标签:blob level 记录 代码 写代码 生成 元素 是什么 当当
之前没学过Python,最近因一些个人需求,需要写个小爬虫,于是就搜罗了一批资料,看了一些别人写的代码,现在记录一下学习时爬过的坑。
如果您是从没有接触过Python的新手,又想迅速用Python写出一个爬虫,那么这篇文章比较适合你。
首先,我通过:
https://mp.weixin.qq.com/s/ET9HP2n3905PxBy4ZLmZNw
找到了一份参考资料,它实现的功能是:爬取当当网Top 500本五星好评书籍
源代码可以在Github上找到:
https://github.com/wistbean/learn_python3_spider/blob/master/dangdang_top_500.py
然而,当我运行这段代码时,发现CPU几乎满负荷运行了,却根本没有输出。
现在我们来分析一下其源代码,并将之修复。
先给出有问题的源码:
1 import requests 2 import re 3 import json 4 5 6 def request_dandan(url): 7 try: 8 response = requests.get(url) 9 if response.status_code == 200: 10 return response.text 11 except requests.RequestException: 12 return None 13 14 15 def parse_result(html): 16 pattern = re.compile( 17 ‘<li>.*?list_num.*?(\d+).</div>.*?<img src="(.*?)".*?class="name".*?title="(.*?)">.*?class="star">.*?class="tuijian">(.*?)</span>.*?class="publisher_info">.*?target="_blank">(.*?)</a>.*?class="biaosheng">.*?<span>(.*?)</span></div>.*?<p><span\sclass="price_n">¥(.*?)</span>.*?</li>‘, 18 re.S) 19 items = re.findall(pattern, html) 20 21 for item in items: 22 yield { 23 ‘range‘: item[0], 24 ‘iamge‘: item[1], 25 ‘title‘: item[2], 26 ‘recommend‘: item[3], 27 ‘author‘: item[4], 28 ‘times‘: item[5], 29 ‘price‘: item[6] 30 } 31 32 33 def write_item_to_file(item): 34 print(‘开始写入数据 ====> ‘ + str(item)) 35 with open(‘book.txt‘, ‘a‘, encoding=‘UTF-8‘) as f: 36 f.write(json.dumps(item, ensure_ascii=False) + ‘\n‘) 37 38 39 def main(page): 40 url = ‘http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-‘ + str(page) 41 html = request_dandan(url) 42 items = parse_result(html) # 解析过滤我们想要的信息 43 for item in items: 44 write_item_to_file(item) 45 46 47 if __name__ == "__main__": 48 for i in range(1, 26): 49 main(i)
是不是有点乱?别急,我们来一步步分析。(如果您不想看大段的分析,可以直接跳到最后,在那里我会给出修改后的,带有完整注释的代码)
首先,Python程序中的代码是一行行顺序执行的,前面都是函数定义,因此直接先运行第47-49行的代码:
if __name__ == "__main__": for i in range(1, 26): main(i)
看样子这里是在调用main函数(定义在第39行),那么__name__是什么呢?
__name__是系统内置变量,当直接运行包含main函数的程序时,__name__的值为"__main__",因此main函数会被执行,而当包含main函数程序作为module被import时,__name__的值为对应的module名字,此时main函数不会被执行。
为了加深理解,可以阅读这篇文章,讲得非常清楚:
https://www.cnblogs.com/keguo/p/9760361.html
我们的程序里是直接运行包含main函数的程序的,因此__name__的值就是__main__。
还有个小细节需要注意一下:
像Lua这种语言,函数在结束之前会有end作为函数结束标记,包括if,for这种语句,都会有相应的end标记。但Python中是没有的,Python中是用对应的缩进来表示各个作用域的,我们把第47-49行的代码稍微改一下来进一步说明:
新建个Python文件,直接输入:
if __name__ == "__main__": for i in range(1,5): print("内层") print("外层")
此时for语句比if语句缩进更多,因此位于if的作用域内,同理,print("内层")语句位于for语句的作用域内,因此会打印5次,print("外层")已经不在for语句的作用域内,而在if语句的作用域内,因此只打印1次,运行结果如下:
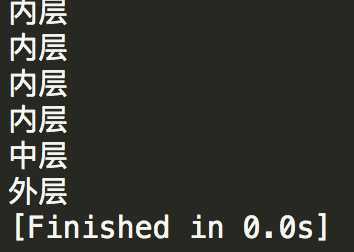
那么47-49行做的就是循环调用25次main函数(range左闭右开),为什么是25次呢?因为要爬取的当当网好评榜一页有20本图书数据,要爬500本我们需要发送25次数据请求。
我们看一下main函数(39-44行)做了什么:
首先进行了url的拼接,每次调用时传入不同的page,分别对应第1-25页数据。随后调用request_dandan发送数据请求,看一下request_dandan(第6-12行)做了什么:
这里调用了requests模块向服务器发送get请求,因此要在程序开头导入requests模块(第1行),get请求去指定的url获取网页数据,随后对响应码作了判断,200代表获取成功,成功就返回获取的响应数据。要注意的一点是,这里get请求是同步请求,意思是发送请求后程序会阻塞在原地,直到收到服务器的响应后继续执行下一行代码。
接下来main函数要调用parse_result(第15到30行)对获取到的html文本进行解析,提取其中与图书有关的信息,在分析这段代码之前,我们需要先了解下返回的html文件的格式:
我们可以在chrome浏览器中的开发者工具里,查看对应请求网页响应的html格式,以我的为例:
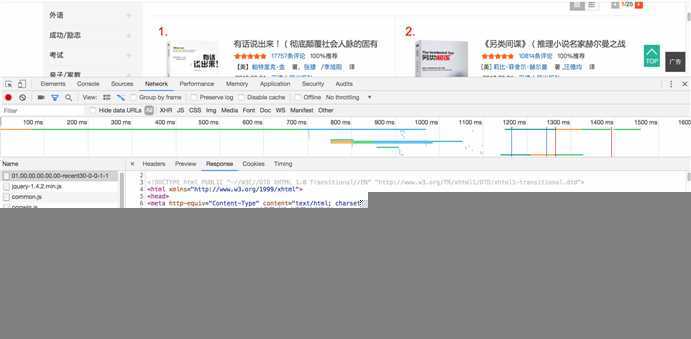
以第一本书“有话说出来”为例,用Command+F(Mac下)快速翻找一下与要爬取的图书有关的信息:

每一本书的信息格式是这样的:
<li>
<div class="list_num red">1.</div>
<div class="pic"><a href="http://product.dangdang.com/25345988.html" target="_blank"><img src="http://img3m8.ddimg.cn/8/26/25345988-1_l_1.jpg" alt="有话说出来!(彻底颠覆社会人脉的固有方式,社交电池帮你搞定社交。社交恐惧症患者必须拥有的一本实用社交指南,初入大学和职场的必备“攻略”,拿起这本书,你也是“魏璎珞”)纤阅出品" title="有话说出来!(彻底颠覆社会人脉的固有方式,社交电池帮你搞定社交。社交恐惧症患者必须拥有的一本实用社交指南,初入大学和职场的必备“攻略”,拿起这本书,你也是“魏璎珞”)纤阅出品"/></a></div>
<div class="name"><a href="http://product.dangdang.com/25345988.html" target="_blank" title="有话说出来!(彻底颠覆社会人脉的固有方式,社交电池帮你搞定社交。社交恐惧症患者必须拥有的一本实用社交指南,初入大学和职场的必备“攻略”,拿起这本书,你也是“魏璎珞”)纤阅出品">有话说出来!(彻底颠覆社会人脉的固有方式,社交电池帮你搞定社<span class=‘dot‘>...</span></a></div>
<div class="star"><span class="level"><span style="width: 100%;"></span></span><a href="http://product.dangdang.com/25345988.html?point=comment_point" target="_blank">17757条评论</a><span class="tuijian">100%推荐</span></div>
<div class="publisher_info">【美】<a href="http://search.dangdang.com/?key=帕特里克·金" title="【美】帕特里克·金 著,张捷/李旭阳 译" target="_blank">帕特里克·金</a> 著,<a href="http://search.dangdang.com/?key=张捷" title="【美】帕特里克·金 著,张捷/李旭阳 译" target="_blank">张捷</a>/<a href="http://search.dangdang.com/?key=李旭阳" title="【美】帕特里克·金 著,张捷/李旭阳 译" target="_blank">李旭阳</a> 译</div>
<div class="publisher_info"><span>2018-08-01</span> <a href="http://search.dangdang.com/?key=天津人民出版社" target="_blank">天津人民出版社</a></div>
<div class="biaosheng">五星评分:<span>16273次</span></div>
<div class="price">
<p><span class="price_n">¥30.40</span>
<span class="price_r">¥42.00</span>(<span class="price_s">7.2折</span>)
</p>
<p class="price_e"></p>
<div class="buy_button">
<a ddname="加入购物车" name="" href="javascript:AddToShoppingCart(‘25345988‘);" class="listbtn_buy">加入购物车</a>
<a ddname="加入收藏" id="addto_favorlist_25345988" name="" href="javascript:showMsgBox(‘addto_favorlist_25345988‘,encodeURIComponent(‘25345988&platform=3‘), ‘http://myhome.dangdang.com/addFavoritepop‘);" class="listbtn_collect">收藏</a>
</div>
</div>
是不是很乱?不要急,我们慢慢来分析,首先我们要明确自己要提取图书的哪部分信息,我们这里决定爬取它的:
排名,书名,图片地址,作者,推荐指数,五星评分次数和价格。
那么对这么大段的html文本,怎么提取每本书的相关信息呢?答案自然是通过正则表达式,在parse_result函数中,先构建了用来匹配的正则表达式(第16行),随后对传入的html文件执行匹配,获取匹配结果(第19行),注意,这一步需要re模块的支持(在第1行导入re模块),re.compile是对匹配符的封装,直接用re.match(匹配符,要匹配的原文本)可以达到相同的效果, 当然,这里没有用re.match来执行匹配,而是用了re.findall,这是因为后者可以适用于多行文本的匹配。另外,re.compile后面的第2个参数,re.S是用来应对换行的,.匹配的单个字符不包括\n和\r,当遇到换行时,我们需要用到re.S。
上面的这段表述可能不大清楚,具体re模块的正则匹配用法请自行百度,配合自己动手实验才能真正明白,这里只能描述个大概,另外,我们这里不会从头开始讲解正则表达式的种种细节,而是仅对代码中用到的正则表达式进行分析,要了解更多正则表达式相关的消息,就需要您自行百度了,毕竟对一个程序员来说,自学能力还是很重要的。
好,我们来看下代码用到的正则表达式:
一段段来分析,首先是:
<li>.*?list_num.*?(\d+).</div>
.代表匹配除了\n和\r之外的任意字符,*代表匹配0次或多次,?跟在限制符(这里是*)后面是代表使用非贪婪模式匹配,因为默认的正则匹配是贪婪匹配,比如下面这段代码:
import re content = ‘abcabc‘ res = re.match(‘a.*c‘,content) print(res.group())
此时匹配时会匹配尽可能长的字符串,因此会输出abcabc,而若把a.*c改为a.*c?,此时是非贪婪匹配,会匹配尽可能少的字符串,因此会输出abc。
然后是\d,代表匹配一个数字,+代表匹配1个或多个。因此上面的表达式匹配的就是html文本中下图所示的部分:

注意,\d+被括号括起来了,代表将匹配的这部分内容(即图中的1这个数字)捕获并作为1个元素存放到了一个数组中,所以现在匹配结果对应的数组中(即item)第一个元素是1,也就是排名。
随后是
.*?<img src="(.*?)"
显然它匹配的是下面这段:
![]()
![]()
此时会把括号中匹配到的图片地址作为第2个元素存到数组中
剩下的匹配都是同样的原理,并没有什么值得注意的点,就不一一描述了,整个正则表达式一共有7对括号,因此有数组中存了7个元素,分别对应我们要提取的排名,书名,图片地址,作者,推荐指数,五星评分次数和价格。
re.findall进行了进行了匹配后返回一个数组items,里面存放了所有匹配成功的条目(item),每个item对应一次对正则表达式的成功匹配,也就是上面说的7个元素的数组。
随后程序中遍历了items数组,将数组中每个item的数据封装成一个表,并分别进行返回。
这里出了问题,每次返回的都是items数组中的一个item,而main函数中却对返回值又进一步遍历了其中的元素,并调用write_item_to_file将每个元素写到自定义的文件中(43-44行)。
我们来看下write_item_to_file:
第31行的:
with open(‘book.txt‘, ‘a‘, encoding=‘UTF-8‘) as f:
是一种简化写法,等价于:
try: f = open(‘book.txt‘, ‘a‘) print(f.read()) finally: if f: f.close()
具体可以参考:https://www.cnblogs.com/yizhenfeng/p/7554620.html
这里打开book.txt后(没有会自动创建),用write函数将item转换成的json格式的字符串写入(json.dumps函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串))
而我们传入write_item_to_file函数的是item中的一个元素,显然不是一个表,这当然不对。显然这里源代码写得有问题,在parse_result函数中,不应该遍历匹配到的items并返回其中的每个item,而是应该直接返回items(对应正则表达式所有匹配结果),这样,在main函数中,就可以正常地对items遍历,抽出每个item(对应正则表达式的一组匹配结果),传入write_item_to_file,后者在写入时,对item进行json转换,由于item是一个表,可以正常转换,自然也能正常写入。
下面给出修改后的代码:
1 import requests 2 import re 3 import json 4 5 def request_dandan(url): 6 try: 7 #同步请求 8 response = requests.get(url) 9 if response.status_code == 200: 10 return response.text 11 except requests.RequestException: 12 return None 13 14 def parse_result(html): 15 pattern = re.compile(‘<li>.*?list_num.*?(\d+).</div>.*?<img src="(.*?)".*?class="name".*?title="(.*?)">.*?class="star">.*?class="tuijian">(.*?)</span>.*?class="publisher_info">.*?target="_blank">(.*?)</a>.*?class="biaosheng">.*?<span>(.*?)</span></div>.*?<p><span\sclass="price_n">¥(.*?)</span>.*?</li>‘,re.S) 16 items = re.findall(pattern, html) 17 return items 18 # for item in items: 19 # yield { 20 # ‘range‘: item[0], 21 # ‘iamge‘: item[1], 22 # ‘title‘: item[2], 23 # ‘recommend‘: item[3], 24 # ‘author‘: item[4], 25 # ‘times‘: item[5], 26 # ‘price‘: item[6] 27 # } 28 29 def write_item_to_file(item): 30 print(‘开始写入数据 ====> ‘ + str(item)) 31 with open(‘book.txt‘, ‘a‘, encoding=‘UTF-8‘) as f: 32 f.write(json.dumps(item, ensure_ascii=False) + ‘\n‘) 33 34 def main(page): 35 url = ‘http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-‘ + str(page) 36 html = request_dandan(url) 37 items = parse_result(html) 38 for item in items: 39 write_item_to_file(item) 40 41 if __name__ == "__main__": 42 for i in range(1,5): 43 main(i)
标红的就是修改的部分,去试试吧,此时查看新生成的book.txt文件,结果如下:

至此,代码修改成功。下面记录一些额外的知识点,感兴趣的可以看看:
原先的错误代码用到了yield,之前用C#写代码时会用到协程,里面就用到了yield关键子,那么yield在Python中是怎么用的呢?
事实上,函数中一旦有语句被yield标记,那这个函数就不一样了,此时直接调用它是不会调用的,而得理解成一种赋值效果,相当于暂存了这个函数,当要真正调用此函数时,需要用next驱动它,没驱动一次,就相当于调用一次这个函数,而yield标记的语句实现的功能可以理解为是return,因此调用函数时,一旦运行到yield语句,就会返回,但返回后会记住当前运行到的yield语句位置,当下次再调用yield时,会从之前中断的yield语句处继续执行剩下的代码。
是不是感觉有点抽象?不要着急,我为您精心准备了一份资料,参考下面这篇文章,相信你很快就能明白它的使用方法:
https://www.cnblogs.com/gausstu/p/9545519.html
至此,要讲的基本讲完了。最后讲一个小知识点吧,写代码时,在return或yield后面的大括号,是不能移到下一行中的,比如Python中:
return { ‘range‘: 1, ‘image‘:here }
return { ‘range‘: 1, ‘image‘:here }
这两种写法,区别仅仅是第二种把大括号写在了下面那行,但在Python中,是会报错的,这点需要注意一下。
以前碰到问题搜别人的博客时,总是各种嫌弃,嫌弃这个写得不清楚,那个写得太简单,现在终于明白为什么会这样了,主要是写博客确实比较麻烦,举个例子吧,同样的知识,花一天能吸收完,但真要把它写出来,并且写得比较清晰,别人能看懂,基本还要再花一天。以前还好,博主一直在读研,有大把的时间可以记录,现在工作了,也没啥时间了,虽然工作中学了不少东西,但实在没时间记录,毕竟空余时间若是都用来写博客,就没时间学更多的东西。
很多人的做法是用降低博客的质量来弥补,比如有些问题,明明很多细节,就用一两句话一笔带过,导致的结果就是除了自己没人能看懂,别人照着做的时候各种踩坑。说真的,这其实是一种很自私的行为,对记录人来说,可能真的只需要记几笔,提醒下自己关键点即可。但对那些碰到问题去搜解决方案的人来说,真的是一种煎熬,我相信大家都有这样的体会:项目中碰到了一个问题,去网上搜索解决方案,结果花了半天时间,网上的方案各种不靠谱,各种不详细,耗时又耗神。
在我看来,即使有着上面提到的原因,这种做法也是不可原谅的,随着垃圾信息的不断增加,每个人获取有用信息的成本必然不断上升,到最后,受害的是所有人。
可惜我无法改变这一切,我唯一能做到的就是,在我的博客中,尽可能将我的探索过程描述清楚,将每个细节展现给来看我博客的人,毕竟你们花了时间看我的博客,我也不能对不起你们。
好了,发点牢骚而已,不要在意,有空我会陆续将工作中碰到的问题及解决方案逐渐记录下来的,可能会有点慢,但好在足够详细。
标签:blob level 记录 代码 写代码 生成 元素 是什么 当当
原文地址:https://www.cnblogs.com/czw52460183/p/11484001.html