标签:st算法 读取数据 基于 姓名 inf cache 参考 primary 状态
MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
在可能的情况下,应该尽量把字段设置为NOTNULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。
满足业务需求的前提下二三是个字段就是极限了,可以预留字段便于扩展。
字段值具有原子性,不能再分(所有关系型数据库系统都满足第一范式); 例如:姓名字段,其中姓和名是一个整体,如果区分姓和名那么必须设立两个独立字段;(字段不可分)。
一个表必须有主键,即每行数据都能被唯一的区分;备注:必须先满足第一范式;(有主键,非主键字段依赖主键。)
一个表中不能包涵其他相关表中非关键字段的信息,即数据表不能有沉余字段;备注:必须先满足第二范式;(非主键字段不能互相依赖)
MyISAM和Innodb比较

关键字与数据的映射关系称为索引(==包含关键字和对应的记录在磁盘中的地址==)。关键字是从数据当中提取的用于标识、检索数据的特定内容。
key)unique key)primary key)fulltext key)三种索引的索引方式是一样的,只不过对索引的关键字有不同的限制:普通索引:对关键字没有限制。唯一索引:要求记录提供的关键字不能重复。主键索引:要求关键字唯一且不为null
windows上是my.ini,linux上是my.cnf
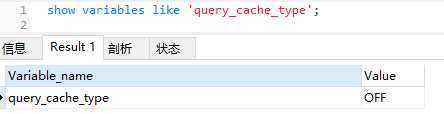
在[mysqld]段中配置query_cache_type:
select sql-no-cache提示来放弃缓存select sql-cache来主动缓存(==常用==)开启缓存之后设置缓存大小:set global query_cache_size=64*1024*1024;当数据表改动时,基于该数据表的任何缓存都会被删除。(表层面的管理,不是记录层面的管理,因此失效率较高)
query cache的使用情况。可以尝试使用,但不能由query cache决定业务逻辑,因为query cache由DBA来管理。一般情况下我们创建的表对应一组存储文件,使用MyISAM存储引擎时是一个.MYI和.MYD文件,使用Innodb存储引擎时是一个.ibd和.frm(表结构)文件。
当数据量较大时(一般千万条记录级别以上),MySQL的性能就会开始下降,这时我们就需要将数据分散到多组存储文件,保证其单个文件的执行效率。
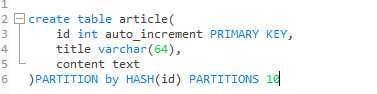
创建表示创建分区:
查看data目录:
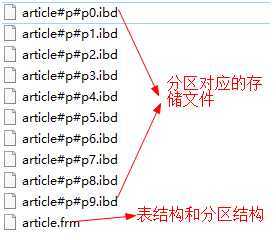
服务端的表分区对于客户端是透明的,客户端还是照常插入数据,但服务端会按照分区算法分散存储数据。
分区依据的字段必须是主键的一部分,分区是为了快速定位数据,因此该字段的搜索频次较高应作为强检索字段,否则依照该字段分区毫无意义。
hash(field)的性质一样,只不过key是==处理字符串==的,比hash()多了一步从字符串中计算出一个整型在做取模操作。in (值列表))。当数据表中的数据量很大时,分区带来的效率提升才会显现出来。
只有检索字段为分区字段时,分区带来的效率提升才会比较明显。因此,==分区字段的选择很重要==,并且==业务逻辑要尽可能地根据分区字段做相应调整==(尽量使用分区字段作为查询条件)。
在服务器架构时,为了保证服务器7x24不宕机在线状态,需要为每台单点服务器(由一台服务器提供服务的服务器,如写服务器、数据库中间件)提供冗余机。
对于写服务器来说,需要提供一台同样的写-冗余服务器,当写服务器健康时(写-冗余通过心跳检测),写-冗余作为一个从机的角色复制写服务器的内容与其做一个同步;当写服务器宕机时,写-冗余服务器便顶上来作为写服务器继续提供服务。对外界来说这个处理过程是透明的,即外界仅通过一个IP访问服务。
DDL(Database Definition Language)是指数据库表结构的定义(create table)和维护(alter table)的语言。在线上执行DDL,在低于MySQL5.6版本时会导致全表被独占锁定,此时表处于维护、不可操作状态,这会导致该期间对该表的所有访问无法响应。但是在MySQL5.6之后,支持Online DDL,大大缩短了锁定时间。
优化技巧是采用的维护表结构的DDL(比如增加一列,或者增加一个索引),是==copy==策略。思路:创建一个满足新结构的新表,将旧表数据==逐条==导入(复制)到新表中,以保证==一次性锁定的内容少==(锁定的是正在导入的数据),同时旧表上可以执行其他任务。导入的过程中,将对旧表的所有操作以日志的形式记录下来,导入完毕后,将更新日志在新表上再执行一遍(确保一致性)。最后,新表替换旧表(在应用程序中完成,或者是数据库的rename,视图完成)。
但随着MySQL的升级,这个问题几乎淡化了。
在恢复数据时,可能会导入大量的数据。此时为了快速导入,需要掌握一些技巧:
导入时先禁用索引和约束:alter table table-name disable keys
待数据导入完成之后,再开启索引和约束,一次性创建索引:alter table table-name enable keys
Innodb,那么它==默认会给每条写指令加上事务==(这也会消耗一定的时间),因此建议先手动开启事务,再执行一定量的批量导入,最后手动提交事务。prepare==预编译==一下,这样也能节省很多重复编译的时间尽量保证不要出现大的offset,比如limit 10000,10相当于对已查询出来的行数弃掉前10000行后再取10行,完全可以加一些条件过滤一下(完成筛选),而不应该使用limit跳过已查询到的数据。这是一个==offset做无用功==的问题。对应实际工程中,要避免出现大页码的情况,尽量引导用户做条件过滤。
即尽量选择自己需要的字段select,但这个影响不是很大,因为网络传输多了几十上百字节也没多少延时,并且现在流行的ORM框架都是用的select *,只是我们在设计表的时候注意将大数据量的字段分离,比如商品详情可以单独抽离出一张商品详情表,这样在查看商品简略页面时的加载速度就不会有影响了。
它的逻辑就是随机排序(为每条数据生成一个随机数,然后根据随机数大小进行排序)。如select * from student order by rand() limit 5的执行效率就很低,因为它为表中的每条数据都生成随机数并进行排序,而我们只要前5条。
解决思路:在应用程序中,将随机的主键生成好,去数据库中利用主键检索。
多表查询:join、子查询都是涉及到多表的查询。如果你使用explain分析执行计划你会发现多表查询也是一个表一个表的处理,最后合并结果。因此可以说单表查询将计算压力放在了应用程序上,而多表查询将计算压力放在了数据库上。
现在有ORM框架帮我们解决了单表查询带来的对象映射问题(查询单表时,如果发现有外键自动再去查询关联表,是一个表一个表查的)。
在MyISAM存储引擎中,会自动记录表的行数,因此使用count(*)能够快速返回。而Innodb内部没有这样一个计数器,需要我们手动统计记录数量,解决思路就是单独使用一张表:
如果可以确定仅仅检索一条,建议加上limit 1,其实ORM框架帮我们做到了这一点(查询单条的操作都会自动加上limit 1)。
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考。
配置项:slow_query_log。
可以使用show variables like ‘slov_query_log’查看是否开启,如果状态值为OFF,可以使用set GLOBAL slow_query_log = on来开启,它会在datadir下产生一个xxx-slow.log的文件
配置项:long_query_time
查看:show VARIABLES like ‘long_query_time‘,单位秒
设置:set long_query_time=0.5
实操时应该从长时间设置到短的时间,即将最慢的SQL优化掉。
一旦SQL超过了我们设置的临界时间就会被记录到xxx-slow.log中。
开启后,所有的SQL执行的详细信息都会被自动记录下来
max_connections,最大客户端连接数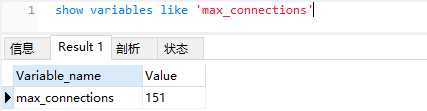
table_open_cache,表文件句柄缓存(表数据是存储在磁盘上的,缓存磁盘文件的句柄方便打开文件读取数据)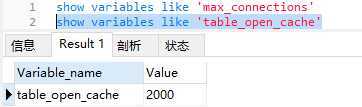
key_buffer_size,索引缓存大小(将从磁盘上读取的索引缓存到内存,可以设置大一些,有利于快速检索)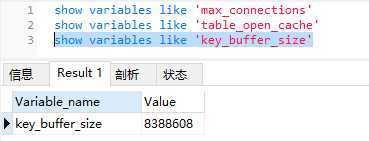
innodb_buffer_pool_size,Innodb存储引擎缓存池大小(对于Innodb来说最重要的一个配置,如果所有的表用的都是Innodb,那么甚至建议将该值设置到物理内存的80%,Innodb的很多性能提升如索引都是依靠这个)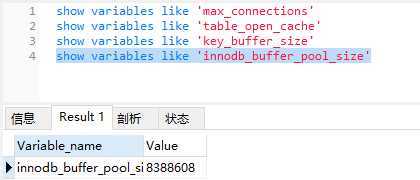
innodb_file_per_table(innodb中,表数据存放在.ibd文件中,如果将该配置项设置为ON,那么一个表对应一个ibd文件,否则所有innodb共享表空间)
标签:st算法 读取数据 基于 姓名 inf cache 参考 primary 状态
原文地址:https://www.cnblogs.com/woxbwo/p/11525330.html