标签:std 查看 tail ring print 跳转 时间 重写 web
通过Python脚本读取博客园分页数据,把标题、摘要和链接过滤出来,方便我们在命令行中阅读。
阅读本文可以熟悉一般爬虫的原理,以及指令交互界面的开发。
一、说明
运行环境:win10/Python 3.5(Win10的玩家可以下载 Window Terminal Preview玩玩,确实不错!);
主要模块:requests(发送http请求)、lxml.etree(格式化DOM树,xpath查找)、sys(获取命令行参数、重写标准输出等)、os(系统相关、如清屏操作);
注意:由于时间仓促,没有详细测试,遇到问题麻烦这里反馈;所有英文指令不区分大小写;
后续:后续还会增加查看详情,跳转浏览器等。
本文地址:https://www.cnblogs.com/reader/p/11487398.html
二、交互页面
1、1 开始
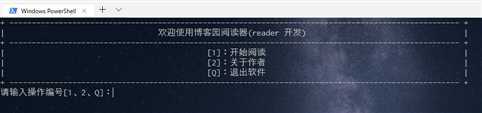
直接运行脚本,即可出现如图操作界面。可以输入 1、2和Q进行操作。
1、2 开始阅读
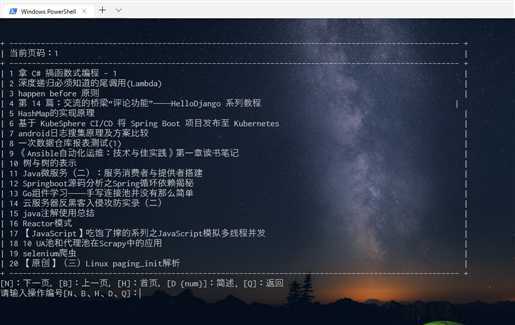
如上图所示,输入 1 进入的开始阅读界面。可以在头部看到页码。这里操作相对多,N(next)下一页,B(Back)上一页,H(Home)首页,Q(Quit)退出,D {num}(Detail, 后面需要输入标题前面对应的数字进行读取摘要和链接等)。
1、3 阅读摘要和链接 
如图所示,每行分别对应 标题、链接和摘要。
三、代码分析
3、1 思路
采集页面-->解析页面内容-->收集必要信息
3.2 数据采集
如下代码所示,根据页码进行数据采集。这里需要注意摘要的获取方式:
li.xpath(‘p‘)[0].xpath(‘string(.)‘)
1 def download(self, page): 2 """下载html页面内容""" 3 self.set_target_url(page) 4 response = requests.get(self.target_url, headers=self.headers) 5 if response.status_code == 200: 6 return response.content 7 else: 8 print("download fail") 9 return "" 10 11 def parse(self, content): 12 """解析HTML内容""" 13 html = etree.HTML(content) 14 lists = html.xpath(‘//div[@id="post_list"]//div[@class="post_item_body"]‘) 15 16 del html 17 k = 1 18 print(‘+‘, ‘--‘ * 50, ‘+‘) 19 print(‘|‘, str("当前页码:"+str(self.page)).ljust(95), ‘|‘) 20 print(‘+‘, ‘--‘ * 50, ‘+‘) 21 for li in lists: 22 title = str(li.xpath(‘h3/a/text()‘)[0]) 23 link = li.xpath(‘h3/a/@href‘)[0] 24 desc = li.xpath(‘p‘)[0].xpath(‘string(.)‘) 25 26 self.lists[k] = { 27 ‘title‘: title, 28 ‘desc‘: desc.strip(), 29 ‘link‘: link 30 } 31 32 print(‘|‘, k, self.formatByWidth(title, 100-1-len(str(k))), ‘|‘) 33 k += 1 34 del lists 35 print(‘+‘, ‘--‘ * 50, ‘+‘)
四、源码
注意:代码仅供学习,杜绝其他方式使用!请注明转发地址。

1 # -*- coding:UTF-8 -*- 2 import requests 3 from lxml import etree 4 import sys 5 import io 6 import os 7 8 9 sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding=‘gb18030‘) 10 11 12 class CnBlogs: 13 """" 14 Auth:reader 15 发表地址:https://www.cnblogs.com/reader/p/11487398.html 16 作者地址:https://www.cnblogs.com/reader 17 """ 18 def __init__(self): 19 self.headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘} 20 21 self.target_domain = "https://www.cnblogs.com" 22 self.page = 1 23 self.lists = {} 24 25 def clearscreen(self): 26 """根据系统,清屏操作""" 27 # window下的清屏方式 28 os.system("cls") 29 30 def set_target_url(self, page): 31 if page == 1: 32 self.target_url = self.target_domain 33 else: 34 self.target_url = ‘https://www.cnblogs.com/sitehome/p/‘+str(page) 35 36 def download(self, page): 37 """下载html页面内容""" 38 self.set_target_url(page) 39 response = requests.get(self.target_url, headers=self.headers) 40 if response.status_code == 200: 41 return response.content 42 else: 43 print("download fail") 44 return "" 45 46 def isascii(self, ch): 47 return ch <= u‘\u007f‘ 48 49 def formatByWidth(self, text, width): 50 """格式化字符串长度""" 51 count = 0 52 for u in text: 53 if not self.isascii(u): 54 count += 1 55 return text + " " * (width - count - len(text)) 56 57 def parse(self, content): 58 """解析HTML内容""" 59 html = etree.HTML(content) 60 lists = html.xpath(‘//div[@id="post_list"]//div[@class="post_item_body"]‘) 61 62 del html 63 k = 1 64 print(‘+‘, ‘--‘ * 50, ‘+‘) 65 print(‘|‘, str("当前页码:"+str(self.page)).ljust(95), ‘|‘) 66 print(‘+‘, ‘--‘ * 50, ‘+‘) 67 for li in lists: 68 title = str(li.xpath(‘h3/a/text()‘)[0]) 69 link = li.xpath(‘h3/a/@href‘)[0] 70 desc = li.xpath(‘p‘)[0].xpath(‘string(.)‘) 71 72 self.lists[k] = { 73 ‘title‘: title, 74 ‘desc‘: desc.strip(), 75 ‘link‘: link 76 } 77 78 print(‘|‘, k, self.formatByWidth(title, 100-1-len(str(k))), ‘|‘) 79 k += 1 80 del lists 81 print(‘+‘, ‘--‘ * 50, ‘+‘) 82 83 def descopt(self, k): 84 """读取详情""" 85 k = int(k) 86 if k not in self.lists.keys(): 87 return 88 self.clearscreen() 89 print(‘+‘, ‘--‘ * 50, ‘+‘) 90 print(‘|‘, self.formatByWidth(self.lists[k][‘title‘], 100), ‘|‘) 91 print(‘+‘, ‘--‘ * 50, ‘+‘) 92 print(‘|‘, self.formatByWidth(self.lists[k][‘link‘], 100), ‘|‘) 93 print(‘+‘, ‘--‘ * 50, ‘+‘) 94 95 print(‘|‘, self.formatByWidth(self.lists[k][‘desc‘], 100), ‘|‘) 96 97 print(‘+‘, ‘--‘ * 50, ‘+‘) 98 input("输入任意键返回...\r\n") 99 100 def readopt(self): 101 """开始阅读操作""" 102 while True: 103 self.clearscreen() 104 print("\r\n") 105 html = self.download(page=self.page) 106 self.parse(html) 107 108 print("[N]:下一页,[B]:上一页,[H]:首页,[D {num}]:简述, [Q]:返回") 109 110 cmd = input("请输入操作编号[N、B、H、D、Q]:") 111 112 if cmd == ‘Q‘ or cmd == ‘q‘: # 返回 113 break 114 elif cmd == ‘N‘ or cmd == ‘n‘: # 下一页 115 self.page += 1 116 elif cmd == ‘B‘ or cmd == ‘b‘: # 上一页 117 self.page -= 1 118 if self.page <= 0: 119 self.page = 1 120 elif cmd == ‘H‘ or cmd == ‘h‘: # 首页 121 self.page = 1 122 else: 123 cmd = cmd.split(‘ ‘) 124 125 if len(cmd) != 2: 126 continue 127 # 读取简述 128 if cmd[0] == ‘D‘ or cmd[0] == ‘d‘: 129 self.descopt(cmd[1]) 130 131 def aboutopt(self): 132 self.clearscreen() 133 print("博客园地址: https://www.cnblogs.com/reader\r\n") 134 input("输入任意键返回...\r\n") 135 136 def start(self): 137 self.clearscreen() 138 while True: 139 print(‘+‘, ‘--‘*50, ‘+‘) 140 print(‘|‘, "欢迎使用博客园阅读器(reader 开发)".center(88), ‘|‘) 141 print(‘+‘, ‘--‘ * 50, ‘+‘) 142 print(‘|‘, "[1]:开始阅读".center(95), ‘|‘) 143 print(‘|‘, "[2]:关于作者".center(95), ‘|‘) 144 print(‘|‘, "[Q]:退出软件".center(95), ‘|‘) 145 print(‘+‘, ‘--‘ * 50, ‘+‘) 146 147 cmd = input("请输入操作编号[1、2、Q]:") 148 if cmd == ‘1‘: 149 self.readopt() 150 elif cmd == ‘2‘: 151 self.aboutopt() 152 elif cmd == ‘Q‘ or cmd == ‘q‘: 153 break 154 155 os.system("cls") 156 157 print("已退出,欢迎使用!") 158 159 160 if __name__ == "__main__": 161 obj = CnBlogs() 162 obj.start()
标签:std 查看 tail ring print 跳转 时间 重写 web
原文地址:https://www.cnblogs.com/reader/p/11487398.html
