标签:iterable linked 有关 不同的 prope tor 之间 的区别 exception
先来一张 集合 的"家庭照"
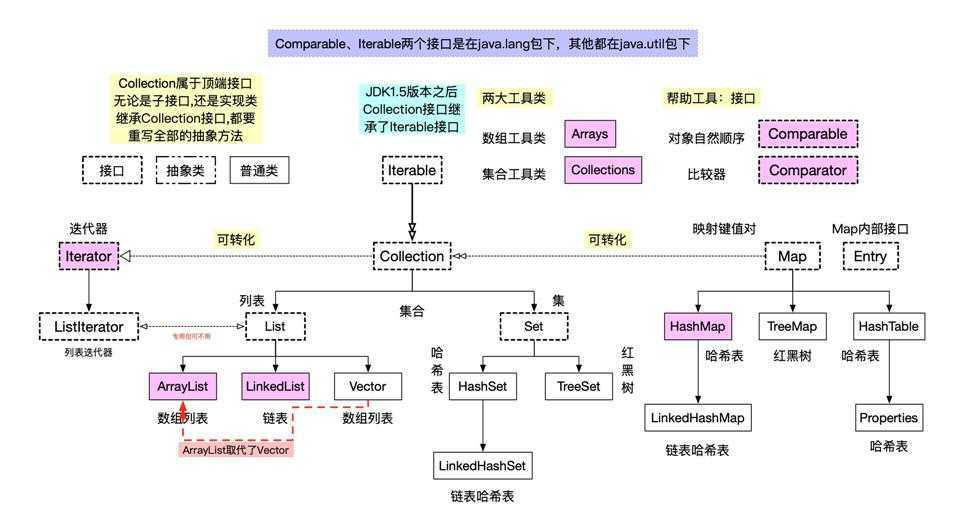
Collection是一个接口,所有其子类(也是接口)需要重写其全部的方法!
特别说明:
Collection 和 Collections 长的太像了,容易混淆,这里就特别说明下:
Collection 是集合的顶级接口(Iterable是JDK1.5新增),其定义了一些必要方法。如下:
|-- iterator //获取集合迭代器对象
|-- size //获取集合长度
|-- add //添加集合元素
|-- addAll //添加集合元素
|-- remove //删除集合元素
|-- removeAll //删除集合元素
|-- clear //清空集合元素
|-- contains //判断集合中是否包含某个元素
|-- containsAll //判断集合中是否包含某个元素
|-- isEmpty //判断集合是否有元素
|-- equals //判断两个集合是否相等
|-- retainAll //获取两个集合中相同的元素,存到调用者的容器中,相当于:替换调用者原来的元素
|-- hashCode //获取集合哈希码值
|-- toArray // 获取集合迭代器对象Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。
此类不能实例化。就像一个工具类,服务于Java的Collection框架。常用方法说明如下:
|-- sort(List<T> list) //对 List集合进行排序(默认的是升序排列)(不适用与 Set集合)
|-- sort(List<T> list, Comparator<? super T> c) //对 List集合进行排序(可以传递自定义的比较器)(不适用与 Set集合)
|-- shuffle(List<?> list) // 对 List 集合中的元素进行随机排列
|-- binarySearch(List<? extends T> list, T key) //折半查找
|-- reverse(List<?> list) //反转 List 集合
|-- reverseOrder() //逆转对象的自然顺序 或 比较器栈:数据 先进 后出
队列:数据 先进 先出
数组:按照索引进行存储
链表:存储数据,按照地址的记录方式存储(前面记住后面的 或 后面记住前面的 依次类推)
树:存储的数据在容器中像树结构那样,对象可以排序 (红黑树)
哈希表:存储对象依赖对象的哈希值
迭代步骤
迭代的两种方式
HashMap<String, Integer> map = new HashMap<>();
//获取所有的键'key', 存储到 Set 集合中
Set<String> keys = map.keySet();
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
Integer value = map.get(key);
}HashMap<String, String> map = new HashMap<>();
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
String key = entry.getKey();
String value = entry.getValue();
}迭代说明
//错误代码如示:
while (iterator.hasNext()) {
System.out.println(iterator.next()+"..."+map.get(iterator.next()));
}迭代原理
Collection 集合的每个实现类, 其内部是不同的。故而对于每个集合子类, 它们存储对象的方式是不同的。每个集合子类中定义一个内部类(Itr)去实现 Iterator 接口并重写方法, 各自实现查询、获取的操作。
//以 ArrayList 为列,其内部重写了 Collection 的方法 iterator()
//并返回实现了 Iterator 接口的内部类对象
public Iterator<E> iterator() {
return new Itr();
}
/************************************************************/
//Java Iterator 接口源码中: 4个方法 (能看到的只有4个)
public interface Iterator<E> {
//查找集合中是否还有下一个元素,有则返回true, 没有返回false
boolean hasNext();
//返回集合中的下一个元素
E next();
//遍历过程中,移除集合中的元素
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}数组:Array
集合:ArrayList
标签:iterable linked 有关 不同的 prope tor 之间 的区别 exception
原文地址:https://www.cnblogs.com/io1024/p/11532696.html