标签:情况 dom arraylist 实现原理 方法 对比 int list() 函数
集合类存储在任何编程语言中都是很重要的内容,只因有这样的存储数据结构才让我们可以在内存中轻易的操作数据,那么在Java中这些存储类集合结构都有哪些?内部实现是怎么样?有什么用途呢?下面分享一些我的总结
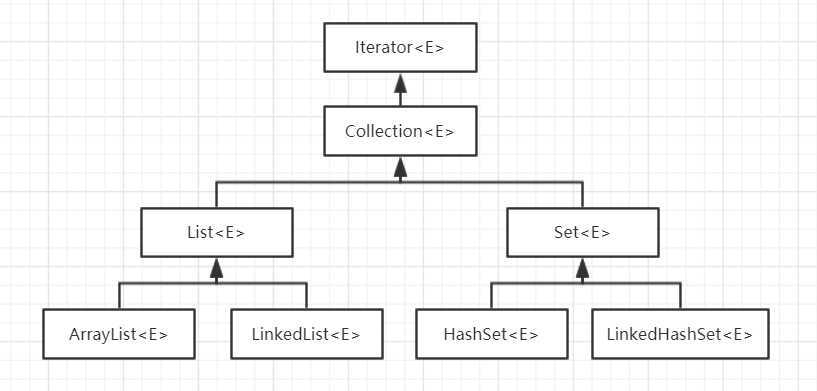
图中只列出了比较关键的继承关系,在Java中所有的集合类都实现Collection
注:
实现了List
ArrayList可以说是在Java开发的过程中是常用的存储结构了,通过名字大致可以猜到它的内部实现其实是通过数组来存储的。那究竟是不是这么回事呢?我们来一探究竟。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
查看源码我们发现这样一行代码transient Object[] elementData; 并且在对ArrayList进行初始化的时候也对这个属性进行了赋值操作。内部果然是采用Object数组存储的。既然内部是数组实现的,操作也和数组差不多,为什么不直接用数组呢?在Java中数组一旦定义长度既不可更改,而在ArrayList中数组的元素是可以随意添加的,在ArrayList内部默认使用的数组长度为10,当对List添加的元素个数超过10之后,会对数组进行扩容和对数据复制。每次在添加元素的时候,如果数组满了,就会触发扩容操作计算出一个新的数组容量并使用Arrays.copyOf操作(内部是通过System.arraycopy来操作的)对数据进行整体的复制
ArrayList既然内部是使用数组来实现的,也就继承了数组的特性:支持快速查找,但是对于添加和删除操作来说数组的性能会慢一些,在需要频繁进行添加和删除元素的场景下,会引起频繁的数组扩容和数据移动,降低性能。所以在读多写少的场景下非常合适。
和ArrayList同属于List
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient Node<E> first;
transient Node<E> last;
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public void addFirst(E e) {
linkFirst(e);
}
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
查看源码我们发现在LinkedList的内部维护了一个内部实现类Node结构用于存储列表中的元素,查看Node的代码不难看出,Node实现了是一个双向链表。既然是链表,那么LinkedList也就继承了链表的特性:查询性能低,但支持快速的添加和删除操作。故在需要进行频繁添加和删除操作的场景下,更为适用。与ArrayList是互斥的。
有时候我们需要判断列表中是否包含一个元素,我们会调用相应类型的Contains方法,而在Contains的实现内部则是使用存储的数据类型的equals方法来进行判等操作的。我们以ArrayList的源码为例
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}当被查找的元素不为null时,会调用元素的equals方法进行判等操作。在存储自定义类型的时候,比如自定义类Person,在判断元素是否存在的时候会调用Person的equals方法,默认情况下会比较两个元素的地址,对于不同的Person类实例,地址也不相同,这是没有意义的。所以我们需要进行重写equals方法来实现对Person的判等操作。
在我们开始讲集合的实现类之前,先来看一下HashMap这个结构,在集合实现类中无论是HashSet和LinkedHashSet内部的实现方式均是依赖于HashMap的。
//HashSet的内部实现部分代码
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//LinkedHashSet内部实现部分代码
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}HashMap实现Map<K,V>接口,存储的是键值对的映射关系,并不属于Collection
//HashMap的主要源码
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
transient Node<K,V>[] table;
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final float loadFactor;
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}源码中我们可以看到在HashMap的内部存储着一个内部类实例数组Node<K,V>[],默认情况下,这个数组的长度为16。除此之外还有一个Hash函数和一个装填因子。他们是做什么用的呢?我们先着重看一下Put方法,每次我们向HashMap的实例中添加元素的时候,都会对Key使用Hash函数计算出来一个整数hash值,然后和数组的长度进行运算得出一个索引值,这个索引值就是该元素应该在数组中的位置。如果这个位置并没有元素存在,则直接放置在该位置,如果该位置的元素已经存在,也被称为哈希碰撞,则使用单向链表的方式将元素连接起来。内部类Node<K,V>就是一个单向链表。当数组的容量超过(填装因子*容量)的时候,意味着hash表的存储非常臃肿,哈希碰撞会增多,会降低程序的性能(这里hash函数计算出hash值并且运算得到位置时间复杂度为O(1),如果在相同位置出现碰撞的次数越多就需要在链表中进行查找元素了,链表查找元素的时间复杂度是O(N),这会大大降低程序的性能),这个时候就需要对数组进行扩容,对所有元素进行迁移,这个过程也叫reHash。
我们在初始化HashMap的时候可以指定容量和填装因子,容量一定要是2的幂,填装因子的默认值为0.75。但是这里我不建议初始化的时候主动去设置这些值。因为这些值设置的是否合理直接影响到程序的性能,容量设置的大,浪费空间,容量设置的小,会导致哈希碰撞的次数增多,而且一旦超过了阈值(容量*填装因子)还会导致扩容和数据迁移,这对程序的性能会大打折扣。
HashMap给我们遍历它存储的元素暴露出一些有用的方法,最为常用的则为:entrySet() 方法返回键值对作为值的集合;keySet() 方法返回键的集合;并且在HashMap中的Key和Value都允许为null。
上面描述了List及其实现类的实现方式和用途,接下来我们对比看一下集合及其实现类的原理及用途。在某些场景下,我们存储的元素中不需要有重复,这个时候集合就派上了用场,例如维护爬虫爬取的链接。
我们先来看下集合的第一个主要实现类HashSet。
前面讲HashMap原理的时候,我们说过HashSet的内部存储就是靠HashMap来实现的,HashMap<K,V>是键值对的形式,而集合实现类并不存在这样的关系,所以在使用HashMap的过程中对于集合类而言,Value是不存储值的,默认情况下是个Object类型的null值。
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}HashSet在使用方式上除了和列表对比的那几点不同之外没有任何区别,具体的用途也可以根据它的特点来选择合适的使用场景。
LinkedHashSet继承自HashSet,只不过LinkedHashSet可以保证存入的顺序和取出的顺序是一样,是一个有序的集合。它是如何在HashSet的基础上实现的呢?老规矩,源码走起
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}原来是这样:LinkedHashSet重写了newNode方法并且在内部维护了一个新的Entry类和一个双向链表,在每次创建新节点的时候都会对head,tail指针进行更新,就是这个双向链表保证集合元素在遍历的时候输出的结果就是插入时的顺序。除了这一点之外,用法和HashSet并无不同。
当我们需要判断一个元素是否存在于集合中或者是向集合中添加重复元素时,除了需要像列表一样重写equals方法外,还需要重写hashCode方法。在HashMap的内部,首先比对HashCode,如果这个值相等才会去比较equals。默认情况下HashCode是对地址的编码,和equals一样都和地址有关系,不重写的话这种比较是没有意义的。
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}本节介绍了关于Java泛型集合存储类一些常见的实现类及其原理和应用,上面介绍的所有的实现类均是线程不安全的。所以在多线程模式下访问需要注意这一点,并且需要对其操作进行额外的防护。
标签:情况 dom arraylist 实现原理 方法 对比 int list() 函数
原文地址:https://www.cnblogs.com/u-vitamin/p/11518677.html