标签:ret list 工具 mic msu 生产 名称 线程 函数式
关于 响应式 Reactive,前面的两篇文章谈了不少概念,基本都离不开下面两点:
有兴趣的朋友可以看看这两篇文章:
Reactive(1) 从响应式编程到“好莱坞”
Reactive(2) 响应式流与制奶厂业务
这次,我们把目光转向 SpringBoot,在SpringBoot 2.0版本之后,提供了对响应式编程的全面支持。
因此在升级到 2.x版本之后,便能方便的实现事件驱动模型的后端编程,这其中离不开 webflux这个模块。
其同时也被 Spring 5 用作开发响应式 web 应用的核心基础。 那么, webflux 是一个怎样的东西?
Webflux
Webflux 模块的名称是 spring-webflux,名称中的 Flux 来源于 Reactor 中的类 Flux。
该模块中包含了对 响应式 HTTP、服务器推送 和 WebSocket 的支持。
Webflux 支持两种不同的编程模型:
@RestController
public class EchoController {
@GetMapping("/echo")
public Mono<String> sayHelloWorld() {
return Mono.just("Echo!");
}
}这两种编程模型只是在代码编写方式上存在不同,但底层的基础模块仍然是一样的。
除此之外,Webflux 可以运行在支持 Servlet 3.1 非阻塞 IO API 的 Servlet 容器上,或是其他异步运行时环境,如 Netty 和 Undertow。
关于Webflux 与 SpringMVC 的区别,可以参考下图:
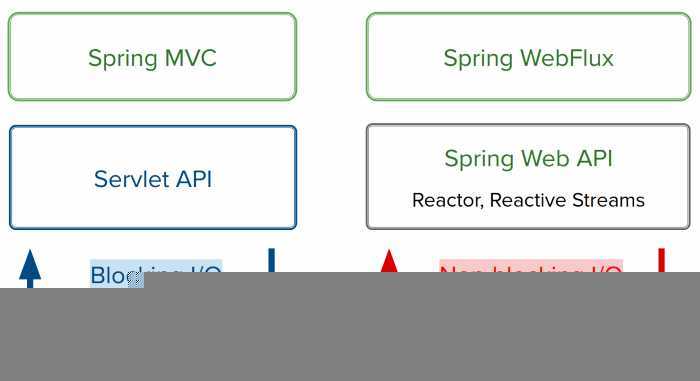
SpringBoot、Webflux、Reactor 可以说是层层包含的关系,其中,响应式能力的核心仍然是来自 Reactor组件。
由此可见,掌握Reactor的用法 必然是熟练进行 Spring 响应式编程的重点。
在理解响应式Web编程之前,我们需要对Reactor 两个核心概念做一些澄清,一个是Mono,另一个是Flux。
Flux 表示的是包含 0 到 N 个元素的异步序列。在该序列中可以包含三种不同类型的消息通知:
当消息通知产生时,订阅者中对应的方法 onNext(), onComplete()和 onError()会被调用。
Mono 表示的是包含 0 或者 1 个元素的异步序列。该序列中同样可以包含与 Flux 相同的三种类型的消息通知。
Flux 和 Mono 之间可以进行转换,比如对一个 Flux 序列进行计数操作,得到的结果是一个 Mono
Reactor提供了非常方便的API来创建 Flux、Mono 对象,如下:
使用静态工厂类创建Flux
Flux.just("Hello", "World").subscribe(System.out::println);
Flux.fromArray(new Integer[] {1, 2, 3}).subscribe(System.out::println);
Flux.empty().subscribe(System.out::println);
Flux.range(1, 10).subscribe(System.out::println);
Flux.interval(Duration.of(10, ChronoUnit.SECONDS)).subscribe(System.out::println);除了上述的方式之外,还可以使用 generate()、create()方法来自定义流数据的产生过程:
generate()
Flux.generate(sink -> {
sink.next("Echo");
sink.complete();
}).subscribe(System.out::println);generate 只提供序列中单个消息的产生逻辑(同步通知),其中的 sink.next()最多只能调用一次,比如上面的代码中,产生一个Echo消息后就结束了。
create()
Flux.create(sink -> {
for (char i = 'a'; i <= 'z'; i++) {
sink.next(i);
}
sink.complete();
}).subscribe(System.out::print);create 提供的是整个序列的产生逻辑,sink.next()可以调用多次(异步通知),如上面的代码将会产生a-z的小写字母。
使用静态工厂类创建Mono
Mono 的创建方式与 Flux 是很相似的。 除了Flux 所拥有的构造方式之外,还可以支持与Callable、Runnable、Supplier 等接口集成。
参考下面的代码:
Mono.fromSupplier(() -> "Mono1").subscribe(System.out::println);
Mono.justOrEmpty(Optional.of("Mono2")).subscribe(System.out::println);
Mono.create(sink -> sink.success("Mono3")).subscribe(System.out::println);在Reactive(1) 从响应式编程到“好莱坞” 一文中曾经提到过缓冲(buffer)的概念。
buffer 是流处理中非常常用的一种处理,意思就是将流的一段截停后再做处理。
比如下面的代码:
Flux.range(1, 100).buffer(20).subscribe(System.out::println);
Flux.interval(Duration.of(0, ChronoUnit.SECONDS),
Duration.of(1, ChronoUnit.SECONDS))
.buffer(Duration.of(5, ChronoUnit.SECONDS)).
take(2).toStream().forEach(System.out::println);
Flux.range(1, 10).bufferUntil(i -> i % 2 == 0).subscribe(System.out::println);
Flux.range(1, 10).bufferWhile(i -> i % 2 == 0).subscribe(System.out::println);第一个buffer(20)是指凑足20个数字后再进行处理,该语句会输出5组数据(按20分组)
第二个buffer(Duration duration)是指凑足一段时间后的数据再近些处理,这里是5秒钟做一次处理
第三个bufferUtil(Predicate p)是指等到某个元素满足断言(条件)时进行收集处理,这里将会输出[1,2],[3,4]..这样的奇偶数字对
第四个bufferWhile(Predicate p)则仅仅是收集满足断言(条件)的元素,这里将会输出2,4,6..这样的偶数
与 buffer 类似的是window函数,后者的不同在于其在缓冲截停后并不会输出一些元素列表,而是直接转换为Flux对象,如下:
Flux.range(1, 100).window(20)
.subscribe(flux ->
flux.buffer(5).subscribe(System.out::println));window(20)返回的结果是一个Flux
因此上面的代码会按5个一组输出:
[1, 2, 3, 4, 5]
[6, 7, 8, 9, 10]
[11, 12, 13, 14, 15]
...上面的bufferWhile 其实充当了过滤的作用,当然,对于流元素的过滤也可以使用filter函数来处理:
Flux.range(1, 10).filter(i -> i % 2 == 0).subscribe(System.out::println);take 函数可以用来提取想要的元素,这与filter 过滤动作是恰恰相反的,来看看take的用法:
Flux.range(1, 10).take(2).subscribe(System.out::println);
Flux.range(1, 10).takeLast(2).subscribe(System.out::println);
Flux.range(1, 10).takeWhile(i -> i < 5).subscribe(System.out::println);
Flux.range(1, 10).takeUntil(i -> i == 6).subscribe(System.out::println);第一个take(2)指提取前面的两个元素;
第二个takeLast(2)指提取最后的两个元素;
第三个takeWhile(Predicate p)指提取满足条件的元素,这里是1-4
第四个takeUtil(Predicate p)指一直提取直到满足条件的元素出现为止,这里是1-6
使用map函数可以将流中的元素进行个体转换,如下:
Flux.range(1, 10).map(x -> x*x).subscribe(System.out::println);这里的map使用的JDK8 所定义的 Function接口
某些情况下我们需要对两个流中的元素进行合并处理,这与合并两个数组有点相似,但结合流的特点又会有不同的需求。
使用zipWith函数可以实现简单的流元素合并处理:
Flux.just("I", "You")
.zipWith(Flux.just("Win", "Lose"))
.subscribe(System.out::println);
Flux.just("I", "You")
.zipWith(Flux.just("Win", "Lose"),
(s1, s2) -> String.format("%s!%s!", s1, s2))
.subscribe(System.out::println);上面的代码输出为:
[I,Win]
[You,Lose]
I!Win!
You!Lose!第一个zipWith输出的是Tuple对象(不可变的元祖),第二个zipWith增加了一个BiFunction来实现合并计算,输出的是字符串。
注意到zipWith是分别按照元素在流中的顺序进行两两合并的,合并后的流长度则最短的流为准,遵循最短对齐原则。
用于实现合并的还有 combineLastest函数,combinLastest 会动态的将流中新产生元素(末位)进行合并,注意是只要产生新元素都会触发合并动作并产生一个结果元素,如下面的代码:
Flux.combineLatest(
Arrays::toString,
Flux.interval(Duration.of(0, ChronoUnit.MILLIS),
Duration.of(100, ChronoUnit.MILLIS)).take(2),
Flux.interval(Duration.of(50, ChronoUnit.MILLIS),
Duration.of(100, ChronoUnit.MILLIS)).take(2)
).toStream().forEach(System.out::println);输出为:
[0, 0]
[1, 0]
[1, 1]与合并比较类似的处理概念是合流,合流的不同之处就在于元素之间不会产生合并,最终流的元素个数(长度)是两个源的个数之和。
合流的计算可以使用 merge或mergeSequential 函数,这两者的区别在于:
merge后的元素是按产生时间排序的,而mergeSequential 则是按整个流被订阅的时间来排序,如下面的代码:
Flux.merge(Flux.interval(
Duration.of(0, ChronoUnit.MILLIS),
Duration.of(100, ChronoUnit.MILLIS)).take(2),
Flux.interval(
Duration.of(50, ChronoUnit.MILLIS),
Duration.of(100, ChronoUnit.MILLIS)).take(2))
.toStream()
.forEach(System.out::println);
System.out.println("---");
Flux.mergeSequential(Flux.interval(
Duration.of(0, ChronoUnit.MILLIS),
Duration.of(100, ChronoUnit.MILLIS)).take(2),
Flux.interval(
Duration.of(50, ChronoUnit.MILLIS),
Duration.of(100, ChronoUnit.MILLIS)).take(2))
.toStream()
.forEach(System.out::println);
输出为:
0
0
1
1
---
0
1
0
1merge 是直接将Flux 元素进行合流之外,而flatMap则提供了更加高级的处理:
flatMap 函数会先将Flux中的元素转换为 Flux(流),然后再新产生的Flux进行合流处理,如下:
Flux.just(1, 2)
.flatMap(x -> Flux.interval(Duration.of(x * 10, ChronoUnit.MILLIS),
Duration.of(10, ChronoUnit.MILLIS)).take(x))
.toStream()
.forEach(System.out::println);flatMap也存在flatMapSequential的一个兄弟版本,后者决定了合并流元素的顺序是与流的订阅顺序一致的。
reduce 和 reduceWith 操作符对流中包含的所有元素进行累积操作,得到一个包含计算结果的 Mono 序列。累积操作是通过一个 BiFunction 来表示的。reduceWith 允许在在操作时指定一个起始值(与第一个元素进行运算)
如下面的代码:
Flux.range(1, 100).reduce((x, y) -> x + y).subscribe(System.out::println);
Flux.range(1, 100).reduceWith(() -> 100, (x, y) -> x + y).subscribe(System.out::println);这里通过reduce计算出1-100的累加结果(1+2+3+...100),结果输出为:
5050
5150在前面所提及的这些功能基本都属于正常的流处理,然而对于异常的捕获以及采取一些修正手段也是同样重要的。
利用Flux/Mono 框架可以很方便的做到这点。
将正常消息和错误消息分别打印
Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.subscribe(System.out::println, System.err::println);当产生错误时默认返回0
Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.onErrorReturn(0)
.subscribe(System.out::println);自定义异常时的处理
Flux.just(1, 2)
.concatWith(Mono.error(new IllegalArgumentException()))
.onErrorResume(e -> {
if (e instanceof IllegalStateException) {
return Mono.just(0);
} else if (e instanceof IllegalArgumentException) {
return Mono.just(-1);
}
return Mono.empty();
})
.subscribe(System.out::println);当产生错误时重试
Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.retry(1)
.subscribe(System.out::println);这里的retry(1)表示最多重试1次,而且重试将从订阅的位置开始重新发送流事件
我们说过,响应式是异步化的,那么就会涉及到多线程的调度。
Reactor 提供了非常方便的调度器(Scheduler)工具方法,可以指定流的产生以及转换(计算)发布所采用的线程调度方式。
这些方式包括:
| 类别 | 描述 |
|---|---|
| immediate | 采用当前线程 |
| single | 单一可复用的线程 |
| elastic | 弹性可复用的线程池(IO型) |
| parallel | 并行操作优化的线程池(CPU计算型) |
| timer | 支持任务调度的线程池 |
| fromExecutorService | 自定义线程池 |
下面,以一个简单的实例来演示不同的线程调度:
Flux.create(sink -> {
sink.next(Thread.currentThread().getName());
sink.complete();
})
.publishOn(Schedulers.single())
.map(x -> String.format("[%s] %s", Thread.currentThread().getName(), x))
.publishOn(Schedulers.elastic())
.map(x -> String.format("[%s] %s", Thread.currentThread().getName(), x))
.subscribeOn(Schedulers.parallel())
.toStream()
.forEach(System.out::println);
在这段代码中,使用publishOn指定了流发布的调度器,subscribeOn则指定的是流产生的调度器。
首先是parallel调度器进行流数据的生成,接着使用一个single单线程调度器进行发布,此时经过第一个map转换为另一个Flux流,其中的消息叠加了当前线程的名称。最后进入的是一个elastic弹性调度器,再次进行一次同样的map转换。
最终,经过多层转换后的输出如下:
[elastic-2] [single-1] parallel-1SpringBoot 2.x、Spring 5 对于响应式的Web编程(基于Reactor)都提供了全面的支持,借助于框架的能力可以快速的完成一些简单的响应式代码开发。
本文提供了较多 Reactor API的代码样例,旨在帮助读者能快速的理解 响应式编程的概念及方式。
对于习惯了传统编程范式的开发人员来说,熟练使用 Reactor 仍然需要一些思维上的转变。
就笔者的自身感觉来看,Reactor 存在一些学习和适应的成本,但一旦熟悉使用之后便能体会它的先进之处。 就如 JDK8 引入的Stream API之后,许多开发者则渐渐抛弃forEach的方式..
本身这就是一种生产效率的提升机会,何乐而不为? 更何况,从应用框架的发展前景来看,响应式的前景是明朗的。
使用 Reactor 进行反应式编程
https://www.ibm.com/developerworks/cn/java/j-cn-with-reactor-response-encode/index.html
Spring 5 的 WebFlux 开发介绍
https://www.ibm.com/developerworks/cn/java/spring5-webflux-reactive/index.html
5分钟理解 SpringBoot 响应式的核心-Reactor
标签:ret list 工具 mic msu 生产 名称 线程 函数式
原文地址:https://www.cnblogs.com/littleatp/p/11515458.html