标签:lin 映射 input 网络通 简介 好的 map mbed 比较
SENet提出了一种更好的特征表示结构,通过支路结构学习作用到input上更好的表示feature。结构上是使用一个支路去学习如何评估通道间的关联,然后作用到原feature map上去,实现对输入的校准。支路的帮助学习到的是神经网络更加适合的表示。为了使网络通过全局信息来衡量通道关联,结构上使用了global pooling捕获全局信息,然后连接两个全连接层,作用到输入上去,即完成了对输入的重校准,可以使网络学习到更好的表示。
一个block的结构大致如下:
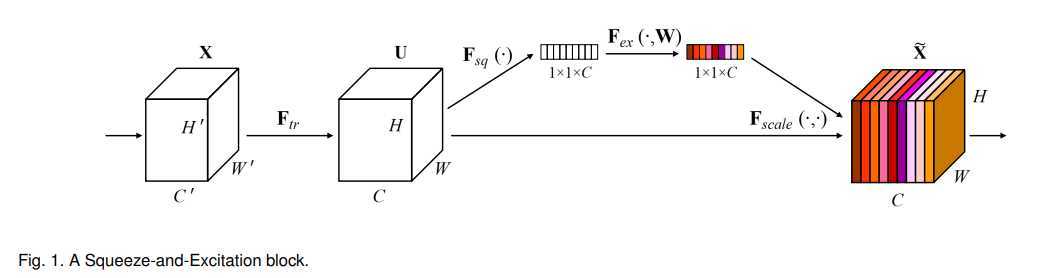
上图中Fsq是Squeeze过程,Fex是Excitation过程,然后通过Fscale将学习到的权重作用在输入上。
作者将Squeeze过程称为global information embedding的过程,因为squeeze的过程实际上是对feature map利用global pooling来整合全局特征。
作者将Excitation过程称为重校准过程,因为此过程通过支路学习到的权重,作用到原输入上去,要实现对每个通道进行打分,即网络学习到通道score,则必须要学习到非线性结果,所以作者采用fc-relu-fc-sigmoid的excitation结构来实现score映射。
根据作者论文中的举例,可以清楚看到以Inception为例的Squeeze和Excitation过程:
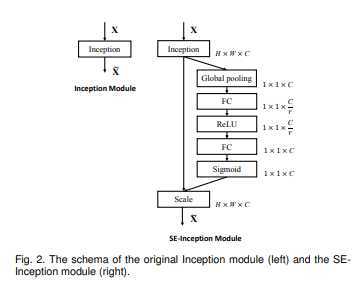
而Fscale过程就是对应相乘,把每个通道的权重对应乘上input的对应通道feature。
这个论文比较好理解。
论文原文:https://arxiv.org/pdf/1709.01507.pdf
[论文理解] Squeeze-and-Excitation Networks
标签:lin 映射 input 网络通 简介 好的 map mbed 比较
原文地址:https://www.cnblogs.com/aoru45/p/11486528.html