标签:pyqt str img 规范 数字 confirm job 电脑 交易
Python学习之路第一节
1.Python介绍
2.Python安装
3.第一个程序:Hello World
4.变量
5.字符编码
6.用户输入和格式化输出
7.表达式if...else语句
8.表达式for 循环
9.break and continue
10.表达式while 循环
一、Python介绍
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
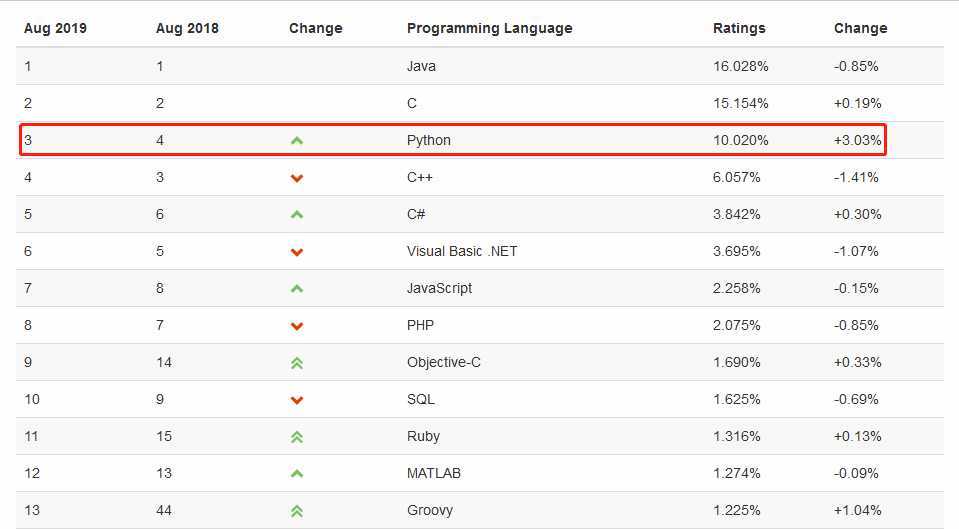
最新的TIOBE排行榜,Python赶超C++占据第三, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。
目前Python主要应用领域:
Python在一些公司的应用:
二、Python安装
1、下载安装包
https://www.python.org/downloads/
2、安装
默认安装路径:C:\python27
3、配置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】
如:原来的值;C:\python27,切记前面有分号
linux、Mac
无需安装,原装Python环境 ps:如果自带2.6,请更新至2.7
三、第一个程序:Hello World
在linux 下创建一个文件叫hello.py,并输入
print("Hello World!")
然后执行命令:python hello.py ,输出
localhost:~ jieli$ vim hello.py localhost:~ jieli$ python hello.py Hello World!
指定解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python print "hello,world"
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
四、变量
变量定义的规则:
变量的赋值
name = "View Yin"
name2 = name
print(name,name2)
name = "Sheng"
print("What is the value of name2 now?")
PS:常量需要大写
五、字符编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
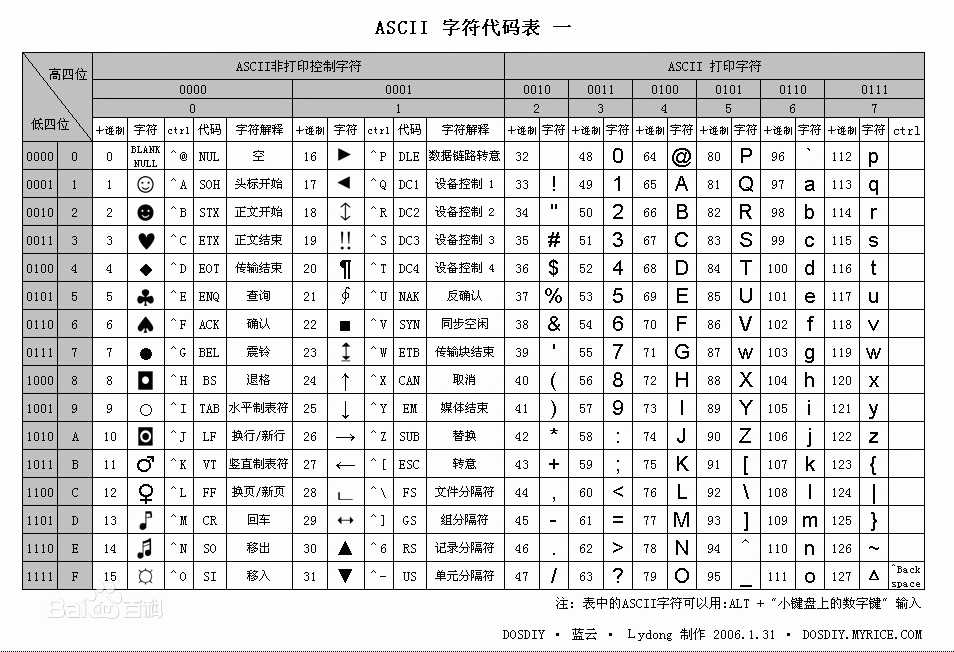
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
六、用户输入和格式化输出
输入
#!/usr/bin/env python
#_*_coding:utf-8_*_
#name = raw_input("What is your name?") #only on python 2.x
name = input("What is your name?")
print("Hello " + name )
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import getpass
# 将用户输入的内容赋值给 name 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print(pwd)
格式化输出
name=input(‘name:‘)
age=int(input(‘age:‘)) #不管输的是数字还是字符串,Python 3.X都默认为字符串类型
print(type(age),type(str(age))) #输出数据类型
job=input(‘job:‘)
salary=input(‘salary:‘)
#还有一种方式为“+”拼接,但不到万不得已不建议用,常用为如下三种
info=‘‘‘
------info of %s------
Name:%s
Age:%d
Job:%s
Salary:%s
‘‘‘%(name,name,age,job,salary)
print(info)
info2=‘‘‘
------info of {_name}------
Name:{_name}
Age:{_age}
Job:{_job}
Salary:{_salary}
‘‘‘.format(_name=name,_age=age,_job=job,_salary=salary)
print(info2)
info3=‘‘‘
------info of {0}------
Name:{0}
Age:{1}
Job:{2}
Salary:{3}
‘‘‘.format(name,age,job,salary)
print(info3)
七、表达式if...else语句
场景一、用户登陆验证
# 提示输入用户名和密码
# 验证用户名和密码
# 如果错误,则输出用户名或密码错误
# 如果成功,则输出 欢迎,XXX!
#!/usr/bin/env python
# -*- coding: encoding -*-
import getpass
name = input(‘请输入用户名:‘)
pwd = getpass.getpass(‘请输入密码:‘)
if name == "Yin" and pwd == "abc123":
print("欢迎,Yin!")
else:
print("用户名或密码错误")
场景二、猜年龄游戏
在程序里设定好你的年龄,然后启动程序让用户猜测,用户输入后,根据他的输入提示用户输入的是否正确,如果错误,提示是猜大了还是小了
#!/usr/bin/env python
# -*- coding: utf-8 -*-
my_age =25
user_input = int(input("input your guess num:"))
if user_input == my_age:
print("yes, you got it !")
elif user_input < my_age:
print("Think oldder!")
else:
print("Think younger!")
八、表达式for 循环
最简单的循环10次
#_*_coding:utf-8_*_
for i in range(10):
print("loop:", i )
输出:
loop: 0 loop: 1 loop: 2 loop: 3 loop: 4 loop: 5 loop: 6 loop: 7 loop: 8 loop: 9
九、break and continue
遇到小于5的循环次数就不走了,直接跳入下一次循环
for i in range(10):
if i<5:
continue #不往下走了,直接进入下一次loop
print("loop:", i )
遇到大于5的循环次数就不走了,直接退出
for i in range(10):
if i>5:
break #不往下走了,直接跳出整个loop
print("loop:", i )
十、表达式while 循环
count=0
while True:
print(‘count:‘,count)
count=count+1 #count +=1
if count==1001:
break
循环1000次就退出
如何实现让用户不断的猜年龄,但到了三次后询问用户是否继续,不继续就退出:
age_of_yin=24
count=0
while count<3:
guess_age = int(input(‘guess age:‘)) # 默认输入的为字符型
if guess_age==age_of_yin:
print(‘恭喜,答对了!‘)
break
elif guess_age>age_of_yin:
print(‘往小了想想...‘)
else:
print(‘往大的想想...‘)
count=count+1
if count==3:
countiue_confirm=input(‘Do you want to keep guess?‘)
if countiue_confirm !=‘n‘:
count=0
else:
print(‘试了太多次啦...byebye‘)
标签:pyqt str img 规范 数字 confirm job 电脑 交易
原文地址:https://www.cnblogs.com/view94/p/11484061.html