标签:python字典 代码量 输入 单元素 步骤 问题 搜索 生成式 16px
现在,越来越多的公司面试以及考验面试对算法要求都提高了一个层次,从现在,我讲每日抽出时间进行5+1算法题讲解,5是指基础题,1是指1道中等偏难。希望能够让大家熟练掌握python的语法结构已经一些高级函数的应用。这些题目是在某些刷题的网站上登记的有水平的题目。这里如果有需要input的简单题,就略去了输出结果。如果时间充裕,则就会增加每日更多习题。
一:基础算法题10道
1.判断用户输入的年份是否为闰年
题目解析:
(1)问题分析:能被4整除但不能被100整除的年份为普通闰年,能被400整除的年份为世纪闰年,判断是否满足上述情况。
(2)算法分析:输入一个数,先判断如果是400的倍数,则满足;如果不是400的倍数,再判断如果该数能够被4整除,却不能被100整除,则满足。
(3)用到的python语法:input()标准输入函数,if判断语句,or,and逻辑运算符。
(4)博主答题代码:
n = int(input(‘请输入年份:‘)) if n % 400 == 0 or n % 4 == 0 and n % 100 != 0: print(‘{0}是闰年‘.format(n)) else: print(‘{0}不是闰年‘.format(n))
(5)高效方法:
python 的 calendar 库中已经封装好了一个方法 isleap() 来实现这个判断是否为闰年:
import calendar n = int(input("请输入年份:")) year = calendar.isleap(n) if year == True: print ("{0}是闰年".format(n)) else: print ("{0}不是闰年".format(n))
2.判断一个数是否是质数
题目解析:
(1)问题分析:除了1和它本身以外不再有其他的因数的数就是质数。
(2)算法分析:输入一个数,如果该数大于1,则从2开始循环到该数并一一整除该数,如果余数为0,则该数不是质数;否则该数是质数。
(3)用到的python语法:input()标准输入函数,for循环,if判断语句。
(4)博主答题代码:
n = int(input(‘‘)) if n > 1: for i in range(2,n): if n % i == 0: print(‘{0}不是质数‘.format(n)) print(‘{n}={a}*{b}‘.format(n=n,a=i,b=int(n/i))) # 这里也可为b=n//i break else: print(‘{0}是质数‘.format(n)) break
这时如果想把非质数的所有非1与自己的因数输出,则可以改为如下代码:
n = int(input(‘‘)) if n > 1: m1 = 0;m2 = 0 for i in range(2,n): if n % i == 0: str = ‘{0}不是质数‘.format(n) print(‘{n}={a}*{b}‘.format(n=n,a=i,b=int(n/i))) # 这里也可为b=n//i m1 = 1;m2 = 1 elif m1==0: print(‘{0}是质数‘.format(n)) break if [m1,m2].count(1) == 2: print(‘{0}不是质数‘.format(n))
(5)高效方法:
num = int(input("")) i = 2 while i < num: s = num % i if s == 0: break else: i += 1 if num == i: print("{0}是质数".format(num)) else: print("{0}不是质数".format(num))
3.输出指定范围内的素数
(1)题目分析:素数就是质,上一题已经介绍了如何求质数,这里我们需要加一个范围。
(2)算法分析:把上一题判断的内容放在一个for循环选择范围里进行分析。
(3)用到的python语法:input()标准输入函数,map函数,for循环,if判断语句。
(4)博主答题代码:
my_index1,my_index2 = map(int,input(‘请选择一个范围:‘).split(‘,‘)) result = [] for num in range(my_index1,my_index2+1): if num > 1: for i in range(2,num): if (num % i) == 0: break else: result.append(num) print(‘{a}到{b}所有的质数有:{c}‘.format(a = my_index1,b = my_index2,c = result))
这里的if和else是就近匹配,和上面的不同,这就避免了重复,这是要注意的一点。
展示这是最简单的方法,如果大家有好的方法,请评论。
4.约瑟夫生者死者小游戏
30 个人在一条船上,超载,需要 15 人下船。
于是人们排成一队,排队的位置即为他们的编号。
报数,从 1 开始,数到 9 的人下船。
如此循环,直到船上仅剩 15 人为止,问都有哪些编号的人下船了呢?
这一题可以扩展为:
m个人在一条船上,超载,需要n人下船。
于是人们排成一队,排队的位置即为他们的编号。
报数,从 1 开始,数到 k 的人下船。
如此循环,直到船上仅剩 m - n人为止,问都有哪些编号的人下船了呢?
(1)题目分析:
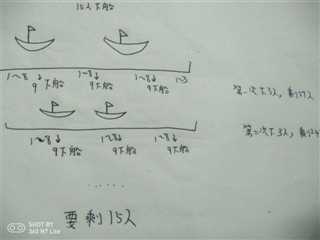
(2)算法分析:这里设置编号从1开始,先给出从1到m的所有编号,用一个列表表示,需要n个人下船,则船上就生了m-n个人。以此循环递归,其实也可以转化为递归问题。但这里每次递归,当找到数到编号k,就把编号k所在的序号,就是编号删除。这里可以设置一个外部变量,从第一个编号index开始,当index=k时,把编号重新置为1,每次都这样,直到循环完毕,直到所有最后剩余元素个数为m-n。
(3)用到的python语法:for循环,函数,列表操作,列表切片。
(4)博主答题代码:
def yueSeFu(m,n,k): serial_num = list(range(1,m +1)) # 创建从1到m的序号 index = 0 # 设置外部变量index while len(serial_num) > m - n: # 当最后剩余人数为m - n之前,一直进行下面的程序 for i in serial_num: # 遍历每个编号 index += 1 # 把外部变量index进行真实遍历 if index == k: # 当外部变量index找到k时,进行下面代码块的操作 serial_num.remove(i) # 移除需要下船的人的编号 index = 1 # 这时候index已经找到序号k了,就要重新遍历 print(‘{0}号人下船了‘.format(i)) if __name__ == ‘__main__‘: # 传入起始人数m,需要下船的人数n,数到多少下船的序号k,这里可自行设置 yueSeFu(30,15,9)
(5)高效方法:
def yueSeFu(m,n,k): people = list(range(1, m+1)) i = 0 while len(people) > m - n: i += (k - 1) if i >= len(people): i -= len(people) print("{}号下船了".format(people[i])) del people[i] if __name__ == ‘__main__‘: # 传入起始人数m,需要下船的人数n,数到多少下船的序号k yueSeFu(30,15,9)
5.二分查找,返回某个值在数组中的索引
(1)题目分析:二分搜索是一种在有序数组中查找某一特定元素的搜索算法。从数组的中间元素开始,正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
(2)算法分析:这里重复查找需要用到递归,用到一个一维数组,先判断数组查找的元素末尾下标是否大于等于1。如果是的话,就要先找到中间位置,如果大于中间位置,就只比较左边的元素重新递归;如果小于中间位置,则比较右边的元素重新递归。找不到就返回-1。
(3)用到的python语法:if判断语句,函数,递归算法。
(4)博主答题代码:
def twoSearch(x,arr,begin,end): # x为要查询的元素,arr为数组,begin和and是每次查找的范围 if end >= 1: mid = int(begin + (end-1)/2) # 每次范围的元素中间位置 if int(arr[mid]) == x: return mid elif int(arr[mid]) > x: # 元素小于中间的元素,需要比较左边的元素 return twoSearch(x,arr,begin,end - 1) else: # 元素大于中间的元素,需要比较右边的元素 return twoSearch(x,arr,begin + 1,end) else: return -1 if __name__ == ‘__main__‘: my_arr = list(map(int,input(‘请输入数组:‘).split(‘,‘))) # 返回可迭代对象 my_x = int(input(‘请输入要查找的元素:‘)) result = twoSearch(my_x, my_arr, 0, len(my_arr) - 1) if result != -1: print(‘元素在数组中的索引为:{0}‘.format(result)) else: print(‘元素不在数组中‘)
二:中等算法题2道
1.两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
(1)算法解析:我们给出一个列表,进行两次循环,就可以得到结果。
(2)博主代码:
def twoSum(nums, target): for index1,i in enumerate(nums): for index2,j in enumerate(nums): if i+j == target and i != j: return index1,index2 a = list(map(int,input().split(‘,‘))) b = int(input()) print(list(twoSum(a,b)))
主要代码为:
for index1,i in enumerate(nums): for index2,j in enumerate(nums): if i+j == target and i != j: return index1,index2
(3)代码问题
但是在运行很多个数字的列表中,需要两次循环遍历列表,如果列表的长度为n,则时间复杂度为O(n),时间执行效率太差,最差为O(n^2),故上面的代码实际上是不太可取的。
(4)高级算法
下面有一些改进的高级一点的算法:
列表生成式三行代码搞定:
for i in range(len(nums)): # 循环遍历列表 # 这里是用和减去列表中的某一元素,并且两个元素下标不同,就返回两个下标 if(target-nums[i] in nums and i != nums.index(target-nums[i])): return [i,nums.index(target-nums[i])]
执行用时 :1284ms,内存消耗 :14.7MB左右,比上面的代码节省了一层循环遍历的过程。
字典查找,利用哈希表,不用遍历:
my_dict = {} # 创建一个字典
for index, num1 in enumerate(nums): # 利用函数enumerate输出列表或数组的下标和元素
num2 = target - num1 # 另一个元素
# 这里是判断,如果字典中有另一个元素值的话,返回下标,以及该元素下标
# 这里由于字典是键值对,就避免了两个元素和符合,单元素是同一个元素的情况
if num2 in my_dict:
return [my_dict[num2], index]
# 把字典中的元素对应于键
my_dict[num1] = index
return -1
执行用时 :68ms,内存消耗 :15 MB左右,时间效率更高。
利用集合进行操作,效率和字典差不多:
my_set = set(nums) for i, v in enumerate(nums): if (target - v) in my_set and i != nums.index(target - v): return [i, nums.index(target - v)]
执行用时 :80ms,内存消耗 :15 .2MB左右。
总结:
1.用python字典或集合的效率要高很多,不建议常用列表。
2.生成一个整数序列可以先生成一个可迭代对象
比如生成一个只有整数的可迭代对象:
map(int,input(‘请选择一个范围:‘).split(‘,‘))
3.calendar.isleap(n可以判断是否为闰年。
4.列表生成式常用可以减少代码量,当然是有必要用列表的时候。
5.enumerate对既需要元素和下标值的序列很有用。
标签:python字典 代码量 输入 单元素 步骤 问题 搜索 生成式 16px
原文地址:https://www.cnblogs.com/ITXiaoAng/p/11507516.html