标签:详情 login file 店铺 tomat 计算机网络 一段 search jieba分词
本文主要讨论的是通过爬取天猫的销售数据和评论数据后,对数据进行清洗,并进行分析。流程大致为:1.通过selenium爬取销售数据; 2.通过selenium和re正则表达式爬取评论数据;3.通过pandas对数据进行清洗和分析;4.运用matplotlib和wordcount来进行可视化
故事要从上周四说起,J某人由于工作上的变动,暂时比较闲,难得能准时下班,结果在地铁上太挤,一不小心手机就点进了一篇名为《为了给女朋友买件心怡内衣,我用Python爬虫了天猫内衣售卖数据》。我这心一惊,爬虫是这么用的吗?这像话吗?当时,火气就上来了,一到家,开启电脑就准备对该文章大肆批判一番。文章内容大体如下:
研究天猫网站:对js,cookie进行分析
抓取天猫评论数据:用requests,beautifulsoup进行爬虫
存储、分析数据:用pandas,mysql进行存储和分析
可视化:用matplotlib和wordcount来进行可视化
考虑到,J某人是个毫无前端知识的统计学rookie,什么js,ajax,html,cookie,socket(这个计算机网络好像提过,可惜课水,基本都是翘课),听都没听过。只能他说啥,我就干啥,结果大事不妙,第一段都玩不下去。这不是欺负老实人吗?我这暴脾气就上来了。但细细一想,毕竟是ALI,人家的网站,人家说了算,说变就变。可是,我这蠢蠢欲动的求知欲就压不住了,刚好J某人曾试过给某护肤品做评论词的分析,就大笔一挥,把手上的东西改改,可能还能用。可是太晚了还是睡一觉再说。
第二天下了场大雨,本来打算和朋友吃饭的计划被取消了。结果下午,雨又停了,7点多时候朋友说已经快到了,J某人只能屁颠屁颠的从公司赶过去,两个单身的小伙子,很容易就聊到了这个话题,也是为了有个交代,小J开始写下了这篇文章。
本次实验,老夫爬了自己淘宝ID下,女士文胸类目下,综合页面下的前60款商品,爬虫主要分两步,第一步商品的销售数据,第二步商品的评论词。我们先来展示一下一些图表,分析一下结果吧。
2.1关于内衣商品的价格讨论
老夫将内衣的价格分为6个价格区间,进行讨论。从饼图和箱型图中,可以看出,在给老J推荐的60款商品中,价格主要集中在90-180元之间。平均价位在150左右。由于只有60款商品,得到的结论可能还需要看到文章的grils确认一下。(不存在的)
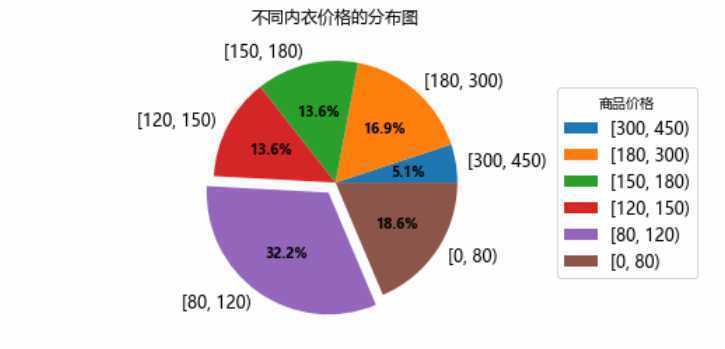
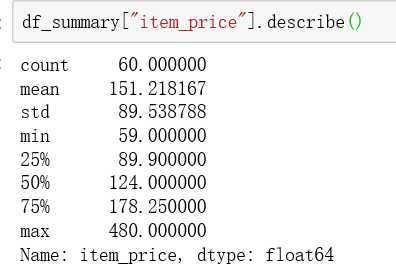
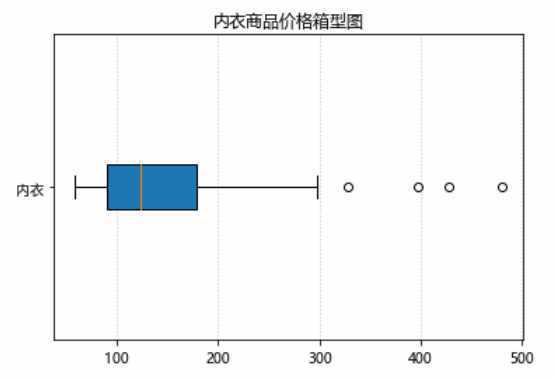
观察箱型图,似乎有那么几个异常值,让我们看看是啥。对于俺们这些俗人,只认识个维密。

2.2关于内衣销量的讨论
给J某人推荐的60款商品中,分别来自34家不同店铺。其中月销量过W的商品有10款,分别来自如下店铺:

而月销量过W的商品,如下:
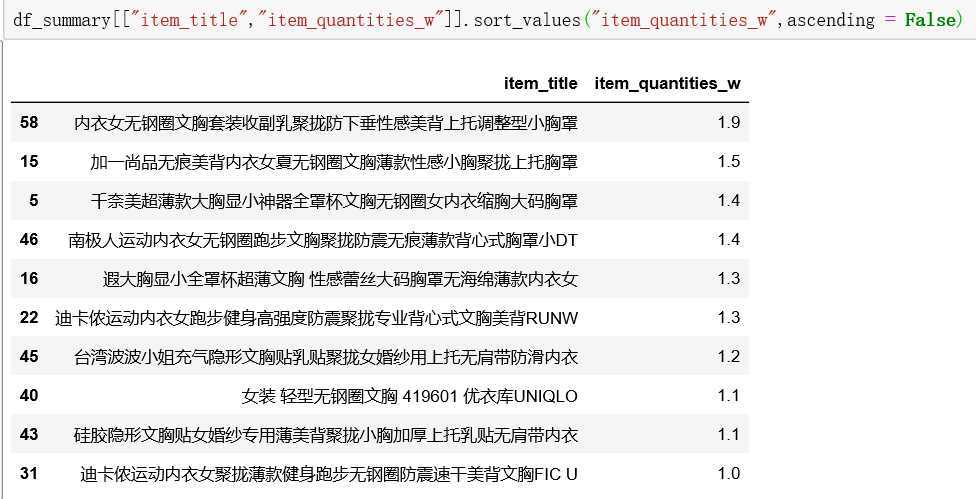
小J一脸的懵逼中。。。。。。
2.3关于内衣颜色的讨论
2.1和2.2的数据都是来自销售数据的爬取页面,接下来就是对60款商品详情页的评论词的数据的分析,默认我会爬取每款商品的前10页来做分析,不足10页的则按照当前能爬到的所有评论。该数据集的字段内容其实就是从用户的评论中提取出来的。从下面的截图,我们可以看出,对于一条评论呢,我们可以提取出的内容有商品ID、评价日期、 初次评价、 追评日期、 追加评论、 颜色、 规格、评论消费者、 会员等级几个字段。
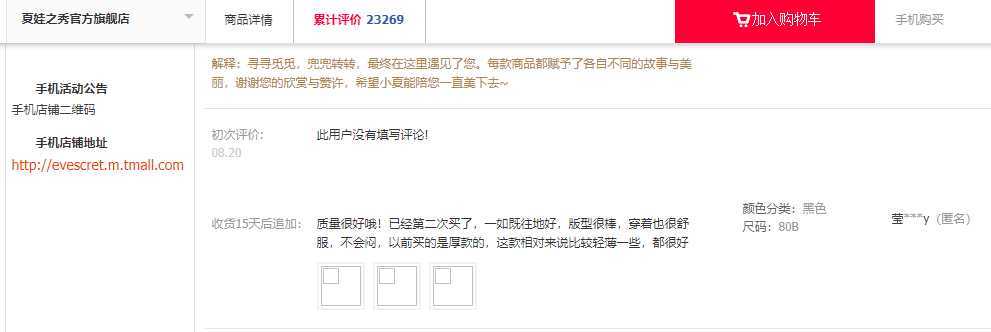
呐,提取出来就是这样

本次,我们将讨论的是60款商品的11570条评论,其中追加评论1000条(刚好),超级会员占到38%,数据未清洗前,出现频率最高的颜色为肤色,规格为75B.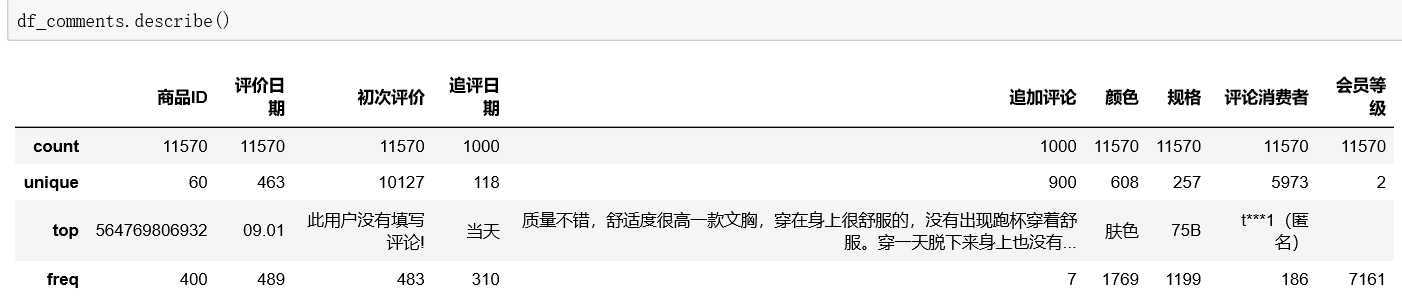
我们一起来看看跟颜色相关的东西,嘿嘿~~~,可以明显看到肤色和黑色占了半壁江山,其他常见的颜色还有灰、粉、白、红、紫、蓝、绿等。行吧,大开眼界了。
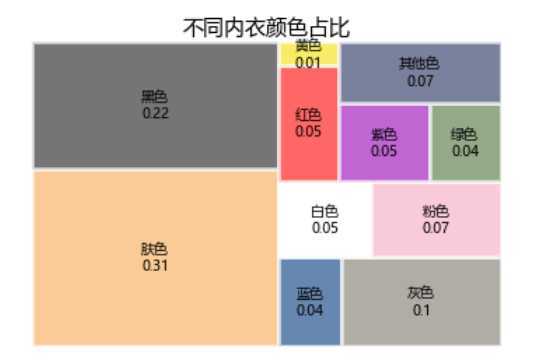
2.4关于内衣规格的讨论
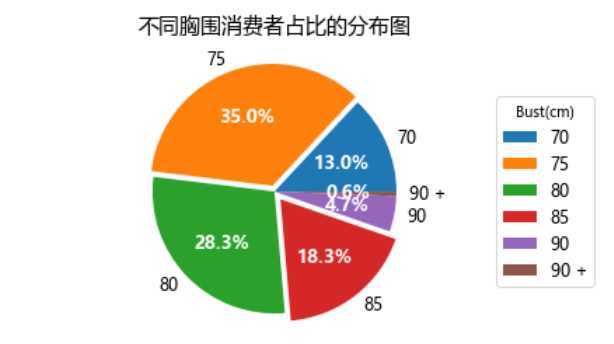
事实上,鄙人在分析时,会从规格字段中提取出两部分数据,如出现频率最高的75B,会提取出胸围75和罩杯B两个字段。分析的结果大致如下,话说我还是纯洁的颜色对吧。
可以看到胸围主要集中在75和80附近,超过了60%,还没到的妹子们加油了。而90及以上为5%左右。
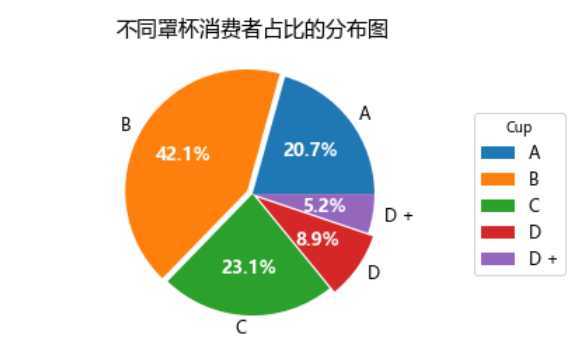
我们同样来看看罩杯的分布。Bcup的还是主流,占到42%,A和C的各占20%,D和D+占到差不多15%。
2.5评论词云
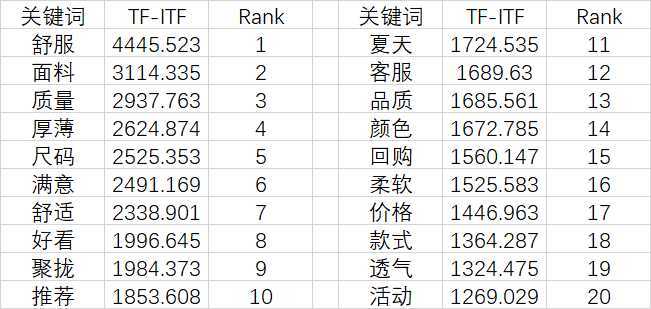
来画一个喜闻乐见的词云图,我们就用Jieba分词和wordcount来画词好了。在定义了一大堆乱七八糟的停止词和user_dict后,我就用计算后的TF-ITF的值来做词云好了,我们可以看到,用户在评论内衣时,比较在意的是无非是舒适感,外观,尺码,外观和价格等。


爬虫大致分三步,1.登录淘宝账号;2.爬销售数据;3爬评论数据。这一部分主要用到selenium的webdriver。
3.1登录部分
在60秒内输入账号,密码登录,很遗憾,保存下来的cookies在新开的浏览器里,用不了。

def get_driver(executable_path): options = webdriver.ChromeOptions() options.add_argument(‘lang=zh_CN.UTF-8‘) options.add_argument("–disable-javascript") options.add_argument("‘user-agent‘=‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36‘") prefs= { "profile.managed_default_content_settings.images":2, "profile.content_settings.plugin_whitelist.adobe-flash-player":2, "profile.content_settings.exceptions.plugins.*,*.per_resource.adobe-flash-player":2, } options.add_experimental_option("prefs", prefs) #这个才是重点,貌似不设置这个的话,selenium会直接被ALI识别出来, options.add_experimental_option("excludeSwitches",["enable-automation"]) driver = webdriver.Chrome(chrome_options=options,executable_path=executable_path) driver.get("https://login.taobao.com") time.sleep(60) print("登录成功。。。") pickle.dump(driver.get_cookies(), open("cookies.pkl", "wb")) cookies_list = pickle.load(open("cookies.pkl", "rb")) for cookie in cookies_list: cookie_dict = { "domain": "tmall.com", # 火狐浏览器不用填写,谷歌要需要 ‘name‘: cookie.get(‘name‘), ‘value‘: cookie.get(‘value‘), "expires": "", ‘path‘: ‘/‘, ‘httpOnly‘: False, ‘HostOnly‘: False, ‘Secure‘: False} driver.add_cookie(cookie_dict) return driver
3.2爬取销售数据
在爬取销售数据的时候,建议还是用beautifulsoup或者pq来做,直接用webdriver来找真的太慢了。我们在账号登录的情况下进入http://list.tmall.com/search_product.htm?cat=50095659,就可以开始爬取与文胸相关的销售数据。(关掉图片会提升爬取的效率)
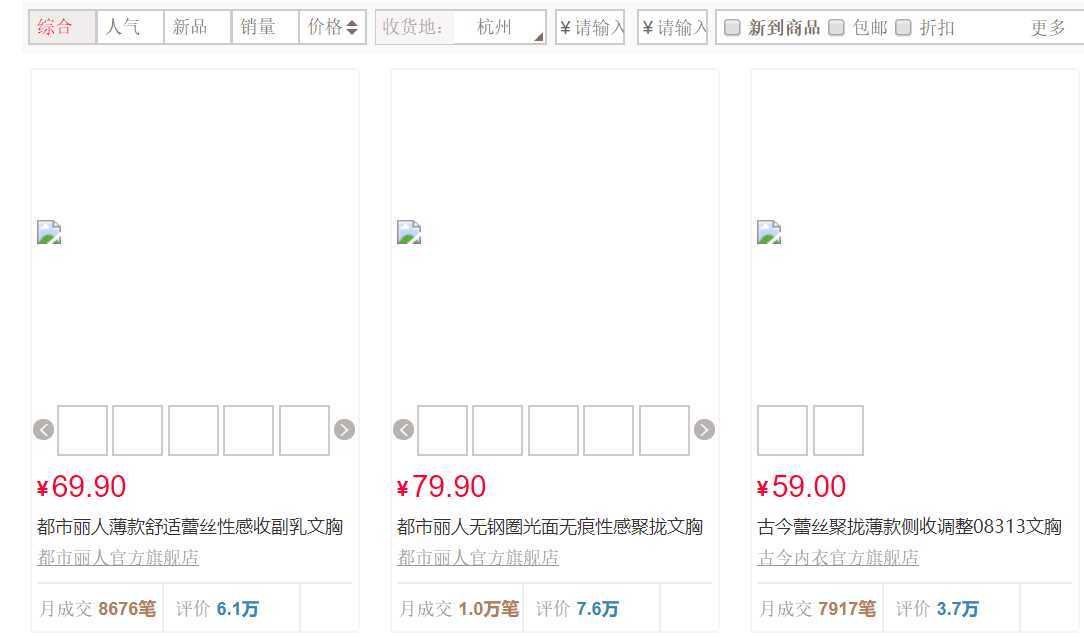
我们以第一款商品为例。可以得到商品的详情页链接,商品图片链接(这个还满有收藏价值的),商品价格,商品标题,店铺详情页链接,店铺名称,商品月销量,评价数,和评论页链接(我这次是用详情页做的,下次可以试试用评论页链接)
driver.get("http://list.tmall.com/search_product.htm?cat=50095659") data_summary = [] elements = driver.find_elements_by_class_name("product-iWrap") for element in elements: item_href = element.find_element_by_class_name("productImg").get_attribute("href") #item_img = element.find_element_by_tag_name("img").get_attribute("src") item_img = re.search("//(img.*.jpg)",element.find_element_by_tag_name("img").get_attribute(‘outerHTML‘)).groups()[0] item_price = element.find_element_by_xpath("./p[@class=‘productPrice‘]/em").get_attribute("title") item_title = element.find_element_by_xpath("./p[@class=‘productTitle‘]/a").get_attribute("title") store_href = element.find_element_by_xpath("./div[@class=‘productShop‘]/a[@class=‘productShop-name‘]").get_attribute("href") try: store_name = element.find_element_by_xpath("./p[@class=‘productStatus‘]/span[3]").get_attribute("data-nick") item_quantities = element.find_element_by_xpath("./p[@class=‘productStatus‘]/span").text comments_num = element.find_element_by_xpath("./p[@class=‘productStatus‘]/span[2]").text comments_herf = element.find_element_by_xpath("./p[@class=‘productStatus‘]/span[2]/a").get_attribute("href") except NoSuchElementException: store_name = element.find_element_by_xpath("./div[@class=‘productShop‘]/a[@class=‘productShop-name‘]").text item_quantities = "null" comments_num = "null" comments_herf = "null" data_summary.append([item_href,item_img,item_price,item_title,store_href,store_name,item_quantities,comments_num,comments_herf])
3.3爬取评论数据
这一部分,其实没什么难度,但由于ALI的反爬,经常会没看几页,就被发现,不让爬,所以一方便要限制速度,一方面要注意伪装。
def swipe_down(driver,second): #先控制好翻页的动作 for i in range(int(second/0.2)): #根据i的值,模拟上下滑动 if(i%2==0): js = ‘window.scrollBy(0,{})‘.format(30+50*i) else: js = ‘window.scrollBy(0,{})‘.format(40 * i) driver.execute_script(js) time.sleep(np.random.randint(1,3)*0.2)
def get_comment(driver,url,page=100): driver.get(url) time.sleep(3) try: WebDriverWait(driver, 20, 10).until(EC.presence_of_element_located((By.XPATH, ‘//*[@id="J_TabBar"]/li[2]/a‘))).click() except TimeoutException: driver.refresh() swipe_down(driver, random.randint(2, 4)) WebDriverWait(driver, 20, 15).until(EC.presence_of_element_located((By.XPATH, ‘//*[@id="J_TabBar"]/li[2]/a‘))).click() except ElementClickInterceptedException: point = driver.find_element_by_xpath(‘//*[@id="J_TabBar"]/li[2]/a‘) ActionChains(driver).move_to_element(point).perform() time.sleep(2) driver.execute_script("arguments[0].click();", point) comments_list = [] comments_list.append(url) page_num = 0 for i in range(page): swipe_down(driver, random.randint(1, 4)) comment_list = [] for i in driver.find_elements_by_xpath(‘//*[@id="J_Reviews"]/div/div[6]/table/tbody/tr‘): comment_list.append(i.text) comments_list.append(comment_list) button = None try: button = driver.find_element_by_xpath(‘//div[@class="rate-paginator"]/a[text()= "下一页>>"]‘) except NoSuchElementException: print("没找到,是不是页数不到{}".format(i)) break driver.execute_script("arguments[0].scrollIntoView();", button) driver.execute_script(‘window.scrollBy(0,{})‘.format(np.random.randint(1,4)*(-200))) ActionChains(driver).move_to_element(button).perform() driver.execute_script("arguments[0].click();", button) return comments_list
爬取评论的话,用以上的代码就能基本的实现,然后真正困难的是页面停留时间的配置,即如何躲过ALI的监控,不被识别成机器人,否则就会像下图一样被请去喝茶。
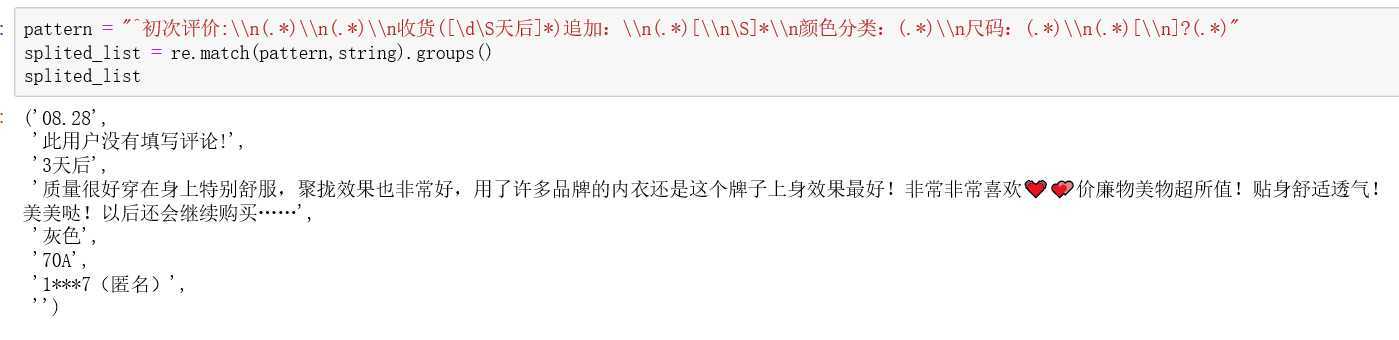
def split_comment(row): row = re.sub("解释:.*\\n","",row) row = re.sub("商品:","",row) row = re.sub("\\n服务:","",row) if row.startswith("初次评价:\n"): pattern = "^初次评价:\\n(.*)\\n(.*)\\n收货([\d\S天后]*)追加:\\n(.*)[\\n\S]*\\n颜色分类:(.*)\\n尺码:(.*)\\n(.*)[\\n]?(.*)" else: pattern = "(.*)\\n(.*)\\n颜色分类:(.*)\\n尺码:(.*)\\n(.*)[\\n]{0,1}(.*)" splited_list = re.match(pattern,row).groups() return [i for i in splited_list]
由于我们爬下来的是包含了所有和评论数据相关的一个字符串,我们需要用正则表达式把数据匹配出来。原来的评论词大致是这个样子:

提取之后,我们就可以的到相应的字段,
pease&love
J某人对自己说的话
考虑到J某人是个空有颜值,却没什么才华和毅力的人,所以开始写文章,既是记录自己的进步,也是警醒自己别停下来。这半年真的让自己产生了挫败感,也让J第一次有成为累赘的感觉。所以如果有一天我停下来了,就说明了我溜回去和爸妈学做小生意去了。最近在看matplotlib的书,和一本NLP的入门书,到时候看哪本能看完,就写哪个方向的文章,大概率下一篇文章在可能在国庆节(饼还是要画的)。
前段时间有一首歌叫做HeyKong,觉得自己给自己写信是件很帅的事情,于是我也想给自己说3句话:
1.你只是长的像吴彦祖,你的内心是郭靖,是狄云; 2.变通; 3.你还是那个在消防演练时,大喊晚辈明教教主张无忌,如果各位信得过在下的就跳下来的帅小伙。
标签:详情 login file 店铺 tomat 计算机网络 一段 search jieba分词
原文地址:https://www.cnblogs.com/307825064j/p/11493638.html
