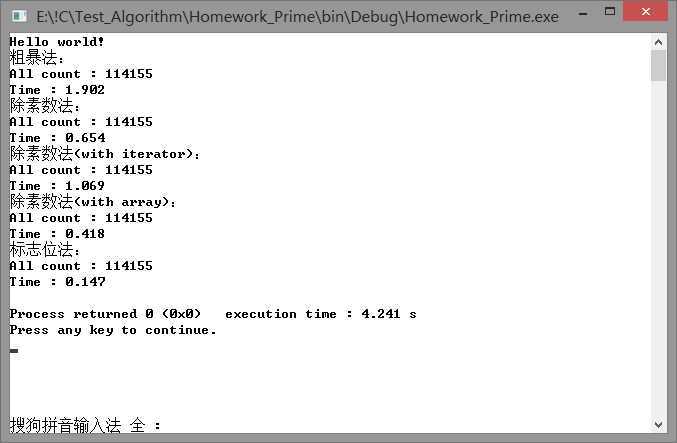
数字上限为1500000时:
被现实狠狠地抽了一巴掌。
第一种方法确实是最慢的这点毫无疑问。但第二三种方法的效率差别之大还是让人揪心。并且第三种方法的耗时似乎是随数据量增长而线性增长的,而第二种方法似乎并不是这样。。。

哦,不对,发错了,应该是这个表情,刚才那个是什么我也不知道。

现在再重新检视代码。
先比较第二种方法的三个不同形式,首当其冲的就是vector会比普通array效率低大概30%。Vector比直接用数组慢是公认的,但是毕竟不是所有的工程都能提前预知结果的数量,所以vector方法的实用性还是比数组方式高的。而使用迭代器iterator的方法又比普通的vector法慢了40%,这效率简直不能忍了。
回头再看第一种方法,它比第二种方法慢是必然的,效率大约只有第二种方法的第三种形式的20%多一点。原因就出在它需要比第二种方法多除的那一部分合数上。差距看起来还没有拉到非常夸张的样子,不能说这种方法效率不是太慢,只能说是因为数组的遍历速度拖慢了第二种方法的速度,所以显得差距没有这么大了而已。
最后就是狠狠打脸的第三种方法。效率高得令人发指,速度是第二种方法最快的第三种形式的三倍。总结问题根源,第三种方法如此之快应该有这么两点原因:①循环中的运算式为乘法,而不是之前几种方法的取余;②函数的时间复杂度计算还是不太熟,这谁主要原因,其次是数项级数到底什么情况还是没有搞清楚,跟头就栽这里了。
经验教训就是:①赋值操作多的方法不一定效率慢;②除法实在比乘法慢太多,能不用就不用;③数学一定要学好;④不要总是瞧不起空间复杂度很高的方法。
标签:style blog http color io os ar 使用 for
原文地址:http://www.cnblogs.com/myKennel/p/4052458.html
