标签:bec 信息 策略 flannel iptable 指定 友好 tab web服务
1.自动装箱: 能自动完成容器的部署,而不影响其可用性。
2.自我修复: 如果容器崩了,它可以在一秒钟启动。 没必要修复,在从起一个容器就行了。
3.水平扩展: 只要物理资源平台是足够的,就可以水平扩展
4.服务发现和负载均衡:
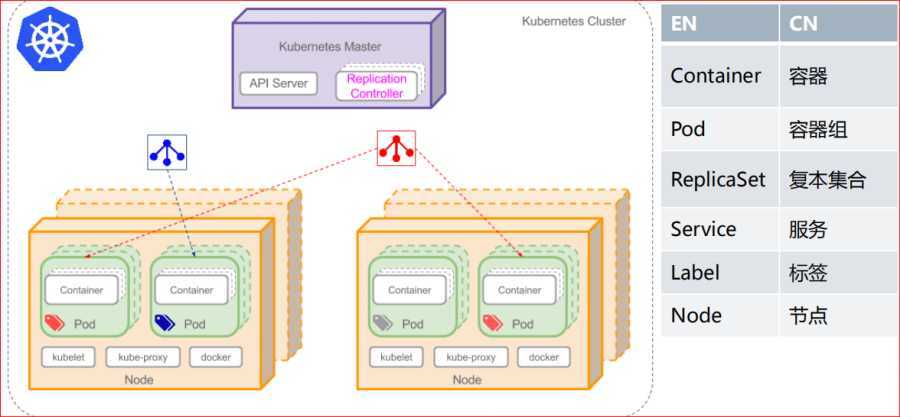
• master/node
• master节点上的组件 : API Server, Scheduler(调度器), Controller-Manager(控制器)
• node节点上的组件 : kubelet, docker, kube-proxy
• Pod, Label, Label Selector
• Label : key=value
• Label Selector :
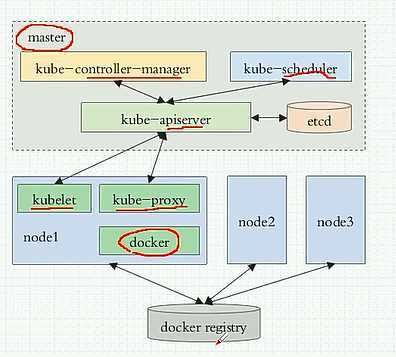
1.apiserver提供了资源对象的唯一操作入口,其它所有的组件都必须通过它提供的API来操作资源对象。
2.Controller Manager:集群内部的管理控制中心,主要目的是实现kubernetes集群的故障检测和自动回复等工作。
3.etcd:数据库,系统的所有状态都存储在这里。
4.scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
5.kubelet:负责维护容器的声明周期,同时也负责Volume (CVI) 和网络(CNI) 的管理。
6.Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
7.kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
• Pod 有两类:
• 自主式Pod (自我管理的,不建议这种)
• 控制器管理的Pod
• ReplicationController (副本控制器)
• ReplicaSet (副本集控制器)
• Deployment (管理无状态的应用)
• StatefulSet (有状态副本集控制器)
• DaemonSet (管理无状态的应用)
• Job, Ctonjob (作业)
Pod是K8S里最小的单位,是个虚拟的概念,其实就是指K8S里跑的一组docker容器,pod的设计理念是支持多个容器在一个pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。
Pod是kubernetes集群中所有业务类型的基础,可以看作运行在K8S集群中的小机器人,不同类型的业务就需要不同类型的小机器人去执行。目前K8S中的业务主要可以分为长期伺服型(long-running)、批处理型(batch)、节点后台支撑型(node-daemon) 和有状态应用型(stateful application); 分别对应的控制器为Deployment、Job、DaemonSet和PetSet。
Label是元数据信息,当然有很多种,Label只是其中一种元数据是k-v类型的数据格式
Replica Set:K8S集群中保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RS就会启动运行新的Pod副本;多于指定数目,RS就会杀死多余的Pod副本。即使在指定数目为1的情况下,通过RS运行Pod也比直接运行Pod更明智,因为RS也可以发挥它高可用的能力,保证永远有1个Pod在运行。RS适用于长期伺服型的业务类型,比如提供高可用的Web服务。
Pod是有声明周期的,随时都会有旧的离去,新的加进来,加入他们都是同一种服务,这时候客户端是没法固定的访问Pod的。因为Pod本身就是不固定的,随时可能被替换掉,无论是主机名或者是IP地址都随时会被替换掉。这时候就需要用到服务发现机制了。为了尽可能降低二者之间的复杂度,所以他中间就需要有一个service层,service层只要不删除,它的地址是固定的,名称也是固定的。客户端连接service层,只需要在配置文件中写明服务的地址或名称就行。这个服务还能起到调动的功能。然后服务代理到Pod。客户端看见的至始至终都是service端的地址,看不到Pod的地址。在K8s上service可不是一个应用程序,也不是实体组件,它是iptables的DNAT规则。其实也就是所有到达某个地址的都统统被目标地址转换成XXX地址。没有绑在网卡上,但是能被ping通。service名称也可以被解析,需要在K8S中部署一个DNS的Pod。DNS解析的是service层的地址。
因为service层连接后端的Pod(docker),不是靠的IP地址和主机名加端口的方式,是通过标签(Label)的方式来识别新起的Pod。连接以后再动态探测Pod的IP地址。每一个软件都有一个service层,例如NMT环境,NGINX就有单独的service层,Tomcat有自己单独的service层。MySQL也有自己的service层。每个服务都有自己的控制器Controller,会根据标签控制Pod的数量。
因为service层是通过iptables的DNAT规则来访问后端的Pod的,但是iptables是负载均衡是ipvs负责的。如果后端有很多的Pod的话,就以为着DNAT是多目标的。因此在调度效果上不太如任意,在1.11版本当中已经把iptables规则改成了ipvs规则。每个service都是ipvs规则,是NAT型的。
控制器Controller怎么去识别自己的Pod够不够呢?是通过标签来决定的。
定义一个NGINX的Pod控制器,控制器会自动创建相关的Pod。
service层需要手动创建。
service有两种类型:
1、创建以后,只供K8S内部使用Pod客户端所访问
2、也可以提供K8S外部的集群客户端所访问
AddOns: 附件 (DNS)
监控的话可以用普罗米修斯+grafana
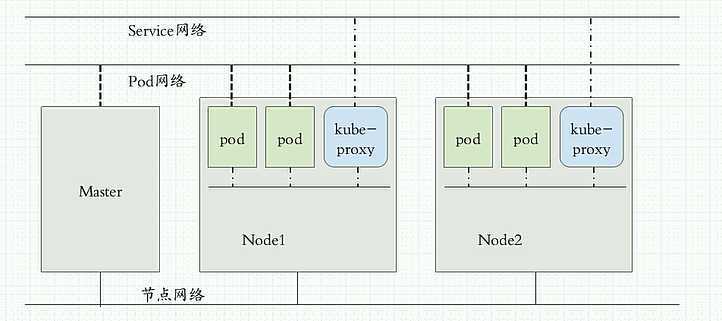
K8S集群网络模型有3种:
1、每个Pod运行在同一个网络中。称为Pod网络
2、service层运行在另外一个网络,和Pod是在不同网段的地址。是假的地址,存在iptables 或 ipvs 的规则之中。被称为集群网络
3、各节点的网段也是一个单独的网络。称为节点网络。
外部访问时先经过节点网络,节点网络代理至集群网络,再由集群网络代理至Pod网络。
Pod和Pod怎么通信?
• 同一个Pod内的多个容器间: lo 本地接口
• 各Pod之间的通信: 通过Overlay Network 叠加网络。
• Pod与Service之间的通信: 把报文指向网关
集群中API Server的信息都存储在 etcd 分布式文件存储中。因此etcd需要布置一个集群。
etcd需要跟内部通信,还要跟API Server通信,API Sserver也需要跟其他node通信,所以需要很多套CA加密证书。但是K8S不提供证书,需要安装插件。
K8S不提供网络,运行Pod得提供网络管理功能,需要通过第三方插件来实现。通过CNI:网络容器接口就可以实现管理K8S网络功能。
CNI:
flannel : 网络配置,不支持网络策略 部署易 叠加网络
calico : 网络配置,网络策略 部署难 三层隧道网络
canel : 结合上面两个的功能

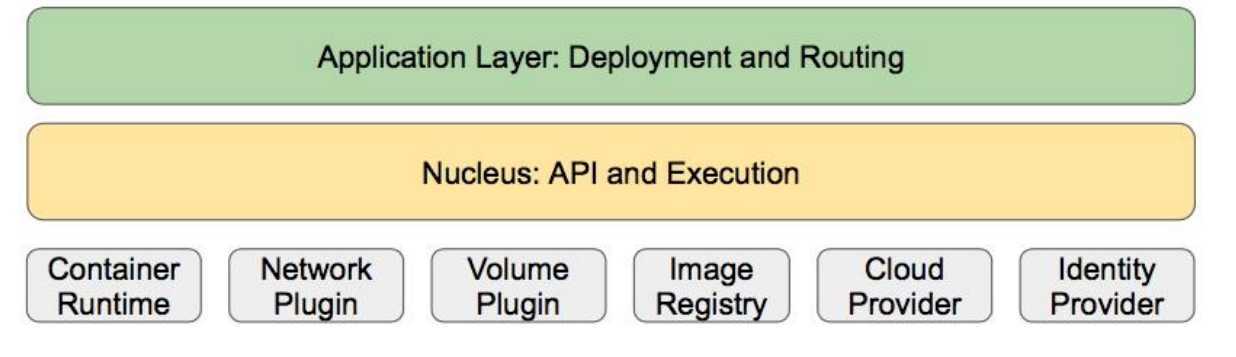
1. 核心层:K8S最核心的功能,对外提供API构建高层的应用,堆内提供插件式应用执行环境
2. 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等) 和路由 (服务发现、DNS解析等)
3. 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等) 以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
4. 接口层:kubectl命令行工具、客户端SDK以及集群联邦
5. 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
K8S 架构设计的优缺点:优点
1、容错性:保证K8S系统稳定性和安全性的基础
2、易扩展性:保证K8S对变更友好,可以快速迭代增加新功能的基础。
API分版本,API可自由扩展(CRD)
插件化,调度器,容器运行时,存储均可扩展
3、声明式 (Declarative) 的而不是命令式 (Imperative):
声明式操作在分布式系统中的好处是稳定,不怕丢操作或运行多次,例如设置副本数为3的操作运行多次也还是一个结果,而给副本数加1的操作就不是声明式的,运行多次结果就错了。
K8S 架构设计的优缺点:缺点
1、配置中心化:所有状态都保存在中心的etcd上,而非分布式存储,性能有一定制约
2、单体调度:调度一致性好而吞吐低
标签:bec 信息 策略 flannel iptable 指定 友好 tab web服务
原文地址:https://www.cnblogs.com/green-frog-2019/p/11527726.html