标签:size kernel nta des read 技术 make desc mmu
? Linux内核采用页式储存管理。虚拟地址被划分为固定大小的页面,由MMU在运行时将虚拟地址映射为某个物理内存页面的地址。与段式存储管理相比,页式存储管理由许多优点,首先页面大小式固定的,便于管理;更重要的是,要将一部分物理空间的内容换出到磁盘上时,在段式储存管理中要将整个段存出,而页式存储管理则按页进行,效率要高出许多。
? 在i386CPU中,不管程序怎么写的,i386CPU一律对程序中使用的地址先进行段式映射,然后才进行页式映射。在ELF格式的可执行代码中,ld总是从0x80000000开始安排程序的“代码段”,对每个程序都这样。至于程序在执行时在物理内存中的实际位置要==由内核在为其安排内存映射时临时做出安排==,具体地址则取决于其分派到的物理内存页面。
? 假设程序正在运行,整个映射机制已经建立好,并且CPU正在执行call 8048368 <greeting>指令,要转移到虚地址0x0804836去,接下来是虚拟地址的映射过程:
??? 首先是段式映射阶段。由于0x0804836是一个程序的入口,更重要的是在运行过程中是由CPU的程序计数器EIP指向的,所以在代码段中。因此i386CPU使用代码寄存器CS的值作为段式映射的选择码。
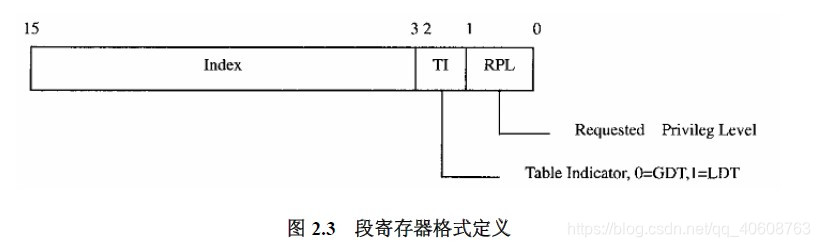
内核在建立一个进程时要将其段寄存器设置好,有关代码:
#define start_thread(regs, new_eip, new_esp)
do
{
__asm__("movl %0,%%fs ; movl %0,%%gs"
:
: "r"(0));
set_fs(USER_DS);
regs->xds = __USER_DS;
regs->xes = __USER_DS;
regs->xss = __USER_DS;
regs->xcs = __USER_CS;
regs->eip = new_eip;
regs->esp = new_esp;
} while (0)regs->xds是段寄存器DS的映像,余类推。我们可以发现,除了CS被设置为USE_CS外,其他的段寄存器都被设置成为了USER_DS,特别值得注意的是堆栈寄存器SS,它也被设置为USER_DS。也就是说,虽然Intel的意图是将一个进程的映像分为代码段、数据段、堆栈段,但Linux内核不买这个帐,在Linux内核中,数据和堆栈是不可分的。
USER_CS 和 USER_DS 的定义:
#define __KERNEL_CS 0x10
#define __KERNEL_DS 0x18
#define __USER_CS 0x23
#define __USER_DS 0x2B将其展开

事实上Linux中基本上从不使用LDT。用户的程序是在用户状态下进行的,所以创建进程时将CS初始化为__USER_CS。CPU以4为下标,从全局段描述表GDT中找对应的段描述项。
初始GDT内容在arch/i386/kernel/head.S中定义:
/*
* This contains typically 140 quadwords, depending on NR_CPUS.
*
* NOTE! Make sure the gdt descriptor in head.S matches this if you
* change anything.
*/
ENTRY(gdt_table)
.quad 0x0000000000000000 /* NULL descriptor */
.quad 0x0000000000000000 /* not used */
.quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at 0x00000000 */
.quad 0x00cf92000000ffff /* 0x18 kernel 4GB data at 0x00000000 */
.quad 0x00cffa000000ffff /* 0x23 user 4GB code at 0x00000000 */
.quad 0x00cff2000000ffff /* 0x2b user 4GB data at 0x00000000 */
.quad 0x0000000000000000 /* not used */
.quad 0x0000000000000000 /* not used */下面将4个段描述项的内容按二进制展开如下:


由此看来,要不是i386CPU中的MMU规定先做段式映射,然后才能做页式映射,就根本不需要段描述项和段寄存器了。Linux内核在此只不过是装模做样糊弄CPU而已,段式映射的结果就是将0x08048360映射到了自身0x08048368,现在作为象形地址出现了。
??? 下面才进入到了页式映射的过程。与段式映射过程中所有进程全都用一个GDT不一样,每个进程都有其自身的页面目录PGD,指向这个目录的指针保存在每个进程的mm_struct数据结构中。
每当调度一个进程进行运行时,内核都要为即将运行的进程设置好控制寄存器CR3,而MMU硬件总是从CR3取得指向当前页面目录的指针。但是CPU在运行时使用虚拟地址,而MMU使用物理地址。这是在inline函数switch_mm()中完成的:
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next, struct task_struct *tsk,
unsigned cpu)
{
...
asm volatile("movl %0,%%cr3": :"r"(__pa(next->pgd)));//next->pgd 表示下一个进程的页面目录起始地址。
...
}进程的切换是在内核态下进行的,不管什么进程,一旦就如内核就进入了系统空间,都有相同的页面映射,所以在改变了CR3后程序仍然可以照常运行。
具体过程参照Intel X86 CPU 内存管理里的页面映射过程:
标签:size kernel nta des read 技术 make desc mmu
原文地址:https://www.cnblogs.com/LiShiZhen/p/11494453.html